AIチャットボットの作り方:完全ステップバイステップガイド
AIチャットボットをゼロから構築する方法を、包括的なガイドで解説。FlowHuntのノーコードプラットフォームを活用し、最適なツール・フレームワーク・プロセスを知り、インテリジェントな会話型AIシステムを作成しましょう。...
1 分で読める
AIチャットボットが自然言語を処理し、ユーザーの意図を理解し、知識ベースへアクセスして知的な応答を生成する仕組みを解説します。NLP、機械学習、チャットボットアーキテクチャを技術的な深さで学びましょう。
AIチャットボットは、自然言語入力をNLPアルゴリズムで処理し、ユーザーの意図を認識し、知識ベースにアクセスし、機械学習モデルを用いて文脈に合った応答を生成します。現代のチャットボットは、トークナイズ、エンティティ抽出、ダイアログ管理、ニューラルネットワークを組み合わせ、大規模な人間らしい会話を実現しています。
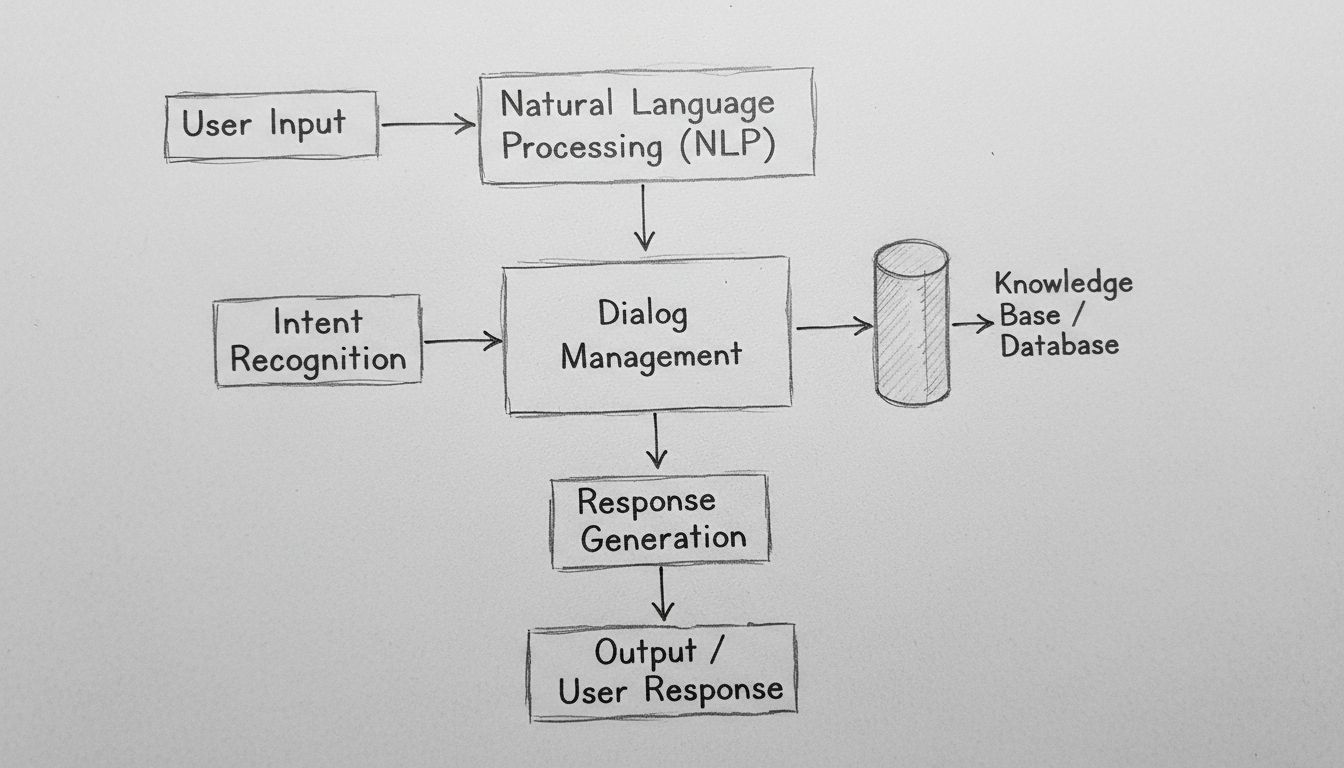
AIチャットボットは、自然言語処理、機械学習、対話管理システムが連携して人間の会話をシミュレートする高度な技術の結晶です。現代のAIチャットボットと対話する際、あなたは多層的な技術システムとやり取りしており、入力は複数の段階を経て処理され、応答として返されます。こうした仕組みのアーキテクチャは、単純なルールベースの分岐から、文脈やニュアンス、感情まで理解できる複雑なニューラルネットワークへと劇的に進化してきました。これらのシステムの仕組みを理解するには、パイプラインを構成する各コンポーネントを詳しく見て、それぞれがどのように連携して自然な会話体験を生み出しているのかを知ることが重要です。
ユーザーのメッセージがAIチャットボットに届くと、最初に通るのが入力処理という重要な工程です。ここで生のテキストは、システムが分析しやすい構造化データへと変換されます。たとえば「パスワードをリセットしたい」と入力しても、チャットボットはすぐに意図を理解するわけではなく、まずメッセージを扱いやすい要素に分解します。このプロセスはトークナイズと呼ばれ、文を単語や意味のある単位(トークン)に分割します。「パスワードをリセットしたい」は[“パスワード”, “を”, “リセット”, “したい”]のようなトークン列になります。この一見単純な工程が基礎となり、各言語要素を独立して分析しつつ、文中での関係性も把握できるようになります。
トークナイズの後は正規化が行われ、すべて小文字化、句読点の削除、一般的なスペルの揺れの補正などによってテキストが標準化されます。これにより「Password Reset」「password reset」「pasword reset」などの表記ゆれも同じ概念と認識されます。さらにストップワード(「の」「は」「を」など意味の薄い共通語)が除去され、計算資源が実際に意味を持つ単語に集中されます。また品詞タグ付けにより、各単語が名詞・動詞・形容詞などどの品詞かも識別されます。これによって、「リセット」が動作を表す動詞であることがわかり、ユーザーが何を望んでいるかの判断に役立ちます。
自然言語処理(NLP)は、チャットボットが人間の言葉を意味レベルで理解するための技術基盤です。NLPは複数の相互連携する手法から成り立ち、テキストから意味を抽出します。**固有表現抽出(NER)**は、メッセージ内の特定のエンティティ(固有名詞、日付、場所、製品名など)を識別します。たとえばパスワードリセットの例では、「パスワード」がチャットボットの知識ベースに関連するシステムエンティティと識別されます。さらに複雑な場面では「12月15日にニューヨークからロンドンにフライトを予約したい」と入力すると、出発地、目的地、日付なども抽出されます。
感情分析も重要なNLP要素で、メッセージに込められた感情を検出します。「3時間待ってもまだ注文が届かない」といった顧客の不満は、チャットボットが適切なトーンで返答したり、優先度を上げたりするために認識すべき情報です。現代の感情分析は、何千もの例文で訓練された機械学習モデルを用いて、テキストの感情(ポジティブ・ネガティブ・中立)や、より細かな「フラストレーション」「困惑」「満足感」なども分類します。こうした感情知能によって、チャットボットは適切な共感や緊急性を持った応答ができ、顧客満足度が大きく向上します。
生のテキストを処理した後、チャットボットはユーザーが実際に何を望んでいるのか、すなわち意図を認識する必要があります。意図認識はチャットボットのアーキテクチャで最も重要な機能の一つで、ユーザーの発言と実際に達成したい目的を結びつけます。システムは何千もの会話例で訓練された機械学習分類器を使い、ユーザー発話をあらかじめ定義された意図にマッピングします。たとえば「パスワードを忘れた」「パスワードをリセットしたい」「ログインできない」「アカウントがロックされた」など、表現は異なっても同じ「password_reset」意図に分類されます。
同時にエンティティ抽出も行い、リクエストの実現に必要な具体的データをユーザーメッセージから特定します。たとえば「プランをプレミアムにアップグレードしたい」と言えば、「アップグレード」(アクション)と「プレミアム」(対象)の2つのエンティティが抽出されます。これらは応答生成のためのパラメーターになります。高度なチャットボットは依存構造解析により、文法関係を理解し、主語や目的語、修飾語などの関係性も把握できます。これにより、複雑な複文や曖昧な表現にも柔軟に対応できます。
ダイアログ管理はチャットボットの「頭脳」にあたり、会話の文脈を保持し、適切な応答を選択します。単純なリスト型応答とは異なり、高度なダイアログマネージャーは会話状態を維持し、これまでの内容や収集した情報、ユーザーの現在の目的を追跡します。これにより、前後の文脈を覚えて適切に参照できる自然な会話が可能になります。たとえば「ロンドンの天気は?」と聞いた後「明日は?」と続ければ、「明日」はロンドンの天気を指すことを理解します。
ダイアログマネージャーはコンテキスト管理を実装し、会話中の関連情報(アカウント情報、過去のリクエスト、ユーザーの好み、現在の話題など)を構造化して保持します。高度なシステムは状態遷移機械や階層型タスクネットワークで会話の流れをモデリングし、どの状態からどの状態へ遷移可能か、どの遷移が妥当かを定義します。たとえばカスタマーサービスのチャットボットなら「挨拶」「問題特定」「トラブルシューティング」「エスカレーション」「解決」といった状態を持ち、会話が論理的に進むよう制御します。
現代のAIチャットボットは、学習データだけで応答を生成するのではなく、知識ベースにアクセスして最新かつ正確な情報を取得します。これは正確性や信頼性を保つ上で不可欠です。「自分の口座残高を知りたい」と聞かれれば、実際の銀行システムに問い合わせて現在の残高を返す必要がありますし、「店舗の営業時間は?」と聞かれた場合も、ビジネス情報DBから最新情報を提供します。
**検索拡張生成(RAG)**は、2025年にさらに重要となった知識連携の高度なアプローチです。RAGはまずユーザーの質問から適切なドキュメントや情報を知識ベースから検索し、その情報を使って文脈に合った応答を生成します。この2段階で、単なる生成型応答より大幅に正確性が向上します。たとえば、特定製品の機能を尋ねられた場合、RAGは製品ドキュメントから該当部分を抽出し、実際の資料に基づいた応答を返します。これは正確性やコンプライアンスが重要な企業利用に特に有効です。
ユーザーの意図を理解し必要な情報を集めた後、チャットボットは適切な応答を生成します。応答生成には複数の手法があり、それぞれ特長と制約があります。テンプレートベース生成は、あらかじめ用意した応答テンプレートに特定情報を埋め込む方式です。たとえば「ご注文番号[ORDER_ID]の商品は[DELIVERY_DATE]に到着予定です。」のようなテンプレートが使われます。信頼性・予測性が高いものの、柔軟性や自然さには限界があります。
ルールベース生成は、特定の意図や抽出エンティティに基づき応答を組み立てるルールを適用します。たとえば「password_reset」意図なら、確認メッセージとリセットページへのリンク、次の手順の案内を含める、といったルールです。テンプレート方式より柔軟ですが、複雑な場面ではルール設計の手間が増えます。
ニューラルネットワークベース生成は、大規模言語モデル(LLM)の力を活用し、極めて自然な新規応答を生み出します。現代のLLMは数十億のテキストデータで訓練されており、言語構造や概念の関係性を学習しています。応答生成時は、直前の単語群から次に来る単語を確率的に予測し、これを繰り返して文を完成させます。柔軟性と自然さに優れる一方、時に「ハルシネーション」(もっともらしいが事実と異なる内容)を生成することがあります。
機械学習によって、チャットボットは時間とともに進化します。現代のチャットボットは静的なルール型ではなく、すべての対話から学習し、言語パターンやユーザー意図の理解を絶えず洗練させていきます。教師あり学習では、人間が意図やエンティティをラベル付けした大量のサンプルでチャットボットを訓練し、異なる意図を見分けるパターンを習得します。
強化学習では、ユーザーからのフィードバックに基づき応答最適化を行います。満足した場合は(明示的な評価や会話継続など)そのパターンを強化し、不満や離脱があれば同様の応答を回避するよう学習します。このフィードバックループでチャットボットは継続的に性能を高めます。さらに人間を介した学習(human-in-the-loop)も導入され、難しい会話を人間がレビューし修正をフィードバックすることで、純粋な自動学習よりも迅速な改善が可能になります。
大規模言語モデル(LLM)は2023年以降、チャットボットの能力を根本的に変革しました。何千億ものトークンで訓練されたモデル(GPT-4、Claude、Geminiなど)は、文脈理解や複雑な指示への対応、幅広い話題での一貫した応答生成が可能です。LLMの強みはトランスフォーマーアーキテクチャにあり、アテンションメカニズムにより文中の離れた単語間の関係も理解し、長い会話でも文脈を維持できます。
ただし、LLMにも課題があります。ハルシネーション(事実でない内容の自信ある生成)、最新情報への対応遅れ、学習データに由来するバイアスなどです。これを補うため、ファインチューニングで特定分野向けにモデルを再訓練したり、プロンプトエンジニアリングで望ましい挙動に誘導する工夫が広がっています。FlowHuntのチャットボットは、こうした先進モデルとガードレールや知識ソース連携を組み合わせ、高精度と信頼性を実現しています。
| 項目 | ルールベース型チャットボット | AI活用型チャットボット | LLM活用型チャットボット |
|---|---|---|---|
| 技術 | 決定木、パターンマッチ | NLP、MLアルゴリズム、意図認識 | 大規模言語モデル、トランスフォーマー |
| 柔軟性 | 事前定義ルールのみ | 表現の揺れにも対応 | 非常に柔軟、未知の入力にも強い |
| 正確性 | 定義シナリオで高い | 適切な訓練で良好 | 優秀だがガードレールが必要 |
| 学習性 | 学習不可 | 対話から学習 | ファインチューニングやフィードバック学習 |
| ハルシネーションリスク | なし | ごくわずか | 対策が必要 |
| 導入期間 | 短い | 中程度 | FlowHunt等なら短期間 |
| 保守性 | ルール更新頻度高い | 中程度 | モデル更新・監視で中程度 |
| コスト | 低い | 中程度 | 中〜高 |
| 最適用途 | FAQ、簡易なルーティング | 顧客対応、リード判定 | 複雑な推論・コンテンツ生成 |
現代のチャットボットはトランスフォーマーアーキテクチャを活用し、自然言語処理を革新しています。トランスフォーマーのアテンション機構は、出力生成時に入力のどの部分に注目すべきかを動的に決定します。「銀行の重役は川岸の侵食を心配していた」という文では、最初の「銀行」は金融機関、次の「川岸」は地形を指すと文脈で判断できます。こうした文脈理解は、従来の逐次処理型アプローチよりはるかに優れています。
マルチヘッドアテンションは、異なる情報面に同時に注目することで、文法関係・意味関係・談話構造など複数の観点から並列処理を実現します。これにより、モデルは言語の意味をより豊かに表現できます。位置エンコーディングもトランスフォーマーの特徴で、単語の順序情報を保持し、並列処理でも語順が意味を持つ言語特性を正しく理解できます。
FlowHuntは、強力なAI機能を保ちつつ技術的な複雑さを抽象化した現代的なチャットボット開発プラットフォームです。チャットボット基盤をゼロから構築する必要はなく、FlowHuntのビジュアルビルダーで非技術者でも会話フローを設計できます。NLPや意図認識、応答生成などの基盤はプラットフォーム側が担い、ユーザーは会話体験設計や業務システム連携に集中できます。
FlowHuntのKnowledge Sources機能により、チャットボットはドキュメント・Webサイト・データベースからリアルタイム情報を取得し、RAG原則で正確性を確保します。またAIエージェント機能を使えば、会話だけでなくデータベース更新、メール送信、予約、ワークフロー実行など自律的なアクションも可能です。情報提供だけでなく、実際にタスクを実行できるのが大きな進化です。CRMやヘルプデスク、各種業務システムとの連携も充実し、データフローやアクションの自動化が実現します。
チャットボット運用効果を測るには、ビジネス目標達成度を示す主要指標を監視することが重要です。意図認識精度は、ユーザーメッセージが正しく分類された割合、エンティティ抽出精度は必要データの正確な抽出率を示します。ユーザー満足度スコア(会話後アンケートなど)や、会話完了率(人手介入なしで問題解決できた割合)も重要指標です。
応答遅延は応答生成の速さを表し、数秒以上遅れると満足度が大きく低下します。エスカレーション率は人間オペレーターへの引き継ぎ割合で、低いほどチャットボット性能が高いといえます。会話あたりコストはAI処理コストと人手のコスト比較です。導入前にベースラインを設定し、運用後も継続的に指標を監視・改善することで価値を最大化できます。
チャットボットは個人情報・金融情報・機密ビジネス情報などの重要データを扱うことが多くなります。データ暗号化で通信内容を保護し、認証機構で正当ユーザー確認、アクセス制御で最小権限原則を徹底します。監査ログの実装も義務付けられ、全会話の記録を保持しコンプライアンスやセキュリティに備えます。
プライバシー・バイ・デザインの原則を適用し、個人データの収集最小化・保存期間制限・利用目的の透明化を徹底しましょう。GDPRやCCPA、HIPAAやPCI-DSSなどの規制順守も必須です。セキュリティアセスメントで脆弱性を洗い出し、適切な対策を講じることも求められます。セキュリティ責任はチャットボットプラットフォームのみならず、知識ベースや連携システム全体に及びます。
チャットボット技術の進化は加速し続けています。マルチモーダルチャットボットは、テキスト・音声・画像・動画を同時に処理・生成できる次世代型です。今後はテキストだけでなく、音声(ハンズフリー用途)、画像(商品質問)、動画(複雑な説明)など、ユーザーの好みや状況に合わせたやり取りが主流になります。感情知能も発展し、単なる感情検出から、より微妙なユーザー心理や状況に応じた適切な感情応答へと進化します。チャットボットはユーザーのフラストレーションや困惑、満足感を識別し、コミュニケーションスタイルも柔軟に調整できるようになります。
プロアクティブサポートも重要な新機能となり、ユーザーのリクエストを待つだけでなく、潜在的な課題を予測して先回りでサポート提供が可能になります。パーソナライゼーションも一層高度化し、ユーザーごとの履歴や好み、文脈に応じて会話・提案・支援内容を最適化します。自律システムとの連携により、RPAやIoTデバイスなどと協調し、複数システムをまたぐ複雑なタスクも自動オーケストレーションが可能です。
AIチャットボットの仕組みを理解すれば、なぜ多くの業界で不可欠なビジネスツールとなったかが分かります。自然言語処理・機械学習・ダイアログ管理・知識連携の高度な連携により、複雑な業務も自然な人間的インタラクションで自動処理できます。FlowHuntのようなプラットフォームを活用し、技術的複雑さを隠蔽しつつ高度な能力を維持すれば、顧客満足の向上・運用コスト削減・対応速度向上など大きな競争優位が得られます。
技術進化は急速で、大規模言語モデル、マルチモーダル対応、自律エージェントなどの登場で可能性はさらに拡大します。チャットボットの導入は一度きりのプロジェクトではなく、継続的な学習・最適化・強化によって価値が高まる「進化する能力」ととらえましょう。最も成功する導入事例は、強力なAI技術と緻密な会話設計、精度や安全性を担保するガードレール、業務システム連携による実行力を組み合わせたものです。2025年以降、チャットボットは顧客・従業員が企業とやり取りする主要なインターフェイスとなるため、この分野への投資がビジネス成功の鍵となるでしょう。
繰り返しの顧客対応に手間をかけるのはやめましょう。FlowHuntのノーコードAIチャットボットビルダーなら、知的で自律的なチャットボットを簡単に作成でき、カスタマーサービスやリード獲得、サポート業務を24時間365日自動化します。数週間ではなく、数分で導入可能です。
AIチャットボットをゼロから構築する方法を、包括的なガイドで解説。FlowHuntのノーコードプラットフォームを活用し、最適なツール・フレームワーク・プロセスを知り、インテリジェントな会話型AIシステムを作成しましょう。...
この総合ガイドでAIチャットボットの活用をマスターしましょう。効果的なプロンプト作成法、ベストプラクティス、2025年にAIチャットボットを最大限活用する方法を学べます。プロンプトエンジニアリング戦略や高度な対話手法も紹介。...
チャットボットが属するAI領域を解説。自然言語処理、機械学習、ディープラーニング、会話型AIなど、2025年の最新チャットボットを支える技術を学びましょう。...