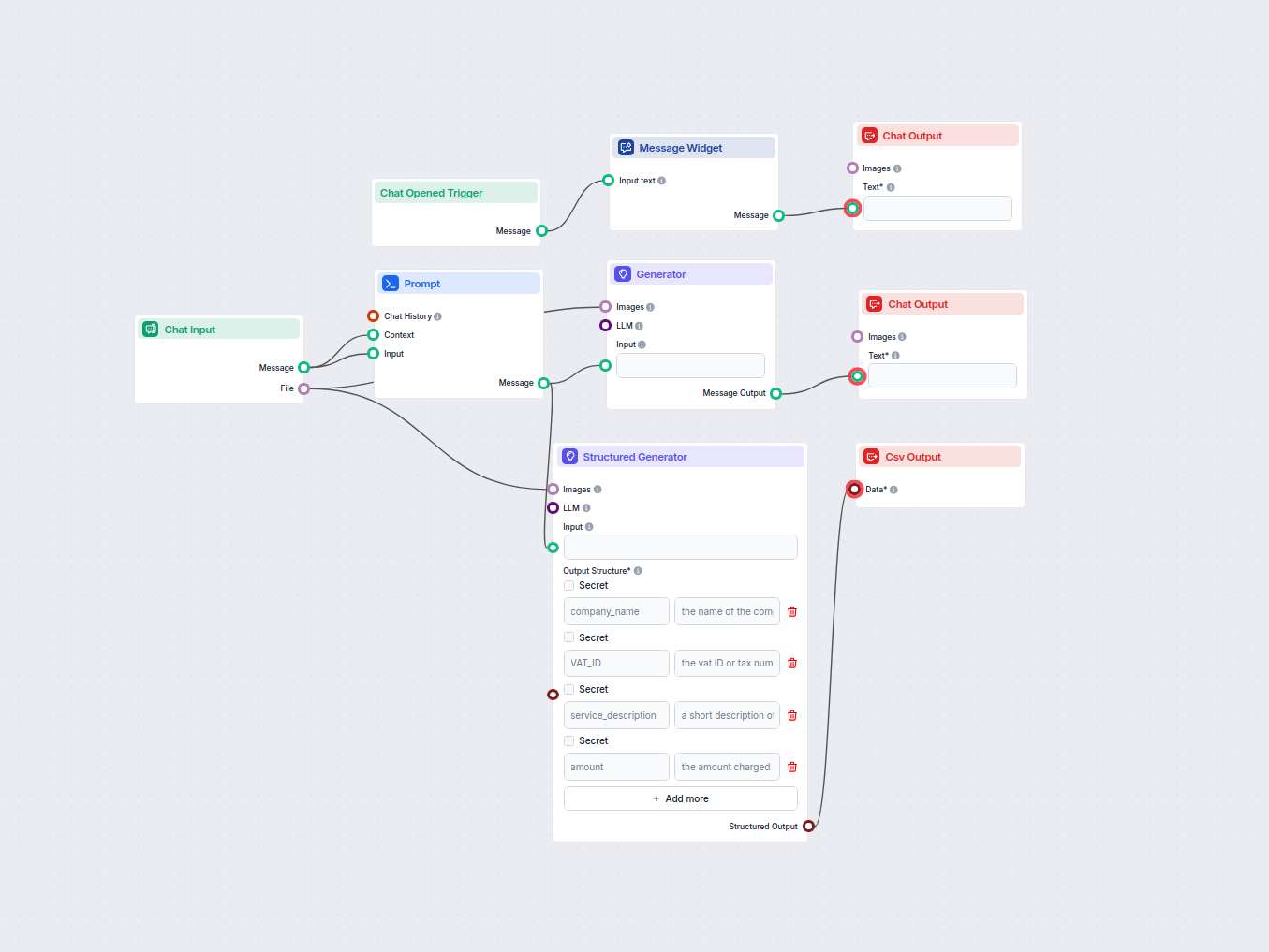
請求書データ抽出ツール
請求書データ抽出OCRフローが、どのように請求書データの自動抽出・整理を通じて財務プロセスを効率化できるかをご紹介します。その特徴やメリット、あらゆる規模の企業における効率性・正確性の向上について学びましょう。詳細はFlowHuntでご覧ください。...
1 分で読める
OCR
Invoice Automation
+3

FlowHuntのAPIとAIベースOCR、Pythonを活用して請求書データ抽出を自動化し、迅速・正確・スケーラブルなドキュメント処理を実現しましょう。
AI駆動のOCRは、従来型のOCRよりも進化しており、人工知能を活用して文脈を理解し、さまざまなレイアウトに対応し、複雑なドキュメントから高品質な構造化データ抽出を実現します。従来のOCRは固定フォーマットのテキスト認識しかできませんが、AI OCRは請求書やビジネス文書に多い多様なレイアウトや構成にも柔軟に対応できます。
請求書は経理・物流・購買などで正確かつ効率的に処理する必要があります。AI OCRはデータ抽出の自動化とワークフローの効率化を実現し、データ精度も向上します。
多くの企業は従来、従業員が手作業で請求書データを抽出していました。これは非常に時間とコストがかかる作業であり、税務・法務・金融など幅広い分野・企業で自動化の余地があります。
このプロセスは5〜15秒程度で完了し、0.01〜0.02クレジットのコストで済みます。従業員が同じ作業を行う場合、時給15〜30ドルが必要です。
| 処理者 | 年間コスト | 年間処理枚数 | 1枚あたりコスト |
|---|---|---|---|
| 人手 | $30,000 | 12,000 | $2.50 |
| FlowHunt | $162 | 12,000 | $0.013 |
| FlowHunt($30,000時) | $30,000 | 2,250,000 | $0.0133 |
FlowHuntの方が圧倒的に効率的だと言えるでしょう。
OCRは非常に有用ですが、いくつかの課題も存在します。
これらの課題に対応するには、高性能かつ柔軟なOCRツールが必須です。FlowHuntのAPIは複雑なドキュメント構造にも対応できる堅牢なOCRソリューションであり、大規模OCRプロジェクトにも最適です。
自動化には以下のPythonライブラリをインストールしてください。
pip install requests pdf2image git+https://github.com/QualityUnit/flowhunt-python-sdk.git
これにより以下が導入されます:
このコードはPDFを画像に変換し、各画像をFlowHuntへ送信してOCR処理し、出力をCSV形式で保存します。
ライブラリのインポート
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
json, os, re, timeはJSON処理、ファイル管理、正規表現、タイマー制御用。requests: HTTPリクエストやOCR結果のダウンロード用。flowhunt: FlowHunt SDK。認証やOCR API通信を担当。pdf2image: PDFページを画像に変換、各ページごとにOCR可能。PDFページを画像に変換する関数
def convert_pdf_to_image(path: str) -> None:
"""
Convert a PDF file to images, storing each page as a JPEG.
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page' + str(i) + '.jpg', 'JPEG')
convert_from_path: 各PDFページを画像化。images[i].save: 各ページをJPEGで保存し、OCR処理に利用。出力添付ファイルURLの抽出
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
API設定と認証
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(
host="https://api.flowhunt.io",
api_key={"APIKeyHeader": "<API_KEY_HERE>"}
)
APIクライアントの初期化
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
workspace_idを取得。フローセッションの開始
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(flow_id=FLOW_ID)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
画像をアップロードしOCR処理
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
OCR処理の呼び出しと結果のポーリング
invoke_rsp = flows_api.invoke_flow_response(
create_session_rsp.session_id,
flowhunt.FlowSessionInvokeRequest(message="")
)
while True:
get_flow_rsp = flows_api.poll_flow_response(
create_session_rsp.session_id, invoke_rsp.message_id
)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
break
time.sleep(3)
OCR出力のダウンロードと保存
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
スクリプト実行方法:
data/フォルダに配置します。<FLOW_ID_HERE>と<API_KEY_HERE>をFlowHuntの認証情報に置き換えます。このPythonスクリプトは、大量ドキュメント処理が求められる業界でのOCR業務を効率化するソリューションです。FlowHuntのAPIを活用することで、ドキュメントからCSVへの変換を自動化し、ワークフローの最適化と生産性向上を実現します。
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
def convert_pdf_to_image(path: str) -> None:
"""
Convert a pdf file to an image
:return:
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page'+ str(i) +'.jpg', 'JPEG')
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(host = "https://api.flowhunt.io",
api_key = {"APIKeyHeader": "<API_KEY_HERE>"})
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(
flow_id=FLOW_ID
)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
invoke_rsp = flows_api.invoke_flow_response(create_session_rsp.session_id, flowhunt.FlowSessionInvokeRequest(
message="",
))
while True:
get_flow_rsp = flows_api.poll_flow_response(create_session_rsp.session_id, invoke_rsp.message_id)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
print("Attachment URL: ", attachment_url, "\n Downloading the file...")
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
break
time.sleep(3)
except ApiException as e:
print("error for file ", image)
print(e)
AIベースのOCRは、機械学習やNLPを活用してドキュメントの文脈を理解し、複雑なレイアウトにも対応、請求書から構造化データを抽出します。従来のOCRは固定フォーマットの文字認識に依存しています。
AI OCRは、スピード・精度・スケーラビリティ・構造化された出力を実現し、手作業の削減やエラー低減、業務システムとのシームレスな統合を可能にします。
FlowHuntのPython SDKを使えば、PDFを画像に変換してAPIへ送信、OCR結果をCSV形式で取得し、抽出プロセス全体を自動化できます。
主な課題は画像品質、複雑なレイアウト、多言語対応などです。FlowHuntのAPIは高度なAIモデルと柔軟な処理機能でこれらに対応しています。
FlowHuntのAI OCRは数秒で請求書を処理し、人件費のごく一部で済むため、効率性とスケーラビリティを大幅に向上できます。
アルシアはFlowHuntのAIワークフローエンジニアです。コンピュータサイエンスのバックグラウンドとAIへの情熱を持ち、AIツールを日常業務に統合して効率的なワークフローを作り出し、生産性と創造性を高めることを専門としています。
請求書データ抽出OCRフローが、どのように請求書データの自動抽出・整理を通じて財務プロセスを効率化できるかをご紹介します。その特徴やメリット、あらゆる規模の企業における効率性・正確性の向上について学びましょう。詳細はFlowHuntでご覧ください。...
請求書画像をアップロードし、請求書番号、種類、言語、品目、価格、合計金額などの主要な請求書データを抽出することで、請求書処理を自動化します。抽出結果はマークダウンテーブルと構造化CSVファイルとして出力され、業務の効率化をサポートします。...
AI搭載のOCRがデータ抽出を変革し、文書処理を自動化し、金融・医療・小売業などの業界で効率化を推進する方法をご紹介します。進化の過程や実際のユースケース、OpenAI Soraなど最先端のソリューションにも迫ります。...