
大規模言語モデル(LLM)
大規模言語モデル(LLM)は、膨大なテキストデータで訓練されたAIの一種で、人間の言語を理解・生成・操作することができます。LLMはディープラーニングやトランスフォーマーニューラルネットワークを用い、テキスト生成、要約、翻訳など多様な業界でのタスクを実現します。...
1 分で読める
AI
Large Language Model
+4

FlowHuntは、GPT-4、Claude 3、Llama 3、Grokなどの主要なLLMをコンテンツライティング向けにテスト・評価し、可読性、トーン、独自性、キーワード使用を分析して最適なモデル選びをサポートします。
大規模言語モデル(LLM)は、コンテンツの作成や消費方法を一変させる最先端AIツールです。個々のLLMの違いを深掘りする前に、これらのモデルが人間のようなテキストをいとも簡単に生成できる理由を理解しましょう。
LLMは膨大なデータセットで訓練されており、文脈や意味論、構文を深く把握しています。大量のデータに基づき、文章内の次の単語を正しく予測し、理解しやすい文章へと組み立てます。その効果の理由の一つがトランスフォーマーアーキテクチャです。この自己注意メカニズムがニューラルネットワークを用いてテキストの構文や意味を処理します。つまり、LLMは幅広い複雑なタスクにも簡単に対応できるのです。
大規模言語モデル(LLM)は、ビジネスのコンテンツ制作の在り方を大きく変えました。パーソナライズされた最適化テキストを生成できるため、LLMはメール、ランディングページ、SNS投稿などを人間の言語プロンプトから作成します。
LLMがコンテンツライターをサポートできること:
さらに、LLMの未来は有望です。技術の進歩により、精度やマルチモーダル機能が向上し、その応用範囲は多くの業界に大きな影響を与えるでしょう。
ここで、これからテストする人気のLLMを簡単に紹介します:
| モデル | 独自の強み |
|---|---|
| GPT-4 | 多様なライティングスタイルで汎用性が高い |
| Claude 3 | 創造的かつ文脈に強いタスクで卓越 |
| Llama 3.2 | 効率的な要約に定評 |
| Grok | リラックスしたユーモラスなトーンに特化 |
LLMを選ぶ際は、コンテンツ制作のニーズを考慮することが重要です。各モデルは、複雑なタスクへの対応からAIによる創造的コンテンツ生成まで、独自の特長を持っています。テストの前に、それぞれがコンテンツ制作にどう貢献できるかを簡単にまとめます。
主な特徴:
パフォーマンス指標:
強み:
課題:
総じて、GPT-4はコンテンツ制作やデータ分析戦略を強化したい企業にとって強力なツールです。
主な特徴:
強み:
課題:
主な特徴:
強み:
課題:
Llama 3は堅牢かつ多用途なオープンソースLLMとして、AI技術の進展を牽引しつつ、ユーザーに課題ももたらします。
主な特徴:
強み:
課題:
要約すると、xAI Grokは興味深い特徴とメディア露出の強みはあるものの、人気や性能面で競合他社と比べて課題が残ります。
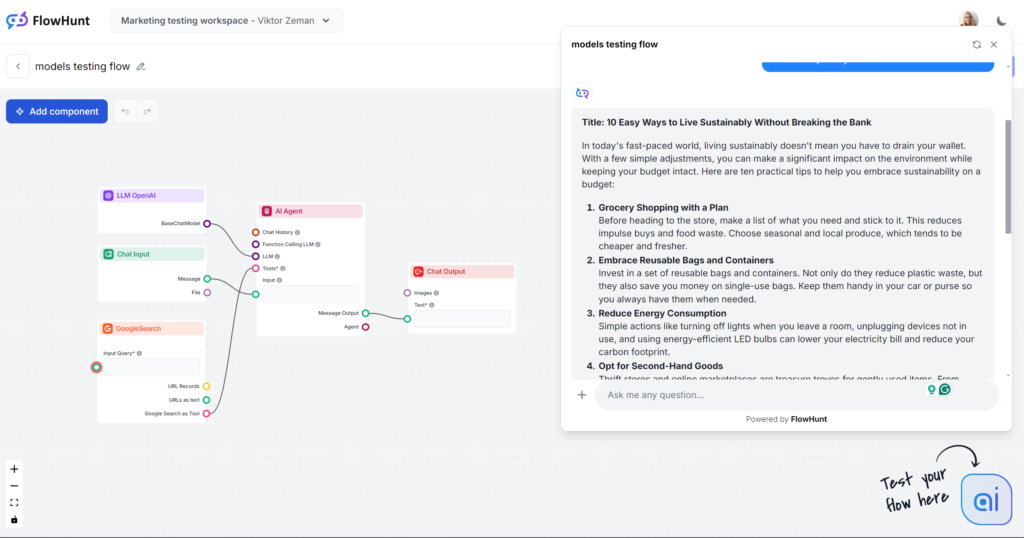
早速テストに入りましょう。基本的なブログ記事の出力で各モデルを評価します。テストは全てFlowHuntで実施し、LLMモデルのみを切り替えました。
主な評価ポイント:
テストプロンプト:
「10 Easy Ways to Live Sustainably Without Breaking the Bank(無理せず持続可能な生活を送る10の簡単な方法)」というタイトルでブログ記事を書いてください。トーンは実用的で親しみやすく、忙しい人でも実践できる現実的なアクションに焦点を当ててください。「sustainability on a budget(予算内での持続可能性)」を主キーワードにしてください。買い物やエネルギー使用、生活習慣など日常の事例を盛り込みましょう。最後に今日から1つ始めてみようという励ましの呼びかけで締めくくってください。
注:Flowでは約500語の出力に制限しています。内容が駆け足だったり深掘りされていない場合は仕様です。
もしブラインドテストだったら、「現代の忙しい世界では…」という冒頭文で一発で分かるでしょう。このモデルの文章にはすでに馴染みがあるはずです。最も人気が高く、多くのサードパーティAIライティングツールの中核でもあります。GPT-4oは汎用コンテンツには常に安全な選択肢ですが、曖昧で冗長になることも覚悟しましょう。
トーンと言語
使い古された冒頭を除けば、GPT-4oは期待通りの仕事をしました。これが人間の執筆だと思わせることはありませんが、十分に構成された記事でプロンプトにも忠実です。トーンも実用的かつ親しみやすく、すぐに実践的なヒントに焦点を当てています。
キーワード使用
キーワードテストでもGPT-4oは良好でした。指定された主キーワードだけでなく、類似語や関連キーワードも自然に活用しています。
可読性
フレッシュ・キンケイドスケールでは10~12年生(やや難しい)に該当し、スコアは51.2。あと1ポイント低ければ大学レベルです。短い出力のため「sustainability」自体が可読性に影響しているかもしれませんが、改善の余地は十分にあります。
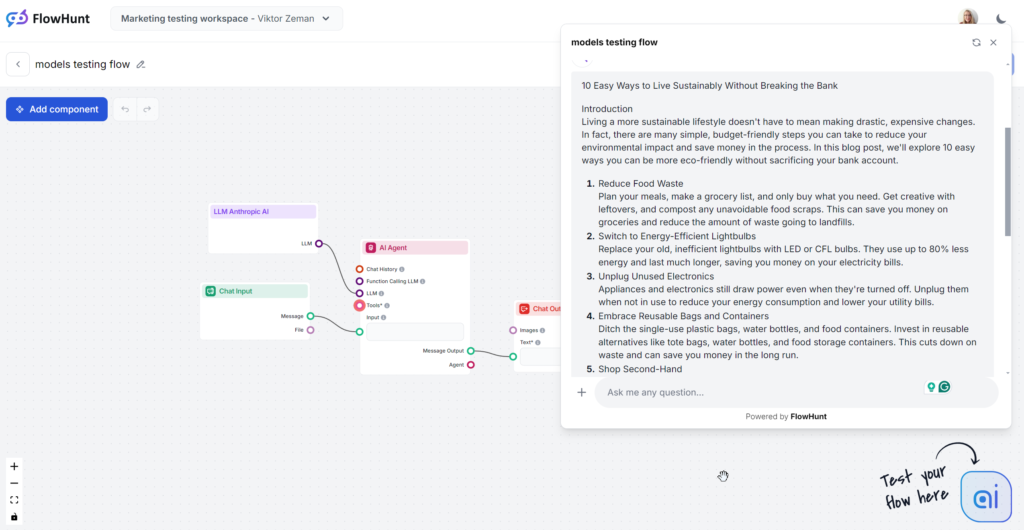
分析対象のClaude出力は、中間のSonnetモデルで、コンテンツ制作に最適と噂されています。内容は読みやすく、GPT-4oやLlamaよりも明らかに人間らしい印象です。Claudeはクリーンかつシンプルに情報を効率よく伝えたい時に最適で、GPTのように冗長でも、Grokのように派手でもありません。
トーンと言語
Claudeはシンプルかつ共感しやすい人間味のある回答で際立っています。トーンも実用的かつ親しみやすく、すぐに実践的なヒントに焦点を当てています。
キーワード使用
Claudeだけがキーワード部分を無視し、3回中1回しかキーワードを使用しませんでした。使われた場合も結論部のみで、やや不自然な印象でした。
可読性
SonnetはFlesch-Kincaidスケールで8~9年生(平易な英語)に該当し、Grokよりわずかに低いだけの高スコアです。Grokはトーンと語彙を大きく変えたのに対し、ClaudeはGPT-4oに近い語彙でした。可読性の高さの理由は、短い文・日常語・曖昧な内容の排除です。
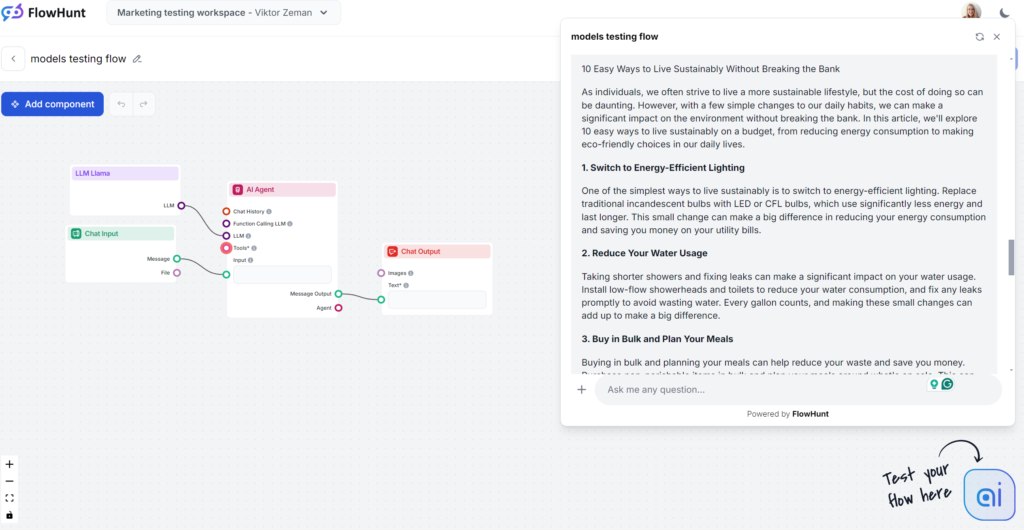
Llamaの最大の強みはキーワード使用です。一方で、文体はやや平凡で冗長ですが、GPT-4oよりは退屈さが少ない印象です。LlamaはGPT-4oの従兄弟のような存在で、やや冗長かつ曖昧な文体ですが、安全な選択肢です。OpenAIモデルの文体が好きだけど、典型的なGPT表現を避けたい人には最適です。
トーンと言語
Llamaの生成記事はGPT-4oによく似ています。冗長さや曖昧さも同程度ですが、トーンは実用的で親しみやすいです。
キーワード使用
キーワード使用テストの勝者はMetaです。Llamaはキーワードを複数回、序盤から使い、自然に類似語や関連キーワードも盛り込んでいます。
可読性
Flesch-Kincaidスケールでは10~12年生(やや難しい)で、スコアは53.4。GPT-4o(51.2)よりやや良好です。短い出力のため「sustainability」自体が可読性に影響しているかもしれませんが、やはり改善の余地はあります。
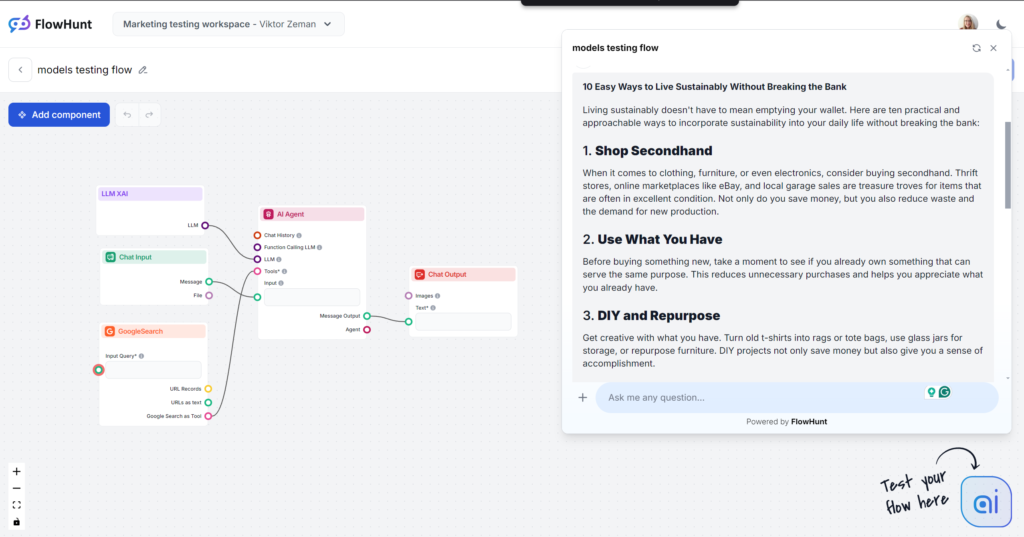
Grokは特にトーンや言語面で大きな驚きをもたらしました。とても自然でリラックスしたトーンで、まるで親しい友人から気軽にアドバイスをもらっているような印象です。ラフでテンポの良い文章が好みなら、Grokは間違いなくおすすめです。
トーンと言語
出力は非常に読みやすく、言葉も自然でテンポも良く、イディオムも上手に使われています。モデル独自のトーンを維持し、人間らしい文章への挑戦も目立ちます。注意:GrokのラフなトーンはB2BやSEO重視コンテンツには不向きな場合もあります。
キーワード使用
Grokは指定キーワードを使いましたが、結論部分のみでした。他モデルはより適切な位置にキーワードを配置し、関連語も追加しましたが、Grokは言葉の流れを重視しています。
可読性
カジュアルな言語のおかげで、GrokはFlesch-Kincaidテストで高得点をマーク。スコアは61.4で7~8年生(平易な英語)レベルとなり、一般層にも分かりやすい内容です。この可読性の向上は実感できるレベルです。
LLMの力は学習データの質に依存しますが、時にバイアスや誤情報を含み、誤った情報拡散につながることもあります。AI生成コンテンツは必ずファクトチェックし、公平性や包摂性にも注意が必要です。モデルごとに入力データのプライバシーや有害出力制限の方針が異なることも覚えておきましょう。
倫理的利用のために、組織はデータプライバシー、バイアス対策、コンテンツモデレーションの枠組みを策定すべきです。AI開発者・ライター・法務担当者の継続的な対話も不可欠です。主な倫理的懸念はこちら:
LLMの選択は、組織のコンテンツガイドラインと倫理的に整合する必要があります。オープンソース/商用どちらも潜在的な悪用リスクを評価しましょう。
バイアス、不正確さ、幻覚(hallucination)はAI生成コンテンツの大きな課題です。組み込みガイドラインの影響で、LLMの出力が曖昧で低価値になることも多く、ビジネスでは追加トレーニングやセキュリティ対策が必要です。小規模企業にとってカスタム訓練は負担が大きいため、一般モデルにFlowHuntのようなサードパーティツールで機能を追加するのが現実的です。
FlowHuntなら、特定の知識やインターネットアクセス、新機能をクラシックなベースモデルに追加可能。ベースモデルの制限や複数サブスクリプションの悩みなく、最適なモデルを選べます。
もう一つの大きな課題はモデルの複雑さです。数十億のパラメータを持つモデルは管理や理解、デバッグが困難。FlowHuntなら、チャット単体ではできない細かな制御が可能です。個別機能をブロックとして追加し、自分だけのAIツールライブラリを作れます。
コンテンツライティングにおける言語モデル(LLM)の未来は非常に有望で刺激的です。モデルの進化により、より高い精度とバイアスの少ないコンテンツ生成が期待できます。これにより、ライターはAI生成でも信頼性が高く人間らしいテキストを作れるようになるでしょう。
LLMはテキストだけでなく、マルチモーダルコンテンツ生成にも熟達していきます。テキストと画像の両方を管理でき、様々な業界でクリエイティブなコンテンツ制作を後押しします。より大規模かつ精選されたデータセットにより、LLMは信頼性の高いコンテンツ作成や文体の洗練も実現します。
しかし現状では、LLM単体ではこれら全ての機能を持たず、各社・各モデルが機能や市場シェアを競い合っています。FlowHuntはそれらすべてを一つにまとめ、最適な選択と活用を可能にします。
GPT-4は一般的なコンテンツにおいて最も人気があり多用途ですが、MetaのLlamaは新鮮なライティングスタイルを提供します。Claude 3はクリーンでシンプルなコンテンツに最適で、Grokはリラックスした人間らしいトーンが得意です。最適な選択はコンテンツの目的や好みによって異なります。
可読性、トーン、独自性、キーワード使用、そして各モデルが自分のコンテンツニーズにどのように合致するかを検討してください。また、創造性やジャンルの多様性、統合の容易さなどの強み、バイアスや冗長さ、リソース要件などの課題にも注意しましょう。
FlowHuntでは複数の主要LLMを一つの環境でテスト・比較でき、出力のコントロールが可能です。複数のサブスクリプションを契約することなく、自分に最適なモデルを見つけることができます。
はい。LLMはバイアスを助長したり、誤情報を生成したり、データプライバシー上の懸念を引き起こす可能性があります。AIの出力をファクトチェックし、倫理整合性を評価し、責任ある利用のための枠組みを構築することが重要です。
今後のLLMは精度の向上、バイアスの軽減、マルチモーダル(テキスト・画像等)生成が可能になり、より信頼性と創造性の高いコンテンツ制作を実現します。FlowHuntのような統合プラットフォームが、これらの高度な機能へのアクセスを効率化します。
大規模言語モデル(LLM)は、膨大なテキストデータで訓練されたAIの一種で、人間の言語を理解・生成・操作することができます。LLMはディープラーニングやトランスフォーマーニューラルネットワークを用い、テキスト生成、要約、翻訳など多様な業界でのタスクを実現します。...
大規模言語モデル(LLM)によるテキスト生成は、機械学習モデルを高度に活用し、プロンプトから人間らしいテキストを生成する技術を指します。トランスフォーマーアーキテクチャによって強化されたLLMが、コンテンツ制作、チャットボット、翻訳などをどのように革新しているかを探ります。...
2025年6月におけるコーディング向け大規模言語モデル(LLM)のトップを紹介します。学生、趣味のプログラマー、専門家向けに、インサイト、比較、実践的なヒントを提供する完全な教育ガイドです。...
