AIインテント分類の理解
AIインテント分類の基礎、手法、実際の応用例、課題、そして人間と機械の対話を強化するための今後のトレンドについて学びましょう。...
1 分で読める
AI
Intent Classification
+4
AI分類器は、入力データにクラスラベルを割り当てる機械学習アルゴリズムの一種です。つまり、過去のデータから学習したパターンに基づき、データをあらかじめ定義されたクラスに分類します。AI分類器は人工知能やデータサイエンス分野の基礎的なツールであり、複雑なデータセットを解釈・整理し、システムが的確な意思決定を行えるようにします。
分類は教師あり学習の一種で、ラベル付けされた訓練データからアルゴリズムが学習し、未知データのクラスラベルを予測します。目的は、新しい観測値を正しいカテゴリに正確に割り当てるモデルを作成することです。このプロセスは、メールのスパム検出から医療診断まで、さまざまな用途で重要です。
分類タスクは、クラスラベルの数や性質に応じて分類されます。
バイナリ分類は、データを2つのクラスのいずれかに分類する最もシンプルな形式です。はい/いいえ、真/偽などのシナリオで利用されます。
例:
多クラス分類は、データが3つ以上のクラスに分類されるケースです。
例:
マルチラベル分類では、1つのデータポイントが複数のクラスに同時に属することができます。
例:
不均衡分類は、クラスの分布が偏っていて、あるクラスが他のクラスより大幅に多い場合に発生します。
例:
AI分類器を構築するアルゴリズムには、独自のアプローチや強みがあります。
名前に「回帰」と付きますが、主にバイナリ分類に用いられます。
決定木は、特徴量による分岐を繰り返してクラスラベルを決定するツリー型のモデルです。
SVMは線形・非線形の分類で威力を発揮し、高次元空間でも効果的です。
ニューラルネットワークは人間の脳を模倣し、複雑なパターンの学習に優れます。
ランダムフォレストは複数の決定木を組み合わせて、過学習を抑えつつ予測精度を向上させます。
AI分類器を汎用性高く仕上げるには、いくつかの段階を踏む必要があります。
高品質な訓練データが不可欠です。データは以下を満たす必要があります。
訓練中、分類器はデータのパターンを学びます。
訓練後、以下の指標で性能を評価します。
AI分類器は、さまざまな業界で自動化と効率化を実現しています。
金融機関が不正取引の検出に分類器を利用。
分類器でターゲットを絞ったマーケティング戦略が可能に。
画像内の物体や人物、パターンを識別。
大量の自然言語データの分析・処理を自動化。
ユーザーの入力意図を理解し、適切に応答するために分類器を利用。
分類は機械学習の根幹であり、多くの高度なアルゴリズムやシステムの基礎となっています。
AI分類器は、機械学習や人工知能の根幹となるツールであり、複雑なデータを分類・解釈することでシステムの自動化や意思決定を支えます。分類器の仕組みや分類問題の種類、用いられるアルゴリズムを理解することで、組織は自動化や意思決定の高度化、ユーザー体験の向上といった恩恵を得られます。
不正検知からインテリジェントチャットボットの実現まで、分類器は現代AIのさまざまな応用に不可欠です。データから学び進化し続ける能力は、情報と自動化が主導する現代社会で極めて重要な存在となっています。
AI分類器に関する研究
AI分類器は、学習したパターンに基づきデータをあらかじめ定義されたクラスに分類する、人工知能分野の重要な構成要素です。近年の研究では、AI分類器の能力・限界・倫理的側面など多角的な議論が行われています。
「Weak AI” is Likely to Never Become “Strong AI”, So What is its Greatest Value for us?」Bin Liu著(2021)
この論文は「弱いAI」と「強いAI」の違いについて論じ、AIは画像分類やゲームなど特定のタスクで優れている一方で、汎用知能には遠い現状を指摘しています。また、現状の弱いAIの価値についても言及しています。続きを読む
「The Switch, the Ladder, and the Matrix: Models for Classifying AI Systems」Jakob Mokanderら(2024)
本論文は、AIシステムの分類モデルとしてSwitch・Ladder・Matrixの3つを提案し、それぞれの強みと弱みを挙げつつ、倫理原則と実践のギャップを埋める枠組みを提示しています。続きを読む
「Cognitive Anthropomorphism of AI: How Humans and Computers Classify Images」Shane T. Mueller著(2020)
人間とAIによる画像分類の違いを、認知的擬人化(人がAIに人間的知能を期待する現象)という観点で考察。説明可能AIなど、人間とAIの認知的ギャップを埋める方策にも触れています。続きを読む
「An Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers」Hui Xieら(2019)
AI分類器の圧縮特性と敵対的脆弱性の理論的仮説を提示し、AIシステムの堅牢化に向けた洞察を与えています。続きを読む
AI分類器は、入力データにクラスラベルを割り当て、過去データから学習したパターンに基づき、データをあらかじめ定義されたクラスに分類する機械学習アルゴリズムです。
分類問題には、バイナリ分類(二値分類)、多クラス分類(3つ以上のクラス)、マルチラベル分類(1データに複数ラベル)、不均衡分類(クラス分布が偏っている)などがあります。
一般的な分類アルゴリズムには、ロジスティック回帰、決定木、サポートベクターマシン(SVM)、ニューラルネットワーク、ランダムフォレストなどがあります。
AI分類器は、スパム検出、医療診断、不正検知、画像認識、顧客セグメンテーション、感情分析、チャットボットやAIアシスタントの実現などに使われています。
AI分類器は、精度・適合率・再現率・F1スコア・混同行列などの指標を用いて、未知データに対する性能が評価されます。
AIインテント分類の基礎、手法、実際の応用例、課題、そして人間と機械の対話を強化するための今後のトレンドについて学びましょう。...
AIインテント分類が、ユーザーとテクノロジーのやり取りを強化し、カスタマーサポートを向上させ、先進的なNLPと機械学習技術によってビジネスオペレーションを効率化する上で重要な役割を果たすことを発見しましょう。...
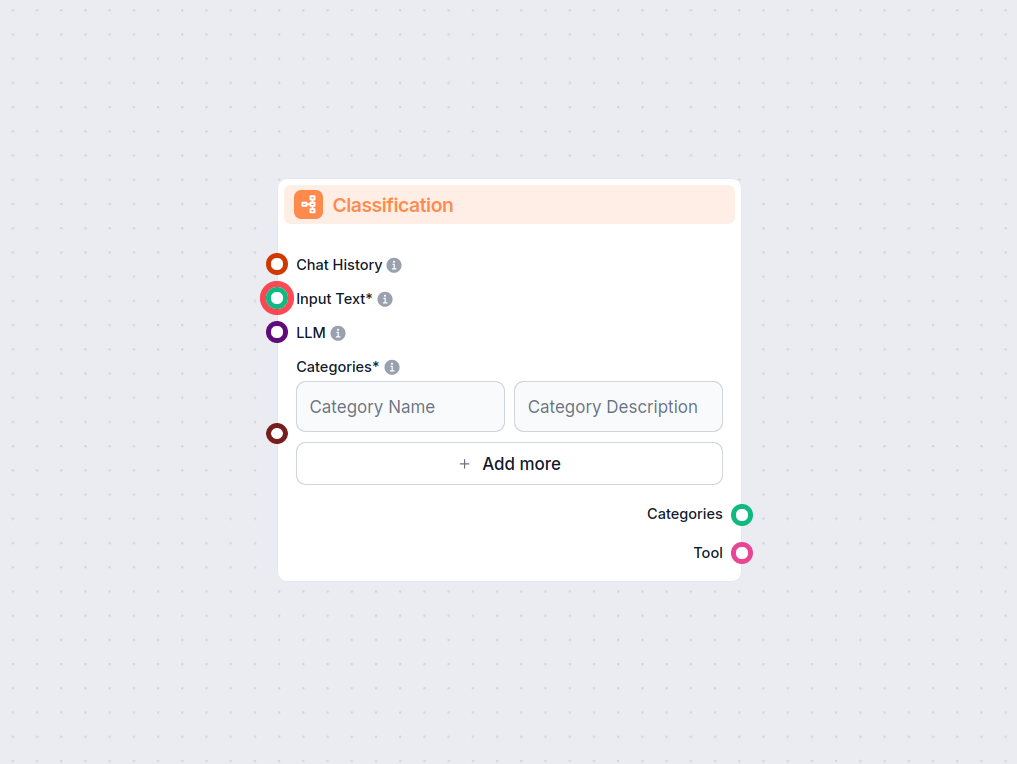
FlowHuntのテキスト分類コンポーネントでワークフローに自動テキスト分類を導入しましょう。AIモデルを活用して、入力テキストをユーザー定義のカテゴリに簡単に分類できます。チャット履歴やカスタム設定のサポートにより、文脈に沿った正確な分類が可能となり、ルーティング、タグ付け、コンテンツモデレーションなどのタスクに最適...