AIモデルの精度とAIモデルの安定性
機械学習におけるAIモデルの精度と安定性の重要性について解説します。これらの指標が詐欺検出、医療診断、チャットボットなどのアプリケーションにどのような影響を与えるか、信頼性の高いAIパフォーマンスを実現するための手法もご紹介します。...
1 分で読める
AI
Model Accuracy
+5
2025年におけるAIヘルプデスクチャットボットの精度を測定する包括的な方法を学びましょう。FlowHuntで、適合率、再現率、F1スコア、ユーザー満足度指標、先進的な評価手法を解説します。
AIヘルプデスクチャットボットの精度は、適合率や再現率の計算、混同行列、ユーザー満足度スコア、解決率、高度なLLMベースの評価手法など複数の指標で測定します。FlowHuntは、精度の自動評価やパフォーマンス監視のための包括的なツールを提供します。
AIヘルプデスクチャットボットの精度を測定することは、顧客からの問い合わせに対して信頼性が高く有用な回答を提供するために不可欠です。単純な分類タスクとは異なり、チャットボットの精度は複数の側面を総合的に評価する必要があり、パフォーマンスの全体像を把握するためにはそれらを組み合わせて評価します。このプロセスでは、チャットボットがユーザーの質問をどれだけ正確に理解し、正しい情報を提供し、効果的に問題を解決し、やりとりを通じてユーザー満足度を維持できているかを分析します。包括的な精度測定戦略は、定量的指標と定性的フィードバックを組み合わせて、強みと改善が必要な点を明らかにします。
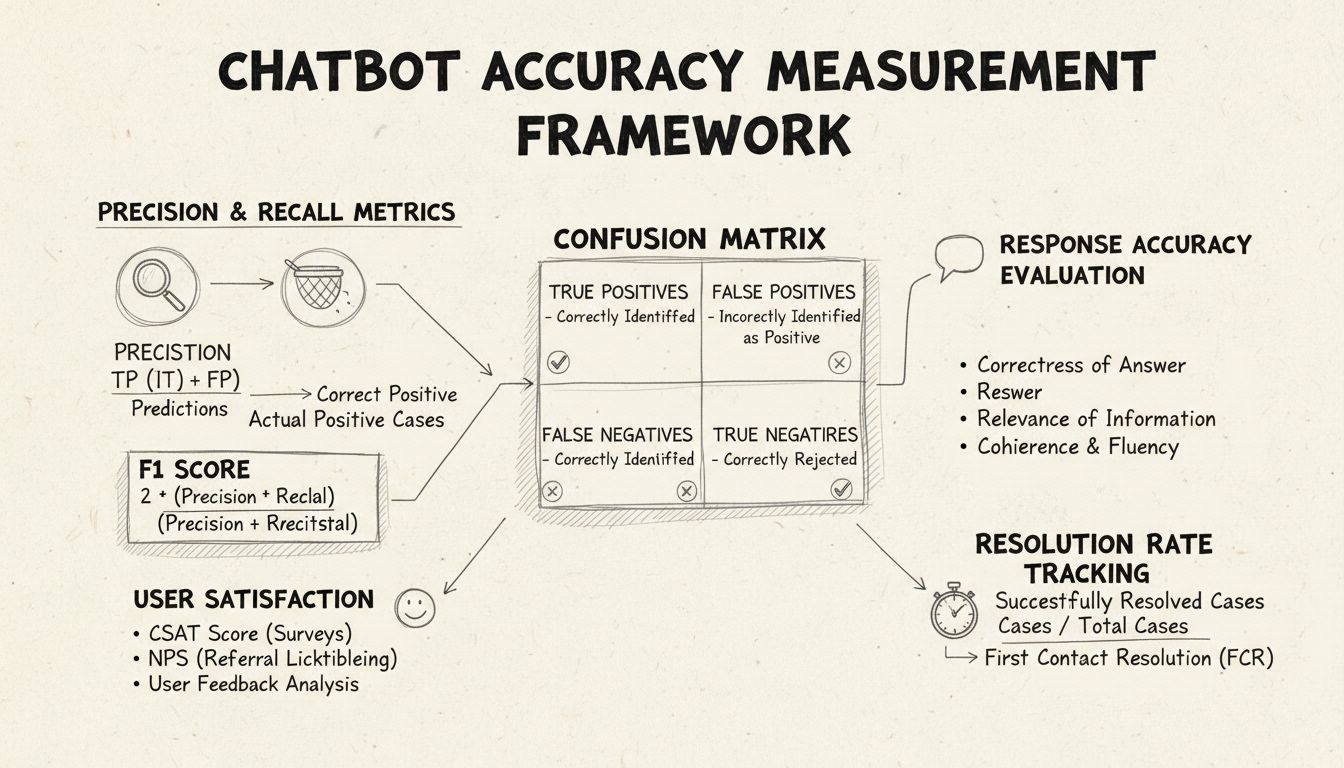
適合率と再現率は混同行列から導き出される基本的な指標であり、チャットボットのパフォーマンスの異なる側面を測定します。適合率は、チャットボットが提供した全回答のうち正解であった割合を示し、計算式は「適合率 = 真陽性 / (真陽性 + 偽陽性)」です。この指標は「チャットボットが回答したとき、その回答はどれだけ正しいか?」という問いに答えます。適合率が高ければ、チャットボットが誤った情報を滅多に出さないことになり、ヘルプデスクの信頼性維持に不可欠です。
再現率(感度とも呼ばれる)は、チャットボットが本来回答すべき全回答のうち、実際に正解を返した割合を示し、「再現率 = 真陽性 / (真陽性 + 偽陰性)」で計算されます。この指標は、チャットボットが正当に顧客の問題を認識し、適切に対応できているかを示します。ヘルプデスクにおいて再現率が高いと、顧客が「本当は対応できるはずなのに無理と言われる」ような事態を防げます。適合率と再現率はトレードオフの関係にあり、どちらかに最適化するともう一方が下がることもあるため、自社のビジネス優先度に応じてバランスを取る必要があります。
F1スコアは、適合率と再現率のバランスを取った単一の指標で、調和平均として計算されます(F1 = 2 × (適合率 × 再現率) / (適合率 + 再現率))。これは、不均衡なデータセットで有用な統合パフォーマンス指標となります。例えば、チャットボットが1,000件の定型質問と50件の複雑なエスカレーションを扱う場合、多数派のクラスに偏ることなく全体のパフォーマンスを評価できます。F1スコアは0から1の範囲で、1が完全な適合率・再現率を示すため、利害関係者にも直感的に伝わります。
混同行列は、チャットボットのパフォーマンスを4つのカテゴリに分類する基本ツールです。真陽性(有効な質問への正解)、真陰性(範囲外質問への正しい拒否)、偽陽性(誤答)、偽陰性(支援の機会を逃す)に分けて分析できます。これにより、失敗パターンが明らかになり、ピンポイントの改善が可能になります。例えば、混同行列で請求関連の質問に偽陰性が多ければ、訓練データの請求分野が不足していると判断できます。
| 指標 | 定義 | 計算方法 | ビジネスへの影響 |
|---|---|---|---|
| 真陽性 (TP) | 有効な質問への正答 | 直接カウント | 顧客の信頼を構築 |
| 真陰性 (TN) | 範囲外質問の正しい拒否 | 直接カウント | 誤情報防止 |
| 偽陽性 (FP) | 誤った回答を提供 | 直接カウント | 信用低下 |
| 偽陰性 (FN) | 支援機会の喪失 | 直接カウント | 満足度低下 |
| 適合率 | 正答予測の質 | TP / (TP + FP) | 信頼性指標 |
| 再現率 | 実際の正答カバー率 | TP / (TP + FN) | 完全性指標 |
| 正確度 | 全体の正確さ | (TP + TN) / 総数 | 総合パフォーマンス |
応答の正確性は、チャットボットがユーザーの質問に対して事実に即した正しい情報をどれだけ提供できるかを測定します。単なるパターンマッチではなく、内容が正確かつ最新で、文脈に適しているかを評価します。手動レビューでは、人間の評価者が会話サンプルを抽出し、チャットボットの応答を正答集と比較します。自動比較ではNLP技術を用いて、システムに保存された期待回答と照合しますが、異なる表現でも正解となる場合の誤判定に注意が必要です。
応答の関連性は、チャットボットの回答がユーザーの質問に実際に対応しているかを評価します。完全な正答でなくても、問題解決に向けて会話を前進させていれば有用とみなします。NLPのコサイン類似度などで質問と応答間の意味的類似度をスコア化できます。さらに、やりとりのたびに「役に立った/立たなかった」などユーザーによる評価を集めることで、直接的な関連性の指標になります。これらのフィードバックは継続的に収集・分析し、チャットボットが得意・不得意な領域を明らかにしましょう。
顧客満足度スコア(CSAT)は、ユーザーアンケートによってチャットボットとのやりとりへの満足度を1~5段階などで測定します。各対話後に満足度を尋ねることで、即座にニーズが満たされたかどうかのフィードバックが得られます。CSATが80%以上なら高パフォーマンス、60%未満なら問題ありと判断されます。CSATはシンプルかつ直接的ですが、課題の難易度やユーザー期待など精度以外の要素にも影響されます。
ネットプロモータースコア(NPS)は、「このチャットボットを同僚に薦めたいか?」を0~10で尋ね、その回答から推奨者(9-10)、中立者(7-8)、批判者(0-6)を分類し、「NPS = (推奨者 - 批判者) / 回答者総数 × 100」で算出します。NPSは長期的な顧客ロイヤルティと相関が高く、ポジティブな体験を提供できているかを示します。50以上なら優秀、マイナスなら重大な問題を示します。
感情分析は、チャットボットとの対話前後のユーザーメッセージの感情を分類し、満足度を測定します。高度なNLP技術でメッセージをポジティブ・ニュートラル・ネガティブに分類し、対話中に満足度が向上したか、不満が増えたかを可視化します。ポジティブな変化は問題が解決された証拠であり、ネガティブな変化は対応の失敗やユーザーのフラストレーションを意味します。従来の精度指標では捉えきれない体験の質を補完できます。
一次対応解決率(FCR)は、チャットボットが人間のエージェントへのエスカレーションなしに問題を解決できた割合です。この指標は運用効率と顧客満足度に直結します。70%以上なら優秀、50%未満なら知識不足や対応力不足の可能性があります。FCRを課題カテゴリごとに追跡することで、チャットボットが得意な領域・人手が必要な領域を明確にし、訓練やナレッジ拡充に活かせます。
エスカレーション率はチャットボットが人間エージェントに対応を引き継ぐ頻度、フォールバック頻度は「理解できません」「質問を言い換えてください」など一般的な回答に頼る回数です。エスカレーション率30%以上は多くの場面で知識・自信が不足していること、フォールバック頻度が高い場合は分類精度や訓練データ不足の可能性を示します。これらの指標により、知識拡充・モデル再訓練・NLP部品改善など具体的な対応策を特定できます。
応答時間はチャットボットがユーザーのメッセージにどれだけ早く返答するかを示し、通常ミリ秒~数秒で計測します。3~5秒以上遅延すると満足度が大きく低下します。対応時間はユーザーが問い合わせてから解決またはエスカレーションまでの総所要時間で、効率性を示します。対応時間が短ければ理解・解決が迅速、長ければ確認や言い直しが多い、または複雑な課題に苦戦していることを示します。課題カテゴリごとに個別に追跡しましょう。
LLMジャッジ法は、大規模言語モデル(LLM)が他のAIシステムの出力を評価する高度な手法です。精度、関連性、一貫性、流暢性、安全性、完全性、トーンなど複数の品質軸を同時に評価でき、手動レビューのスケール代替として有効です。研究によると、LLMジャッジは最大85%の一致率で人間評価と整合することが示されています。この手法では、評価基準を定義し、具体例つきのプロンプトを作成し、ユーザーの質問とチャットボットの応答をLLMジャッジに渡して、構造化スコアや詳細フィードバックを得ます。
LLMジャッジ法では「単一出力評価」(参照なし/参照あり比較)や「ペアワイズ比較」(2つの出力を比較し優劣を判定)が可能です。これにより、絶対的パフォーマンスと、バージョン間の相対的な改善の両方を評価できます。FlowHuntプラットフォームは、ドラッグ&ドロップUIやChatGPT・Claudeとの連携、CLIツールキットによる詳細レポート・自動評価をサポートしています。
単なる正確度計算にとどまらず、混同行列の詳細分析は失敗パターンを明確にします。例えば、請求関連の質問を技術サポートと誤認する場合、訓練データの不均衡や特定ドメインの意図認識ミスが明らかになります。課題カテゴリごとに混同行列を作成すれば、無差別なモデル再訓練ではなく、ピンポイントの改善が可能です。
A/Bテストは異なるチャットボットバージョンを比較し、主要指標でどちらが優れているかを判断する手法です。応答テンプレートやナレッジベース、言語モデルの構成違いを比較できます。トラフィックの一部を各バージョンに振り分け、「一次解決率」「CSAT」「応答正確性」などの指標を比較し、改善策の効果をデータで確認できます。A/Bテストは十分な期間実施し、ユーザー質問の自然な変動を捉え、統計的有意性を確保しましょう。
FlowHuntは、AIヘルプデスクチャットボットの構築・展開・評価を一体化したプラットフォームで、高度な精度測定機能を備えています。ビジュアルビルダーにより非技術者でも高度なチャットボットフローを作成でき、AIコンポーネントはChatGPTやClaudeなどの先進言語モデルと統合可能です。FlowHuntの評価ツールキットでは、LLMジャッジ法の実装、独自の評価基準定義、全会話データセットにわたる自動評価が行えます。
FlowHuntで精度測定を実践するには、まず自社のビジネス目標に合った評価基準(精度・速度・満足度・解決率など)を設定します。高品質/低品質回答の具体例を含めた詳細プロンプトで評価用LLMを構成し、会話データセットのアップロードやライブ連携を行い、評価を実行して詳細レポートを取得します。FlowHuntダッシュボードでは、チャットボットパフォーマンスをリアルタイムで可視化し、課題の早期発見や改善効果の検証が可能です。
改善実施前にベースライン測定を行い、効果を評価する基準点を確立しましょう。定期的ではなく継続的に測定し、データドリフトやモデル劣化によるパフォーマンス低下を早期に検知します。ユーザー評価・訂正フィードバックを自動的に学習プロセスに組み込み、精度を継続的に向上させましょう。課題カテゴリ・ユーザー種別・期間別に指標をセグメント化することで、全体平均だけでなく、注力すべき具体的領域を特定します。
評価データセットは実際のユーザー質問と期待回答を反映するものを用い、現実離れしたテストケースは避けましょう。自動指標は定期的に人間評価と照合し、測定システムの品質を維持します。評価手法や指標定義を明確に文書化し、継続的かつ一貫した評価・関係者への説明を可能にします。最後に、各指標ごとにビジネス目標に沿ったパフォーマンス目標を定め、継続的改善への責任と明確な最適化目標を設定しましょう。
FlowHuntの高度なAIオートメーションプラットフォームなら、精度測定ツールやLLMベースの評価機能を使って、高性能チャットボットの作成・展開・評価が可能です。
機械学習におけるAIモデルの精度と安定性の重要性について解説します。これらの指標が詐欺検出、医療診断、チャットボットなどのアプリケーションにどのような影響を与えるか、信頼性の高いAIパフォーマンスを実現するための手法もご紹介します。...
機能テスト、パフォーマンステスト、セキュリティテスト、ユーザビリティテストを含む包括的なAIチャットボットのテスト戦略を学びましょう。正確な応答と優れたユーザー体験を実現するためのベストプラクティス、ツール、フレームワークを紹介します。...
2025年にAIチャットボットの真正性を検証するための実証済み手法を学びましょう。技術的な検証方法、セキュリティチェック、本物のAIシステムを見極めて詐欺的なチャットボットから身を守るためのベストプラクティスを紹介します。...