
LLMコンテキスト
FlowHuntのLLMコンテキストを統合して、AI支援開発を強化しましょう。スマートなファイル選択、高度なコンテキスト管理、直接的なLLM統合により、関連するコードやドキュメントのコンテキストをお気に入りの大規模言語モデルのチャットインターフェースにシームレスに注入できます。...
1 分で読める
AI
LLM
+4

FlowHuntの新しいオープンソースCLIツールキットは、LLM判定者機能による包括的なフロー評価を実現し、AIワークフローの詳細なレポートと自動品質評価を提供します。
FlowHunt CLIツールキットのリリースを発表できることを大変嬉しく思います。これは、開発者によるAIフローの評価・テスト手法を革新するために設計された新しいオープンソースのコマンドラインツールです。エンタープライズレベルのフロー評価機能と、高度なレポーティング、そして「LLM判定者」という革新的な仕組みを、オープンソースコミュニティに提供します。
FlowHunt CLIツールキットは、AIワークフローのテスト・評価において大きな前進を示します。現在GitHubで公開中のこのオープンソースツールキットは、開発者向けに以下の包括的な機能を提供します:
このツールキットは、透明性とコミュニティ主導の開発へのコミットメントを体現し、先進的なAI評価技術を世界中の開発者に開放します。
CLIツールキットの中でも特に革新的な機能が「LLM判定者」の実装です。このアプローチは、AIがAIの応答品質・正確性を評価するものであり、AIが高度な推論能力でAIのパフォーマンスを判定します。
私たちの実装のユニークな点は、評価フロー自体をFlowHuntで構築したことです。このメタ的アプローチは、プラットフォームの柔軟性と強力さを証明しつつ、堅牢な評価システムを実現しています。LLM判定者フローは、いくつかの連携コンポーネントで構成されています:
1. プロンプトテンプレート:評価基準を明示したプロンプトを作成
2. 構造化出力生成:LLMで評価を処理
3. データパーサー:レポート用に構造化出力を整形
4. チャット出力:最終的な評価結果を表示
LLM判定者システムの中心には、一貫性と信頼性を確保する精緻なプロンプトがあります。以下がコアプロンプトテンプレートです:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
このプロンプトにより、LLM判定者は以下を提供します:
LLM判定者フローは、FlowHuntのビジュアルフロービルダーを用いた高度なAIワークフロー設計の好例です。以下のように各コンポーネントが連携します:
フローは、チャット入力コンポーネントで、実際の応答と参照解答を含む評価リクエストを受け取ります。
プロンプトテンプレートコンポーネントが動的に評価プロンプトを作成します:
{target_response} プレースホルダーに参照解答を挿入{actual_response} プレースホルダーに実際の応答を挿入構造化出力生成コンポーネントが、選択したLLMでプロンプトを処理し、以下を含む構造化出力を生成します:
total_rating:1~4の数値スコアcorrectness:正誤判定(correct/incorrect)reasoning:評価の詳細説明Parse Dataコンポーネントで構造化出力を読みやすく整形し、チャット出力で最終評価結果を提示します。
LLM判定者システムは、AIフロー評価をより効果的にする高度な機能を備えています:
単純な文字列一致ではなく、LLM判定者は以下を理解します:
4段階の評価スケールで細やかな判定が可能です:
各評価に詳細な理由付けが含まれるため、以下が可能です:
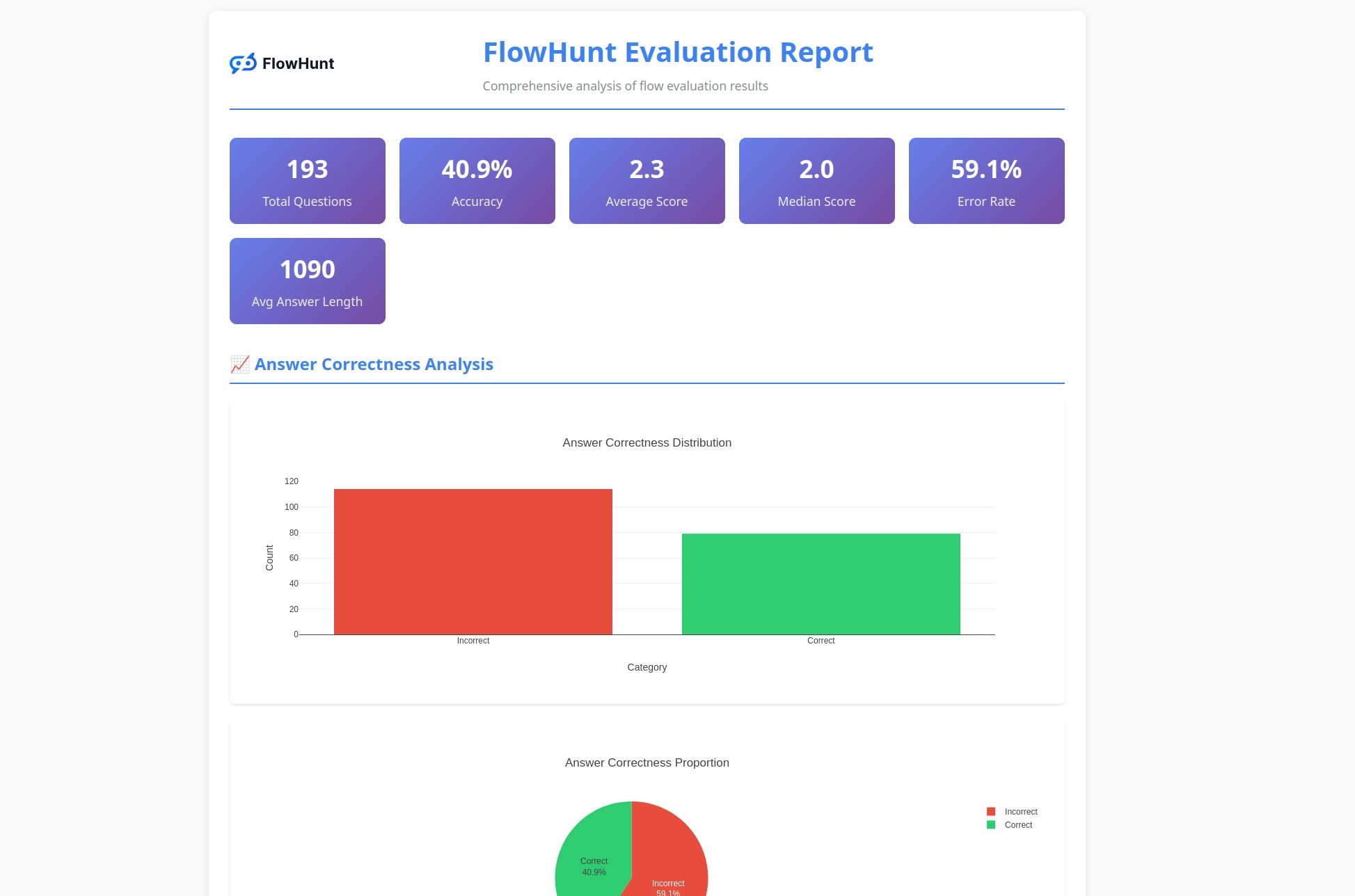
CLIツールキットは、フローパフォーマンスに関する実践的なインサイトをもたらす詳細なレポートを生成します:
プロフェッショナルレベルのツールでAIフロー評価を始めてみませんか?以下の手順で簡単に始められます:
ワンラインインストール(推奨)(macOS・Linux対応):
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
これにより自動で以下が行われます:
flowhuntコマンドをPATHに追加手動インストール方法:
# リポジトリをクローン
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# pipでインストール
pip install -e .
インストール確認:
flowhunt --help
flowhunt --version
1. 認証 まず、FlowHunt APIで認証します:
flowhunt auth
2. フロー一覧を表示
flowhunt flows list
3. フローを評価 テストデータをCSVファイルで用意します:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
LLM判定者で評価を実行:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. フローのバッチ実行
flowhunt batch-run your-flow-id input.csv --output-dir results/
評価システムは包括的な分析を提供します:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
主な機能:
CLIツールキットはFlowHuntプラットフォームとシームレスに連携し、以下が可能です:
CLIツールキットのリリースは、単なる新しいツール以上の意味を持ちます。私たちのビジョンは――
品質の見える化:高度な評価技術でAI性能を定量化・比較可能に
テストの自動化:包括的なテストフレームワークで手間を削減し信頼性を向上
透明性の標準化:詳細な理由付け・レポートでAI挙動を理解・デバッグ可能に
コミュニティ主導のイノベーション:オープンソースで知見共有と改善を加速
FlowHunt CLIツールキットのオープンソース化を通じて、私たちは以下を約束します:
LLM判定者を備えたFlowHunt CLIツールキットは、AIフロー評価の分野に大きな進化をもたらします。洗練された評価ロジック、充実のレポーティング、オープンソースならではのアクセス性で、開発者がより良い・信頼性の高いAIシステムを構築できるよう支援します。
FlowHunt自身でFlowHuntフローを評価するというメタ的アプローチは、プラットフォームの成熟度と柔軟性を示し、より広いAI開発コミュニティへ強力なツールを提供します。
シンプルなチャットボットから複雑なマルチエージェントシステムまで、FlowHunt CLIツールキットは品質・信頼性・継続的改善を支える評価インフラを提供します。
AIフロー評価を次のレベルへ――
今すぐGitHubリポジトリでFlowHunt CLIツールキットを始め、LLM判定者の力を体験してください。
AI開発の新時代が、今ここに。「オープンソース」で。
FlowHunt CLIツールキットは、AIフローの評価と包括的なレポーティング機能を備えたオープンソースのコマンドラインツールです。LLM判定評価、正誤分析、詳細なパフォーマンス指標などの機能を含みます。
LLM判定者は、FlowHunt内で構築された高度なAIフローを用いて他のフローを評価します。実際の応答と参照解答を比較し、スコア付け・正誤判定・詳細な理由付けを各評価ごとに提供します。
FlowHunt CLIツールキットはオープンソースで、GitHub(https://github.com/yasha-dev1/flowhunt-toolkit)で公開されています。クローンやコントリビュート、自由にAIフロー評価にご利用いただけます。
このツールキットは、正誤結果の内訳、LLM判定評価(スコアと理由付け)、パフォーマンス指標、様々なテストケースでのフロー挙動の詳細分析など、包括的なレポートを生成します。
はい!LLM判定フローはFlowHuntプラットフォーム上で構築されており、様々な評価シナリオに適用できます。プロンプトテンプレートや評価基準を用途に応じてカスタマイズ可能です。
ヤシャは、Python、Java、機械学習を専門とする才能あるソフトウェア開発者です。AI、プロンプトエンジニアリング、チャットボット開発に関する技術記事を執筆しています。
FlowHuntプラットフォームで高度なAIワークフローを構築・評価しましょう。他のフローを判定できるフローを今すぐ作成できます。
FlowHuntのLLMコンテキストを統合して、AI支援開発を強化しましょう。スマートなファイル選択、高度なコンテキスト管理、直接的なLLM統合により、関連するコードやドキュメントのコンテキストをお気に入りの大規模言語モデルのチャットインターフェースにシームレスに注入できます。...
FlowHunt 2.4.1では、Claude、Grok、Llama、Mistral、DALL-E 3、Stable Diffusionなど、主要な新AIモデルを導入し、AIプロジェクトでの実験・創造・自動化の選択肢を広げます。...
大規模言語モデルをAIエージェントやチャットボットの評価者として活用するための包括的ガイド。LLM As a Judge手法、ジャッジプロンプト作成のベストプラクティス、評価指標、そしてFlowHuntのツールキットを用いた実践例を学びましょう。...

