

LangChain
LangChainは、オープンソースのフレームワークであり、OpenAIのGPT-3.5やGPT-4などの強力な大規模言語モデル(LLM)と外部データソースを連携し、高度なNLPアプリケーションを構築するための統合を簡素化します。...
1 分で読める
LangChain
LLM
+4
2026年における主要なLangChain代替品の比較は以下のとおりです:
| ツール | タイプ | 最適な用途 | Python必須 | 自己ホスト | 価格 |
|---|---|---|---|---|---|
| FlowHunt | ノーコードプラットフォーム | 完全なエージェントプラットフォーム、最速の本番化 | いいえ | いいえ | 無料ティア+従量課金 |
| LlamaIndex | Pythonフレームワーク | RAG、ドキュメント集約的なエージェント | はい | 該当なし | 無料(OSS) |
| Dify | ローコード+OSS | ビジュアルLLMOps、自己ホスティング | オプション | はい | 無料/クラウド |
| Flowise | ビジュアル+OSS | コードなしのLangChainフロー | いいえ | はい | 無料/クラウド |
| CrewAI | Pythonフレームワーク | マルチエージェントのロールベースシステム | はい | 該当なし | 無料(OSS) |
| AutoGen | Pythonフレームワーク | 会話型マルチエージェント | はい | 該当なし | 無料(OSS) |
| Haystack | Pythonフレームワーク | 本番NLP/RAGパイプライン | はい | 該当なし | 無料(OSS) |
| Semantic Kernel | SDK(.NET/Python/Java) | エンタープライズMicrosoftエコシステム | はい | 該当なし | 無料(OSS) |
LangChainは2022年後半にローンチされ、LLM駆動アプリケーションを構築するためのデフォルトフレームワークとしてすぐに普及しました。チェーン、エージェント、メモリ、ツール、リトリーバー、出力パーサーなど、現在この分野全体が使用している概念を導入しました。しばらくの間、GPT-4やClaudeで本格的なものを構築する唯一の構造化された方法でした。
しかし、フレームワークが成長するにつれて、その問題も大きくなりました。2025年までに、LangChainは3つのことで悪名高くなりました:
破壊的変更。 マイナーバージョンアップが定期的に本番アプリケーションを壊します。チームは固定された依存関係を維持し、恐れからアップグレードを数ヶ月間見送ります — これは時間とともに積み重なる保守負担です。
抽象化の過負荷。 LangChainはすべてを抽象化の層(Runnable、LCEL、BaseChatModel、BaseRetriever)でラップするため、コードが読みにくく、デバッグしにくく、チームメイトに説明しにくくなります。直接APIコールであれば30行で済むシンプルなRAGパイプラインが、チェーンされたLangChainオブジェクトの150行になります。
シンプルなタスクのオーバーヘッド。 「ドキュメントを読むチャットボットを構築する」という、午後だけで終わるはずのタスクが、LangChainの学習曲線、デバッグセッション、プロンプトエンジニアリングを考慮すると数日かかります。フレームワークは、それ以前には存在しなかった摩擦を導入します。
これらはLangChainが悪いという意味ではありません。強力で、十分に文書化されており、広くサポートされています。しかし2026年には、ほとんどのユースケースにとってより良い選択肢があります — よりシンプルなフレームワーク、ビジュアルプラットフォーム、そしてオーバーヘッドなしで同じ問題を解決する本番対応の代替品です。
価格: LangChain(オープンソースライブラリ)はMITライセンスの下で無料です — プロジェクトでの使用に費用はかかりません。LangSmith(オブザーバビリティとテストのプラットフォーム)は以下を提供します:
主な機能:
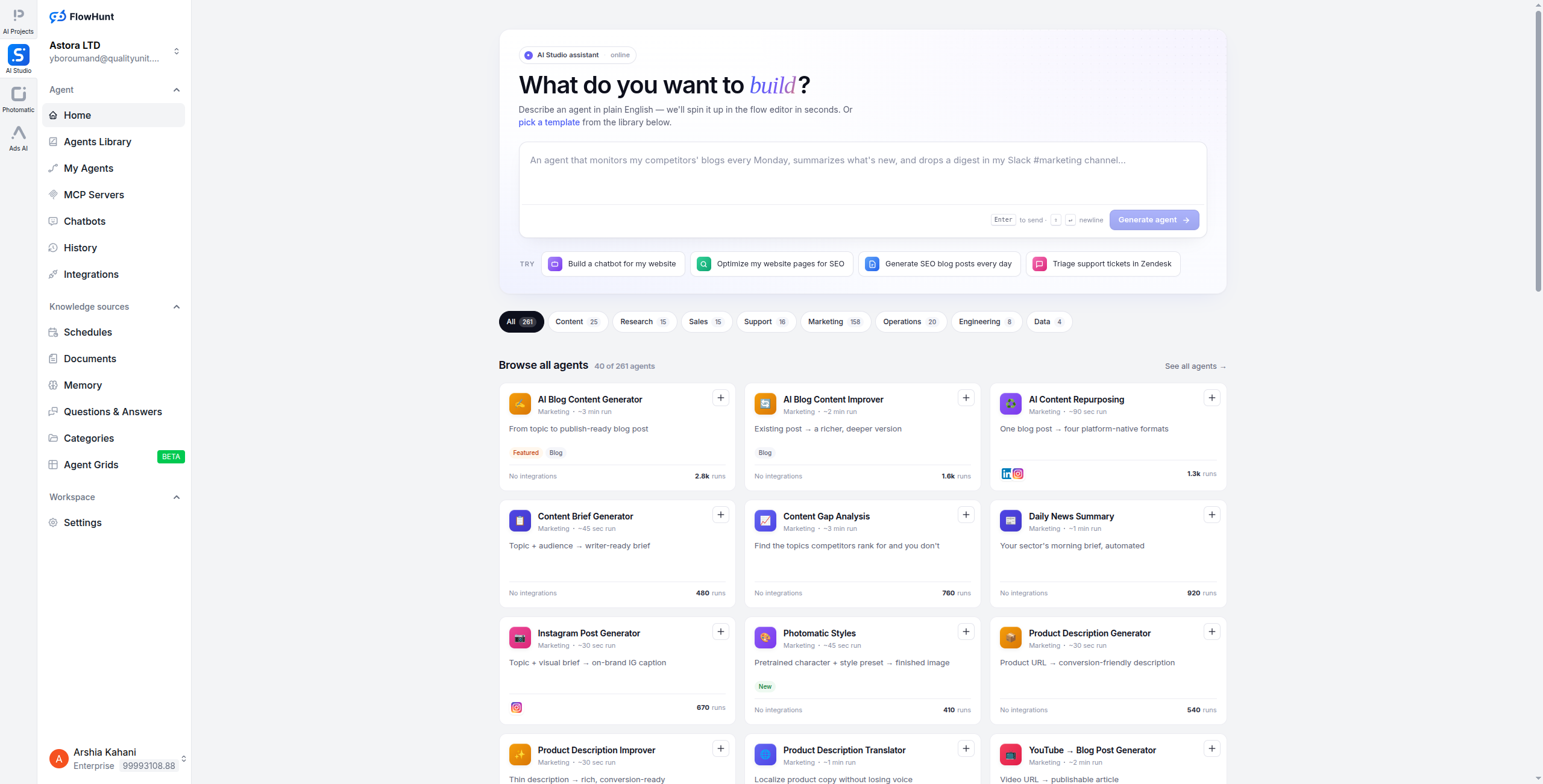
FlowHuntは、Pythonパッケージのバージョン、LCEL構文、ボイラープレート設定に苦労することなく、AIエージェントを素早く出荷したいチームにとって最も完全なLangChain代替品です。LangChainのスタック全体(モデルルーティング、ツール呼び出し、RAG、メモリ、エージェントオーケストレーション)を、ブラウザで実行されるビジュアルドラッグアンドドロップビルダーに置き換えます。
LangChainではメモリとツール使用を備えたRAGエージェントを配線するのに数百行のPythonが必要ですが、FlowHuntでは「ベクトル検索」ノードをドラッグして、システムプロンプトを持つLLMノードに接続し、メモリブロックを追加して、1時間以内にデプロイできます。同じエージェントが、チャットウィジェット、APIエンドポイント、Slack、メールにわたって動作します — 追加の統合コードは必要ありません。
FlowHuntはすべての主要なLLM(GPT-4o、Claude 3.5、Gemini 1.5、Mistral、Llama 3)をサポートし、1,400以上の事前構築された統合を持ち、組み込みのモニタリング、バージョン管理、チームコラボレーションツールを備えています。本当にエンタープライズ対応です:SOC 2準拠で、RBACと監査ログを備えています。
価格:
主な機能:
長所: コード不要、最速の本番化、組み込みRAGとメモリ、1,400以上の統合、エンタープライズ対応
短所: 高度にカスタムなエージェントロジックに対してはPythonフレームワークほどの生の柔軟性はない。クラウドデプロイが必要(現在は自己ホストオプションなし)
最適な用途: フレームワーク保守のオーバーヘッドなしに本番エージェントを求めるビジネスチーム、プロダクトチーム、開発者。
関連項目:より広範なプラットフォーム比較については2026年の最高AIエージェントビルダー をご覧ください。
LlamaIndex(旧GPT Index)は、ある1つのことのために特別に構築されました:LLMをデータに接続すること。完全なエージェントフレームワークへと進化しましたが、その中核的な強みは依然としてドキュメントのインデックス作成、検索、クエリエンジンの構築です — これらはすべてLangChainの抽象化が扱いにくく感じる領域です。
LangChainのリトリーバー抽象化が詳細を隠しすぎる一方で、LlamaIndexはチャンキング戦略、埋め込みモデルの選択、類似度メトリクス、再ランキングを明示的に制御できます。そのQueryEngineとRouterQueryEngineにより、複数のデータソースにわたって質問をルーティングするのが簡単になります — これはLangChainでは大幅なカスタム作業を要するものです。
LlamaIndexはまた、よりクリーンな非同期サポートと、LlamaTrace(現在のArize Phoenix)のようなオブザーバビリティツールとのより良い統合を備えており、本番エージェントのデバッグを容易にします。
価格: LlamaIndex(オープンソースライブラリ)はMITライセンスの下で無料です。LlamaCloud(マネージドクラウドサービス)は以下を提供します:
主な機能:
長所: クラス最高のドキュメント処理とRAG、LangChainより洗練された抽象化、優れた非同期サポート、強力なコミュニティ
短所: 非RAGユースケースではLangChainより幅が狭い、依然としてPythonの熟練が必要、統合エコシステムが小さい
最適な用途: ドキュメントQ&Aシステム、リサーチアシスタント、ナレッジベースエージェント、またはデータ検索品質が重要なあらゆるアプリケーションを構築する開発者。
Difyは、LangChainのプログラム的モデルにビジュアルファーストのアプローチを取るオープンソースのLLMOpsプラットフォームです。プロンプトテンプレート、検索チェーン、エージェントワークフローを定義するためにPythonを書く代わりに、ブラウザベースのオーケストレーションスタジオでそれらを構成します。
Difyには、ドキュメントアップロード、チャンキング、埋め込み、検索構成を備えた完全なRAGパイプラインビルダーが含まれています — コード不要です。また、マルチステップのエージェント型フロー用のワークフローエディタ、プロンプト管理システム、そしてアプリケーションロジックを一切変更せずにOpenAI、Anthropic、Cohere、ローカルモデルを切り替えられるモデルプロバイダースイッチャーも備えています。
完全にオープンソース(MITライセンス)でDockerデプロイ可能なため、Difyはデータプライバシーやコンプライアンスの理由で自己ホスティングを必要とするチームに人気があります。dify.aiのクラウド版は無料で始められます。
価格:
主な機能:
長所: オープンソースで自己ホスト可能、ビジュアルプロンプトオーケストレーション、組み込みRAGパイプライン、モデル非依存、活発なコミュニティ
短所: 複雑なカスタムロジックには純粋なPythonほど柔軟ではない、クラウド版には使用制限がある、ドキュメントが新機能に遅れることがある
最適な用途: ベンダーロックインなしのビジュアルLLMオーケストレーションを求める開発チーム、またはSaaSプラットフォームを除外するデータプライバシー要件を持つチーム。
LangChainの概念は好きだがLangChainコードを書くのは嫌いなら、Flowiseが答えです。ドラッグアンドドロップコンポーネントからLangChainフローを生成するオープンソースで自己ホスト可能なビジュアルビルダーです — つまり、Pythonを1行も書かずに、LangChainエコシステム全体(ドキュメントローダー、ベクトルストア、メモリタイプ、ツール統合)を手に入れられます。
Flowiseには活発なコミュニティフローのマーケットプレイスがあり、そのノードライブラリはすべての主要なLangChainコンポーネントをカバーしています:ChatOpenAI、ConversationalRetrievalChain、AgentExecutor、PineconeVectorStoreなど。基盤となるLangChain JSONを公開しているため、ビジュアル編集だけでは不十分な場合に、パワーユーザーは任意のノードをカスタムコードで拡張できます。
価格:
主な機能:
長所: コードなしの真のLangChain互換性、自己ホスト可能、活発なコミュニティ、フローの共有とバージョン管理が容易
短所: LangChainのリリースサイクルに縛られる(バージョンの不安定性を継承)、複雑なオーケストレーションパターンではDifyより制限される、UIが商用代替品ほど洗練されていない
最適な用途: ビジュアルに移行したいLangChainユーザー、本番化の前にLangChainエージェントを素早くプロトタイプしたいチーム。
CrewAIは異なるメンタルモデルを導入します:チェーンやツールの代わりに、それぞれが名前、ロール、目標、バックストーリーを持つAIエージェントの「クルー」を定義します。クルーは定義されたプロセス(順次または階層的)を通じてタスクで協力し、エージェントはそれぞれのロールに基づいて互いに作業を委任します。
このロールベースのパターンは、実世界のチームワークフローに自然にマッピングされます — 情報を見つける「リサーチエージェント」、それを統合する「ライターエージェント」、そして配信前に出力をチェックする「QAエージェント」。CrewAIはエージェント間の通信、メモリ共有、タスク委任を自動的に処理します。
CrewAIはマルチエージェントのユースケースにおいてLangChainより大幅に軽量で、はるかに少ないボイラープレートで済みます。その抽象化は直感的なので、LangChainを使ったことのない開発者でも素早く習得できます。
価格:
主な機能:
長所: 直感的なロールベースのマルチエージェントモデル、軽量、素早いセットアップ、パイプライン型のマルチエージェントワークフローに優れている
短所: 非クルーパターンには柔軟性が低い、LangChainより小さい統合エコシステム、Pythonが必要、初期段階のオブザーバビリティツール
最適な用途: リサーチパイプライン、コンテンツ作成ワークフロー、または明確なロールを持つ並列エージェントを含むあらゆるユースケースを構築する開発者。
MicrosoftのAutoGenフレームワークは会話型エージェントパターンを中心にしています — エージェントが対話を通じてタスクを完了するために互いに(そして人間と)話します。その「GroupChat」とネストされた会話パターンは、リサーチタスク、コード生成、そしてエージェント間の議論と修正から恩恵を受けるあらゆるワークフローに強力です。
AutoGenの人間のループ設計は真の差別化要因です:会話の任意の時点で人間のフィードバックを注入できるため、完全な自律性が適切でない高リスクのワークフローに適しています。また、強力なコード実行機能を備えており、エージェントが反復的にコードを書き、実行し、デバッグできます。
価格: AutoGen(オープンソースフレームワーク)はMITライセンスの下で無料で、使用料はかかりません。AutoGen Studio(AutoGenエージェントを構築・テストするためのビジュアルインターフェース)も無料でオープンソースです。エンタープライズデプロイの場合、Microsoft Azure AIがAzure価格ティア内でマネージドAutoGenインフラを提供します。
主な機能:
長所: 優れた会話型マルチエージェントパターン、強力な人間のループサポート、Microsoftの支援、組み込みのコード実行
短所: 会話型パターンはすべてのユースケースに適合しない、CrewAIより急な学習曲線、シンプルなパイプラインには冗長
最適な用途: リサーチ自動化、コード生成エージェント、中間ステップで人間のレビューを必要とするワークフロー、そしてMicrosoftエコシステムのエンタープライズチーム。
deepsetによるHaystackは本番向けに構築されています。LangChainがしばしば研究から本番への移行の頭痛の種であるのに対し、Haystackは信頼性、モジュール性、エンタープライズデプロイのためにゼロから設計されています。そのパイプライン抽象化は、型付き入力/出力を持つ明示的なコンポーネントグラフを使用し、統合エラーを実行時ではなくビルド時に捕捉します。
Haystackはドキュメント処理、ハイブリッド検索(疎+密検索)、質問応答、生成型QAパイプラインに優れています。その評価フレームワーク(Haystack Evaluation)により、検索品質とLLM出力品質を体系的に測定するのが簡単になります — 本番システムにとって重要な機能です。

価格: Haystack(オープンソースフレームワーク)はApache 2.0ライセンスの下で無料です。deepset Cloud(Haystack上に構築されたマネージドエンタープライズプラットフォーム)は以下を提供します:
主な機能:
長所: 本番グレードの信頼性、型付きパイプラインコンポーネント、優れた評価ツール、強力なドキュメント処理、十分な文書化
短所: LangChainよりも独断的(新しいパターンには柔軟性が低い)、初心者にとって重い学習曲線、小さいエコシステム
最適な用途: 初日から信頼性、テスト容易性、評価メトリクスを必要とする本番RAG/QAシステムを構築するエンタープライズチーム。
Semantic Kernelは、LLMをエンタープライズアプリケーションに埋め込むためのMicrosoftのSDKです。Pythonファーストのフレームワークとは異なり、.NET(C#)、Python、Javaを同等にサポートします — 本番スタックが.NETであるエンタープライズチームにとって唯一の本格的な選択肢になります。
Semantic Kernelは、AIオーケストレーション層として機能する「カーネル」を使用し、LLMに関数を公開する「プラグイン」(LangChainツールに相当)を備えています。そのプランナーコンポーネント(順次、ステップワイズ、handlebars)はマルチステップ推論を自動的に処理します。Azure OpenAI、Azure AI Search、Microsoft 365との深い統合により、すでにMicrosoftクラウドにいるチームにとって自然な選択肢になります。
価格: Semantic KernelはMITライセンスの下で無料かつオープンソースです — SDK自体に費用はかかりません。コストは、Semantic Kernelアプリケーション内で使用される基盤となるモデルプロバイダー(Azure OpenAI、OpenAI API)とAzureサービス(Azure AI Search、メモリ用のAzure Cosmos DB)から発生し、標準のAzure料金で請求されます。
主な機能:
長所: マルチ言語SDK(.NET/Python/Java)、深いAzure統合、エンタープライズグレードのメモリとプランニング、Microsoftサポート
短所: Pythonネイティブフレームワークより冗長、Azure中心(Microsoftエコシステム外では有用性が低い)、LangChain/LlamaIndexより小さいコミュニティ
最適な用途: エンタープライズ.NET開発チーム、Azureファーストの組織、そしてMicrosoftインフラ上にCopilotスタイルのアシスタントを構築するチーム。
FlowHuntを選ぶ — フレームワーク保守のオーバーヘッドなしに本番AIエージェントを素早く出荷することが目標なら — 特にチームに非開発者が含まれる場合。
LlamaIndexを選ぶ — 可能な限り最高のRAG品質とデータ検索パフォーマンスが必要で、チームがPythonに慣れている場合。
DifyまたはFlowiseを選ぶ — 自己ホスティングとデータ主権を求め、Pythonコードよりもビジュアルインターフェースを好む場合。
CrewAIを選ぶ — ユースケースが明確なロールを持つ並列エージェント(リサーチ、ライティング、QA、分析)に自然にマッピングされる場合。
AutoGenを選ぶ — 高度な人間のループパターン、または複雑な推論タスク向けの会話型マルチエージェント議論が必要な場合。
Haystackを選ぶ — 本番NLPシステムを構築しており、研究志向のフレームワークに欠ける評価と信頼性のツールが必要な場合。
Semantic Kernelを選ぶ — チームが.NETとAzureに住んでいる場合、またはMicrosoft 365統合を構築している場合。
AI自動化の状況をより広く把握するには、最高のワークフロー自動化ツール と最高のZapier代替品 のガイドをご覧ください。
アルシアはFlowHuntのAIワークフローエンジニアです。コンピュータサイエンスのバックグラウンドとAIへの情熱を持ち、AIツールを日常業務に統合して効率的なワークフローを作り出し、生産性と創造性を高めることを専門としています。

LangChainは、オープンソースのフレームワークであり、OpenAIのGPT-3.5やGPT-4などの強力な大規模言語モデル(LLM)と外部データソースを連携し、高度なNLPアプリケーションを構築するための統合を簡素化します。...

2026年のベストAIエージェントフレームワーク8選を比較 — LangChain、CrewAI、AutoGen、LlamaIndex、Dify、Haystack、Semantic Kernel、FlowHunt。あなたのチームに最適なフレームワークはどれですか?...

2026年の最高のAIエージェントツール12選をランキングとレビューで紹介。ノーコードエージェントビルダーからオープンソースフレームワークまで、チームのAI戦略に最適なプラットフォームを見つけましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.