Trasformatore
Un modello trasformatore è un tipo di rete neurale specificamente progettato per gestire dati sequenziali, come testo, parlato o dati temporali. A differenza de...
3 min di lettura
Transformer
Neural Networks
+3
I transformer sono reti neurali rivoluzionarie che sfruttano la self-attention per l’elaborazione parallela dei dati, alimentando modelli come BERT e GPT in NLP, visione artificiale e oltre.
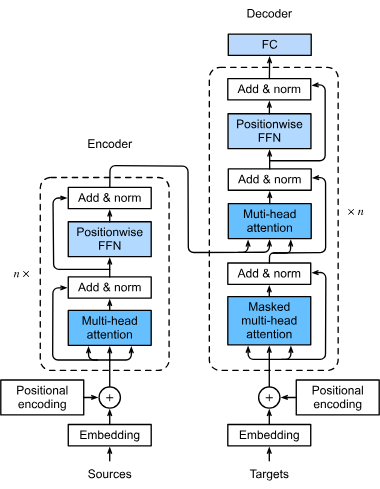
Il primo passo nel flusso di elaborazione di un modello transformer consiste nel convertire le parole o i token di una sequenza di input in vettori numerici, noti come embeddings. Questi embeddings catturano i significati semantici e sono fondamentali per permettere al modello di comprendere le relazioni tra i token. Questa trasformazione è essenziale perché consente al modello di elaborare i dati testuali in forma matematica.
I transformer non elaborano i dati in modo sequenziale per natura; perciò viene utilizzato il positional encoding per inserire informazioni sulla posizione di ciascun token nella sequenza. Ciò è vitale per mantenere l’ordine della sequenza, fondamentale per compiti come la traduzione automatica dove il contesto dipende dalla sequenza delle parole.
Il meccanismo di multi-head attention è una componente sofisticata dei transformer che permette al modello di concentrarsi su diverse parti della sequenza di input simultaneamente. Calcolando molteplici punteggi di attenzione, il modello può cogliere varie relazioni e dipendenze nei dati, migliorando la sua capacità di comprendere e generare schemi complessi.
I transformer seguono tipicamente un’architettura encoder-decoder:
Dopo il meccanismo di attention, i dati passano attraverso reti neurali feedforward, che applicano trasformazioni non lineari ai dati aiutando il modello ad apprendere schemi complessi. Queste reti elaborano ulteriormente i dati per perfezionare l’output generato.
Queste tecniche vengono incorporate per stabilizzare e velocizzare il processo di addestramento. La normalizzazione di strato garantisce che le uscite restino entro un certo intervallo, facilitando l’addestramento efficiente del modello. Le connessioni residuali permettono ai gradienti di fluire attraverso le reti senza svanire, migliorando l’addestramento di reti neurali profonde.
I transformer operano su sequenze di dati, che possono essere parole in una frase o altre informazioni sequenziali. Applicano la self-attention per determinare la rilevanza di ciascuna parte della sequenza rispetto alle altre, consentendo al modello di concentrarsi sugli elementi cruciali che influenzano l’output.
Nella self-attention, ogni token della sequenza viene confrontato con ogni altro token per calcolare i punteggi di attenzione. Questi punteggi indicano l’importanza di ciascun token nel contesto degli altri, permettendo al modello di focalizzarsi sulle parti più rilevanti della sequenza. Ciò è fondamentale per comprendere il contesto e il significato nei compiti linguistici.
Questi sono i mattoni fondamentali di un modello transformer, costituiti da layer di self-attention e feedforward. Più blocchi vengono impilati per formare modelli deep learning in grado di cogliere schemi complessi nei dati. Questo design modulare consente ai transformer di scalare efficientemente con la complessità del compito.
I transformer sono più efficienti di RNN e CNN grazie alla loro capacità di elaborare intere sequenze in una sola volta. Questa efficienza consente di scalare verso modelli molto grandi, come GPT-3, che conta 175 miliardi di parametri. La scalabilità dei transformer permette loro di gestire efficacemente enormi quantità di dati.
I modelli tradizionali hanno difficoltà con le dipendenze a lungo raggio a causa della loro natura sequenziale. I transformer superano questo limite grazie alla self-attention, che può considerare tutte le parti della sequenza simultaneamente. Questo li rende particolarmente efficaci per compiti che richiedono la comprensione del contesto su lunghe sequenze di testo.
Sebbene inizialmente progettati per compiti di NLP, i transformer sono stati adattati per diverse applicazioni, compresa la visione artificiale, il folding delle proteine e persino il forecasting di serie temporali. Questa versatilità dimostra la vasta applicabilità dei transformer in diversi settori.
I transformer hanno migliorato notevolmente le prestazioni nei compiti di NLP come traduzione, riassunto e analisi del sentiment. Modelli come BERT e GPT sono esempi di primo piano che sfruttano l’architettura transformer per comprendere e generare testo simile a quello umano, fissando nuovi standard nel settore NLP.
Nella traduzione automatica, i transformer eccellono comprendendo il contesto delle parole in una frase, permettendo traduzioni più accurate rispetto ai metodi precedenti. La loro capacità di elaborare intere frasi contemporaneamente consente traduzioni più coerenti e contestualmente corrette.
I transformer possono modellare le sequenze di amminoacidi nelle proteine, aiutando nella previsione delle strutture proteiche, fondamentale per la scoperta di nuovi farmaci e la comprensione dei processi biologici. Questa applicazione sottolinea il potenziale dei transformer nella ricerca scientifica.
Adattando l’architettura transformer, è possibile prevedere valori futuri in dati di serie temporali, come la previsione della domanda di elettricità, analizzando le sequenze passate. Questo apre nuove possibilità per i transformer in settori come la finanza e la gestione delle risorse.
I modelli BERT sono progettati per comprendere il contesto di una parola osservando le parole circostanti, rendendoli molto efficaci per compiti che richiedono la comprensione delle relazioni tra le parole in una frase. Questo approccio bidirezionale consente a BERT di cogliere il contesto più efficacemente rispetto ai modelli unidirezionali.
I modelli GPT sono autoregressivi e generano testo predicendo la parola successiva di una sequenza in base alle parole precedenti. Sono ampiamente utilizzati in applicazioni come il completamento del testo e la generazione di dialoghi, dimostrando la loro capacità di produrre testo simile a quello umano.
Inizialmente sviluppati per l’NLP, i transformer sono stati adattati per compiti di visione artificiale. I vision transformer elaborano i dati delle immagini come sequenze, consentendo loro di applicare le tecniche transformer anche agli input visivi. Questa adattazione ha portato a progressi nel riconoscimento e nell’elaborazione delle immagini.
L’addestramento di grandi modelli transformer richiede notevoli risorse computazionali, spesso coinvolgendo enormi dataset e hardware potenti come le GPU. Questo rappresenta una sfida in termini di costi e accessibilità per molte organizzazioni.
Con la diffusione dei transformer, questioni come il bias nei modelli di IA e l’uso etico dei contenuti generati dall’IA stanno diventando sempre più rilevanti. I ricercatori stanno lavorando su metodi per mitigare questi problemi e garantire uno sviluppo responsabile dell’IA, evidenziando la necessità di strutture etiche nella ricerca sull’IA.
La versatilità dei transformer continua ad aprire nuove strade di ricerca e applicazione, dal potenziamento dei chatbot basati su IA al miglioramento dell’analisi dei dati in ambiti come sanità e finanza. Il futuro dei transformer offre possibilità entusiasmanti di innovazione in vari settori.
In conclusione, i transformer rappresentano un progresso significativo nella tecnologia dell’IA, offrendo capacità senza precedenti nell’elaborazione dei dati sequenziali. La loro architettura innovativa ed efficienza hanno fissato un nuovo standard nel settore, portando le applicazioni dell’IA a nuovi livelli. Che si tratti di comprensione linguistica, ricerca scientifica o elaborazione di dati visivi, i transformer continuano a ridefinire ciò che è possibile nel campo dell’intelligenza artificiale.
I transformer hanno rivoluzionato il campo dell’intelligenza artificiale, in particolare nell’elaborazione del linguaggio naturale e nella comprensione, favorendo l’interazione uomo-macchina. L’articolo “AI Thinking: A framework for rethinking artificial intelligence in practice” di Denis Newman-Griffis (pubblicato nel 2024) esplora un nuovo quadro concettuale chiamato AI Thinking. Questo framework modella le decisioni chiave e le considerazioni nell’uso dell’IA attraverso prospettive disciplinari, affrontando le competenze nella motivazione dell’uso dell’IA, nella formulazione dei metodi e nella collocazione dell’IA nei contesti sociotecnici. Mira a colmare le divisioni tra le discipline accademiche e a rimodellare il futuro dell’IA nella pratica. Leggi di più.
Un altro contributo significativo è rappresentato da “Artificial intelligence and the transformation of higher education institutions” di Evangelos Katsamakas et al. (pubblicato nel 2024), che utilizza un approccio di sistemi complessi per mappare i meccanismi di feedback causale della trasformazione dell’IA nelle istituzioni di istruzione superiore (HEI). Lo studio discute le forze che guidano la trasformazione dell’IA e il suo impatto sulla creazione di valore, sottolineando la necessità per le HEI di adattarsi ai progressi tecnologici dell’IA gestendo allo stesso tempo integrità accademica e cambiamenti occupazionali. Leggi di più.
Nel campo dello sviluppo software, l’articolo “Can Artificial Intelligence Transform DevOps?” di Mamdouh Alenezi e colleghi (pubblicato nel 2022) esamina l’intersezione tra IA e DevOps. Lo studio evidenzia come l’IA possa migliorare la funzionalità dei processi DevOps, facilitando una consegna del software più efficiente. Sottolinea le implicazioni pratiche per gli sviluppatori e le aziende nell’usare l’IA per trasformare le pratiche DevOps. Leggi di più
I transformer sono un'architettura di rete neurale introdotta nel 2017 che utilizza meccanismi di self-attention per l'elaborazione parallela di dati sequenziali. Hanno rivoluzionato l'intelligenza artificiale, in particolare nell'elaborazione del linguaggio naturale e nella visione artificiale.
A differenza di RNN e CNN, i transformer elaborano tutti gli elementi di una sequenza simultaneamente utilizzando la self-attention, consentendo maggiore efficienza, scalabilità e la capacità di catturare dipendenze a lungo raggio.
I transformer sono ampiamente utilizzati in compiti di NLP come traduzione, riassunto e analisi del sentiment, oltre che in visione artificiale, previsione della struttura delle proteine e forecasting di serie temporali.
Modelli transformer di rilievo includono BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) e Vision Transformers per l'elaborazione delle immagini.
I transformer richiedono risorse computazionali significative per l'addestramento e il deployment. Sollevano anche considerazioni etiche come il potenziale bias nei modelli di IA e l'uso responsabile dei contenuti generati dall'IA.
Chatbot intelligenti e strumenti AI sotto lo stesso tetto. Collega blocchi intuitivi per trasformare le tue idee in Flussi automatizzati.
Un modello trasformatore è un tipo di rete neurale specificamente progettato per gestire dati sequenziali, come testo, parlato o dati temporali. A differenza de...
Long Short-Term Memory (LSTM) è un tipo specializzato di architettura di Reti Neurali Ricorrenti (RNN) progettata per apprendere dipendenze a lungo termine nei ...
Una rete neurale, o rete neurale artificiale (ANN), è un modello computazionale ispirato al cervello umano, essenziale nell'IA e nell'apprendimento automatico p...