ファイルへのエクスポート
FlowHuntの「ファイルへのエクスポート」コンポーネントを使えば、ワークフロー中に生成されたテキストやデータを、TXT、PDF、CSVなど様々な形式のダウンロード可能なファイルとして保存できます。AIワークフローの一部としてファイル作成を簡単に自動化できます。...
1 分で読める
Automation
File Export
+3
FlowHuntの「ドキュメントからテキスト」コンポーネントで構造化データを読みやすいMarkdownテキストに変換。効率的かつ関連性の高いAI出力のためのカスタマイズ可能なコントロールを提供します。
コンポーネントの説明
AIは大量のデータを数秒で解析できますが、出力に適したデータは一部のみです。「ドキュメントからテキスト」コンポーネントは、リトリーバーから取得されたデータの処理方法やテキストへの変換方法をコントロールできます。
ドキュメントからテキストコンポーネントは、入力された知識ドキュメントをプレーンテキスト形式へ変換するために設計されています。これは、テキストデータがさらなる処理や分析、あるいは言語モデルへの入力として必要となるAI・データ処理ワークフローで特に有用です。
このコンポーネントは、1つまたは複数の構造化ドキュメント(HTML、Markdown、PDFなどのサポート形式)からテキストコンテンツを抽出します。どの部分をエクスポートするか、メタデータを含めるか、セクションやヘッダーの扱い方などを細かく指定できます。出力は抽出されたテキストを含む統一メッセージオブジェクトとなり、要約、分類、質問応答などの後続タスクにすぐ利用可能です。
このコンポーネントは、いくつかの設定可能な入力を受け付けます。
| 入力名 | 型 | 必須 | 説明 | デフォルト値 |
|---|---|---|---|---|
| ドキュメント | List[Document] | はい | テキストへ変換する知識ドキュメント | N/A(ユーザー入力) |
| H1から抽出(存在すれば) | Boolean | はい | 最初のH1ヘッダーが存在する場合、そこから抽出を開始 | true |
| ポインターから読み込む | Boolean | はい | 入力クエリに最も合致するポインターから抽出開始、該当なければ全て読み込み | true |
| 最大トークン数 | Integer | いいえ | 出力テキストの最大トークン数 | 3000 |
| 最後のヘッダーをスキップ | Boolean | はい | 出力最適化のため、最後のヘッダー(多くはフッター)をスキップ | false |
| 抽出戦略 | String | はい | テキスト抽出戦略:ドキュメントを連結するか、各ドキュメントから均等に含める | “各ドキュメントから均等に含める” |
| エクスポート内容 | マルチセレクト | いいえ | どのコンテンツタイプを含めるか(例:H1、H2、段落など) | 全タイプ選択済み |
| メタデータを含める | マルチセレクト | いいえ | 利用可能な場合、出力に含めるメタデータフィールド | Product |
利用可能なコンテンツタイプ: H1, H2, H3, H4, H5, H6, 段落
メタデータオプション: 著者、Product、BreadcrumbList、VideoObject、BlogPosting、FAQPage、WebSite、opengraph
このコンポーネントは以下の出力を生成します。
| 機能 | 説明 |
|---|---|
| 入力タイプ | ドキュメントのリスト |
| 出力タイプ | メッセージ(テキスト+メタデータ) |
| 内容の粒度 | 含めるヘッダーや段落を選択可能 |
| メタデータオプション | 複数のメタデータフィールドを選択してエクスポート |
| 出力サイズ調整 | 最大トークン数を設定 |
| 抽出戦略 | ドキュメント連結またはバランス抽出 |
| セクション選択 | H1から開始、ポインターから開始、最後のヘッダーをスキップ |
Botはテキスト出力を作成するために多数のドキュメントをクロールする場合があります。戦略設定により、複数ドキュメントをトークン制限内でどのように活用するかをコントロールできます。
現在、選択できる戦略は2つです:
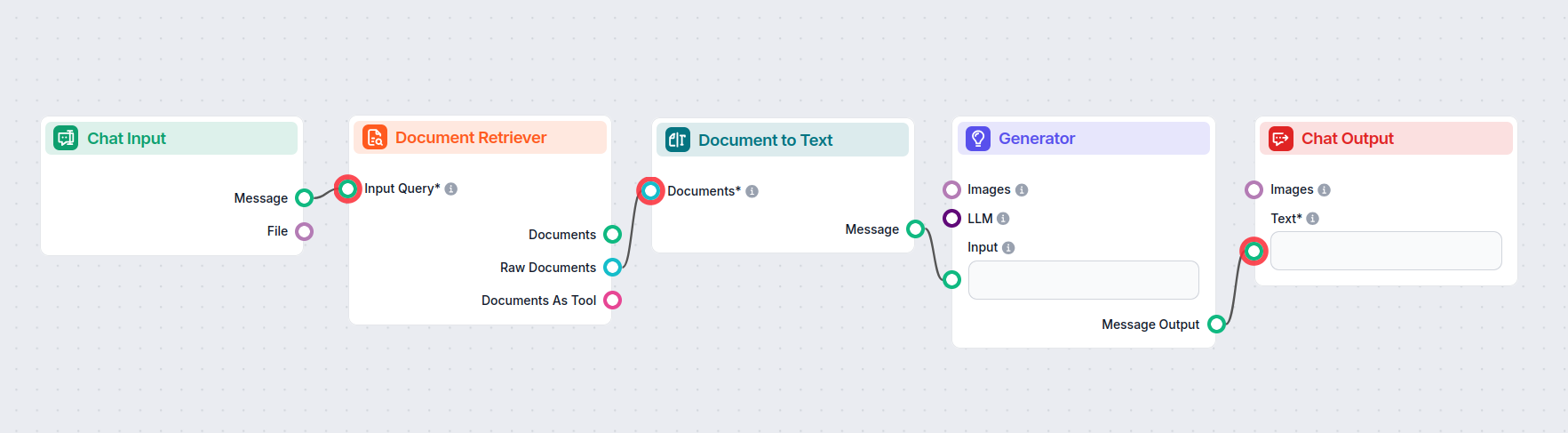
このコンポーネントは「トランスフォーマー」型で、2つの出力間を橋渡しします。Document to Textは、リトリーバーコンポーネントの出力(Documents)を受け取ります。
取得した知識は、トランスフォーマーを通して読みやすいMarkdownテキストに変換されます。このテキストは、分割、ウィジェット、各種出力など、テキスト入力を必要とする他のコンポーネントに接続できます。
以下は、Document to Textコンポーネントを使用し、ドキュメントリトリーバーとAIジェネレーター間を橋渡しする例です。
このコンポーネントは、リトリーバータイプのコンポーネントから知識を取得し、それを読みやすいMarkdownテキストに変換します。変換されたテキストは、テキスト入力を受け付けるあらゆるコンポーネントに接続できます。
FlowHuntの「ファイルへのエクスポート」コンポーネントを使えば、ワークフロー中に生成されたテキストやデータを、TXT、PDF、CSVなど様々な形式のダウンロード可能なファイルとして保存できます。AIワークフローの一部としてファイル作成を簡単に自動化できます。...
ナレッジソースウィジェットを使用して、チャットボットの応答内に関連するドキュメントを直接表示しましょう。このコンポーネントは選択したナレッジドキュメントを視覚的に区別されたウィジェットとして表示し、ユーザーが会話中にサポート情報へ簡単にアクセス・確認できるようにします。...
Parse Dataコンポーネントは、構造化データをカスタマイズ可能なテンプレートでプレーンテキストに変換します。ワークフロー内でさらに利用するための柔軟なフォーマットや変換を可能にし、情報の標準化や後続コンポーネントへの準備を支援します。...