データフィルター コンポーネント
Filter Dataコンポーネントは、特定のテキストベースのキー/値ペアに基づいてデータレコードをフィルタリングするために設計されています。これは、Pythonの辞書のエントリをフィルタリングするのと同じような感覚で使えます。より大きなデータセットから特定の条件に合うレコードを抽出・分離したいAIワークフローで役立ちます。
このコンポーネントは何をしますか?
このコンポーネントは入力データを調べ、指定したキーと値に一致するレコードだけを選択します。たとえば、ユーザープロファイルのデータセットがあり、その中から "status": "active" のプロファイルだけを見つけたい場合、このコンポーネントでその条件に合うレコードを抽出できます。
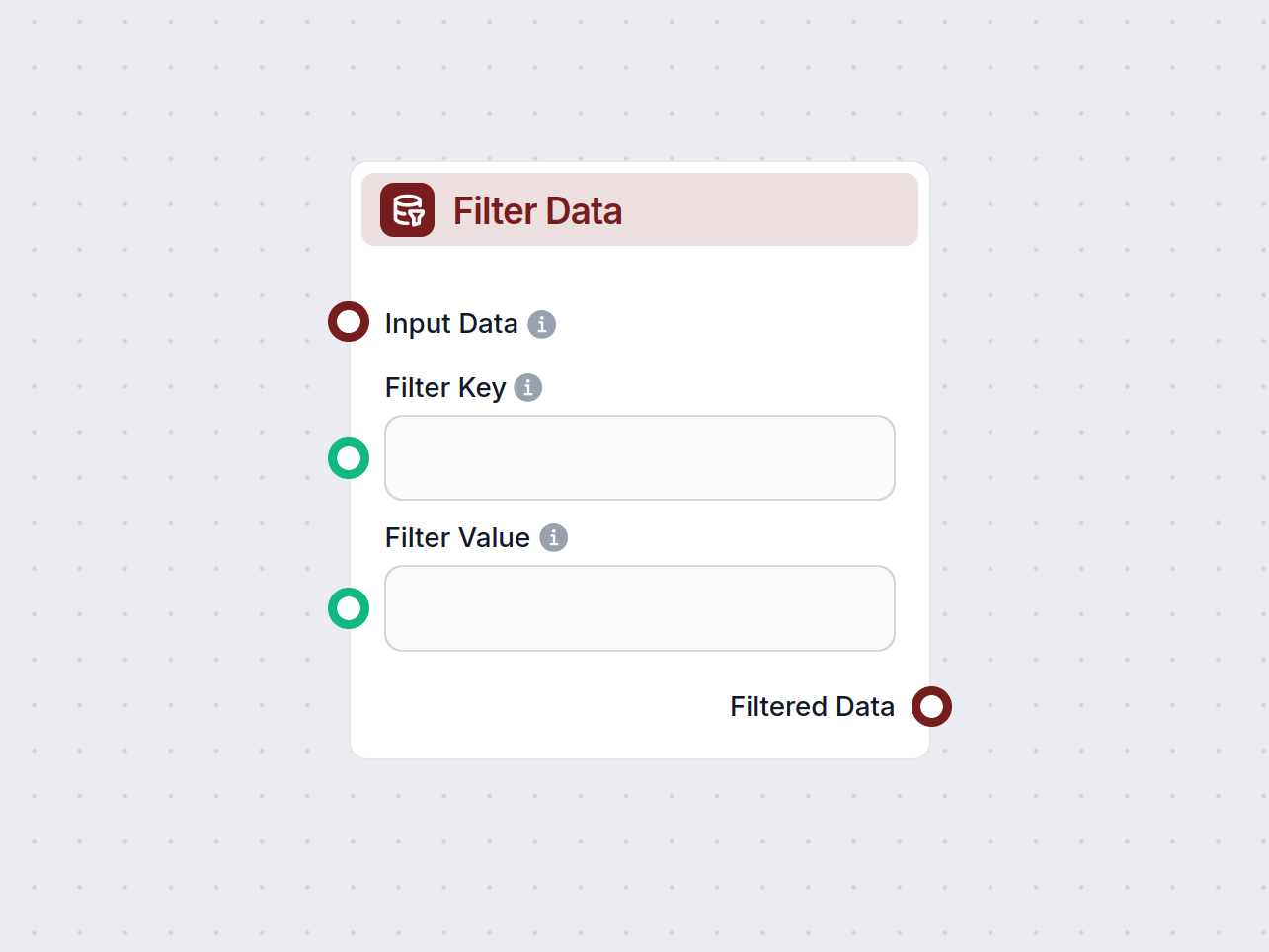
入力
| 入力名 | 型 | 説明 | 必須 | 例・補足 |
|---|---|---|---|---|
| Input Data | Data | フィルタ対象のレコード | いいえ | フィルタしたいデータセット |
| Filter Key | Message | フィルタ対象のキー | いいえ | 例: “status” |
| Filter Value | Message | キーに一致させる値 | いいえ | 例: “active” |
- Input Data: これはフィルタしたいデータセットです。辞書や辞書のリストなど、キー/値アクセスが可能なデータ構造に対応しています。
- Filter Key: フィルタしたいキー名(例: “status”)を指定します。
- Filter Value: レコードを出力に含めるためにキーが一致すべき値(例: “active”)を指定します。
出力
| 出力名 | 型 | 説明 |
|---|---|---|
| Filtered Data | Data | フィルタ条件に一致したデータレコード |
- Filtered Data: 指定した値にキーが一致するデータレコードだけが出力に含まれます。
Filter Dataコンポーネントを使う理由
- データ抽出: 必要なデータだけを簡単に抽出でき、ノイズを減らして後続処理を効率化します。
- 自動化: AIパイプライン内の一般的なフィルタ処理を、カスタムコードなしで自動化できます。
- 柔軟性: キー/値アクセス可能なあらゆるデータレコードに対応し、幅広い用途に使えます。
主な利用シーン
- 特定の日付やステータスのユーザーログを抽出
- タグやラベルでAIモデルの出力をフィルタ
- 訓練・評価・レポート用に必要なエントリーだけを含むようにデータセットを前処理
まとめ表
| 特徴 | 詳細 |
|---|---|
| コンポーネント名 | Filter Data |
| 説明 | キー/値ペアでデータをフィルタ |
| 入力タイプ | Data, Message(キー・値用) |
| 出力タイプ | Data(フィルタ後) |
| 主な用途 | ワークフロー内でのデータ抽出・フィルタ |
このコンポーネントは、属性によるフィルタが必要なあらゆるAIワークフローで、データの管理や処理に欠かせない基本的なビルディングブロックです。