
情報検索
情報検索は、AI、NLP、機械学習を活用して、ユーザーの要件を満たすデータを効率的かつ正確に検索します。ウェブ検索エンジン、デジタルライブラリ、エンタープライズソリューションの基盤となっており、曖昧さやアルゴリズムバイアス、スケーラビリティなどの課題に対応し、今後は生成AIや深層学習への注目が高まっています。...
1 分で読める
Information Retrieval
AI
+4

AI検索は、機械学習とベクトル埋め込みを活用して検索意図やコンテキストを理解し、正確なキーワード一致を超えた高い関連性の結果を提供します。
AI検索は、機械学習を用いて検索クエリの文脈や意図を理解し、それらを数値ベクトルに変換することで、より正確な結果を導き出します。従来のキーワード検索とは異なり、AI検索は意味的な関係性を解釈できるため、多様なデータタイプや言語にも有効です。
AI検索(セマンティック検索やベクトル検索とも呼ばれる)は、機械学習モデルを活用して検索クエリの意図や文脈的な意味を把握する検索手法です。従来のキーワード検索と異なり、データやクエリを「ベクトル」もしくは「埋め込み」と呼ばれる数値表現に変換し、異なるデータ同士の意味的な関係性を理解できるため、完全に一致するキーワードがなくても、より関連性が高く正確な結果を提供できます。
AI検索は検索技術の大きな進化を表します。従来の検索エンジンはキーワード一致に大きく依存し、クエリや文書内の特定の語句の有無で関連性を判断していました。一方、AI検索は、機械学習モデルによってクエリやデータの根本的な文脈や意味を捉えます。
テキスト・画像・音声などの非構造データを高次元ベクトルに変換することで、AI検索は異なるコンテンツ同士の類似性を数値的に計測します。このアプローチにより、検索クエリに使われていないキーワードでも、文脈的に関連した結果を返すことができます。
主な要素:
AI検索の中心となるのがベクトル埋め込みの概念です。ベクトル埋め込みは、テキストや画像などのデータの意味的特徴を、多次元空間上の数値ベクトルとして表現する手法です。意味的に類似するデータは、ベクトル空間でも近い位置に配置されます。
仕組み:
例:
従来のキーワード検索エンジンは、クエリ内の語句と文書内の語句を一致させることで結果を返します。インバーテッドインデックスや出現頻度などの手法に依存しています。
キーワード検索の限界:
AI検索の優位点:
| 項目 | キーワード検索 | AI検索(セマンティック/ベクトル) |
|---|---|---|
| 一致方法 | キーワードの完全一致 | 意味的な類似性 |
| 文脈認識 | 限定的 | 高い |
| 同義語対応 | 手動で辞書作成が必要 | 埋め込みにより自動認識 |
| スペルミス対応 | あいまい検索なしでは弱い | 意味的文脈で柔軟に対応 |
| 意図理解 | ほとんどなし | 大きい |
セマンティック検索は、ユーザーの意図やクエリの文脈的意味を理解するAI検索の中核的な応用例です。
プロセス:
主な技術:
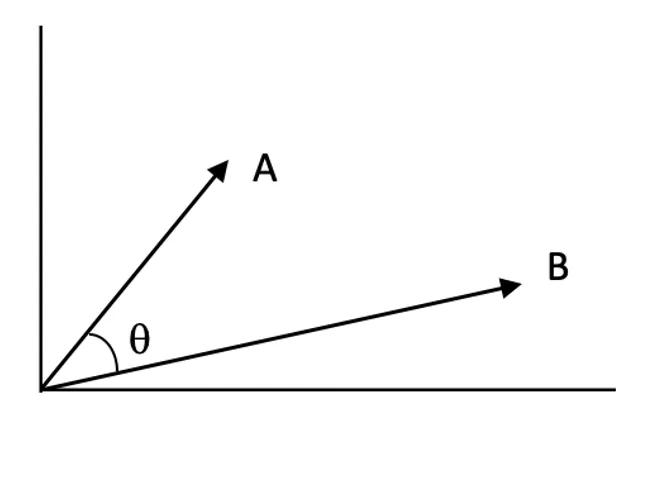
類似度スコア:
ベクトル空間内で二つのベクトルがどれだけ近いかを数値化したもの。スコアが高いほど関連度が高いことを示します。
近似最近傍(ANN)アルゴリズム:
高次元空間で完全な最近傍探索は計算コストが高いため、ANNアルゴリズムで効率的に近似検索を行います。
AI検索は、単なるキーワード一致を超えたデータ解釈能力によって、さまざまな業界で幅広い応用が可能です。
概要: クエリの意図を解釈し、文脈的に関連性の高い検索結果を提供します。
例:
概要: ユーザーの嗜好や行動を理解し、最適なコンテンツや商品を個別に推薦
例:
概要: ユーザーの質問を理解し、文書から適切な情報を抽出・回答
例:
概要: 画像・音声・動画など非構造データも埋め込みでインデックス化し検索が可能
例:
AI自動化やチャットボットにAI検索を組み込むことで、応答精度や体験が大幅に向上します。
メリット:
実装ステップ:
ユースケース例:
AI検索には多くの利点がありますが、以下の課題も存在します。
対策例:
AIにおけるセマンティック・ベクトル検索は、従来のキーワード検索やファジー検索に代わる強力な手法として登場し、クエリの文脈や意味を理解することで検索結果の関連性・精度を大きく向上させています。
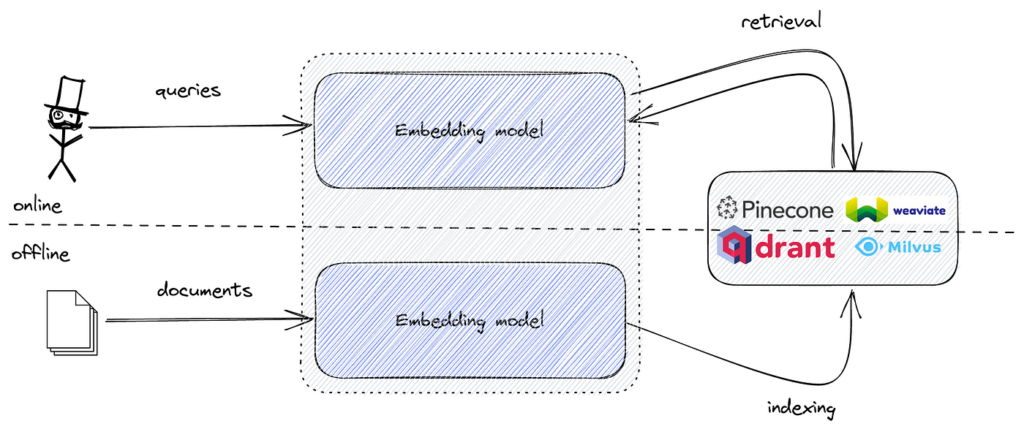
セマンティック検索の実装では、テキストデータを意味的特徴を捉えたベクトル埋め込みに変換します。これらの埋め込みは高次元の数値表現となり、クエリ埋め込みと最も類似したものを効率よく見つけるためには、高次元空間での類似検索に特化したツールが必要です。
FAISSは、そのための最適なアルゴリズムやデータ構造を提供します。セマンティック埋め込みとFAISSを組み合わせることで、大規模データでも低遅延で高性能なセマンティック検索エンジンを構築できます。
FAISSによるセマンティック検索は、以下のステップで行います。
各ステップを詳しく見てみましょう。
データセット(例:記事、サポートチケット、商品説明など)を準備します。
例:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
必要に応じてテキストをクリーニング・整形します。
Hugging Face(transformersやsentence-transformers)などの事前学習済みTransformerモデルを使い、テキストをベクトル埋め込みに変換します。
例:
from sentence_transformers import SentenceTransformer
import numpy as np
# 事前学習済みモデルをロード
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 文書ごとに埋め込みを生成
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
埋め込みを格納し、効率的な類似検索を可能にするFAISSインデックスを作成します。
例:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2はL2(ユークリッド)距離による全探索ユーザーのクエリを埋め込み化し、最近傍検索を実行します。
例:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
インデックスから最も関連性の高い文書を取得・表示します。
例:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
期待される出力:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISSにはいくつかのインデックスタイプがあります。
Inverted File Index(IndexIVFFlat)の使用例:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
正規化と内積検索:
テキストデータにはコサイン類似度が有効な場合が多く、…
AI検索は、機械学習やベクトル埋め込みを用いてクエリの意図や文脈的意味を理解し、従来のキーワード検索よりも正確かつ関連性の高い結果を提供する最新の検索手法です。
従来のキーワード検索が正確な一致に依存するのに対し、AI検索はクエリの意味的関係や意図を解釈するため、自然言語や曖昧な入力にも有効です。
ベクトル埋め込みは、テキストや画像など様々なデータの意味的特徴を数値ベクトルとして表現するもので、検索エンジンが異なるデータ間の類似性や文脈を計測できるようにします。
AI検索は、ECサイトのセマンティック検索、ストリーミングのパーソナライズ推薦、カスタマーサポートの質問応答、非構造データの閲覧、研究や企業における文書検索などで活用されています。
代表的なツールには、高速なベクトル類似検索のためのFAISS、スケーラブルな埋め込み格納・検索のためのPinecone、Milvus、Qdrant、Weaviate、Elasticsearch、Pgvectorなどのベクトルデータベースがあります。
AI検索を統合することで、チャットボットや自動化システムはユーザーの意図をより深く理解し、文脈に合った回答や動的でパーソナライズされた応答を提供できます。
主な課題として、高い計算リソースの必要性、モデルの解釈性の複雑さ、高品質なデータの必要性、機密情報のプライバシーやセキュリティの確保などが挙げられます。
FAISSは高次元ベクトル埋め込みの効率的な類似検索のためのオープンソースライブラリで、大規模なデータセットにも対応可能なセマンティック検索エンジンの構築によく利用されています。
情報検索は、AI、NLP、機械学習を活用して、ユーザーの要件を満たすデータを効率的かつ正確に検索します。ウェブ検索エンジン、デジタルライブラリ、エンタープライズソリューションの基盤となっており、曖昧さやアルゴリズムバイアス、スケーラビリティなどの課題に対応し、今後は生成AIや深層学習への注目が高まっています。...
FlowHuntをBaidu AI検索と連携することで、大規模言語モデルによるインテリジェントでリアルタイムなウェブ検索を実現します。カスタムペルソナ設定、モデル選択、クエリリライト、ターゲット検索など、業界特化型ワークフローや最適化された顧客体験に最適な高度なAI機能を解放します。...
FlowHuntのマルチソースAIアンサージェネレーターで、複数のフォーラムやデータベースからリアルタイムかつ信頼性の高い情報を取得できる強力なツールをご体験ください。学術、医療、一般的な質問に最適で、透明性のために出典へのリンクを付与し、必要に応じて接続先ツールもカスタマイズ可能です。...

