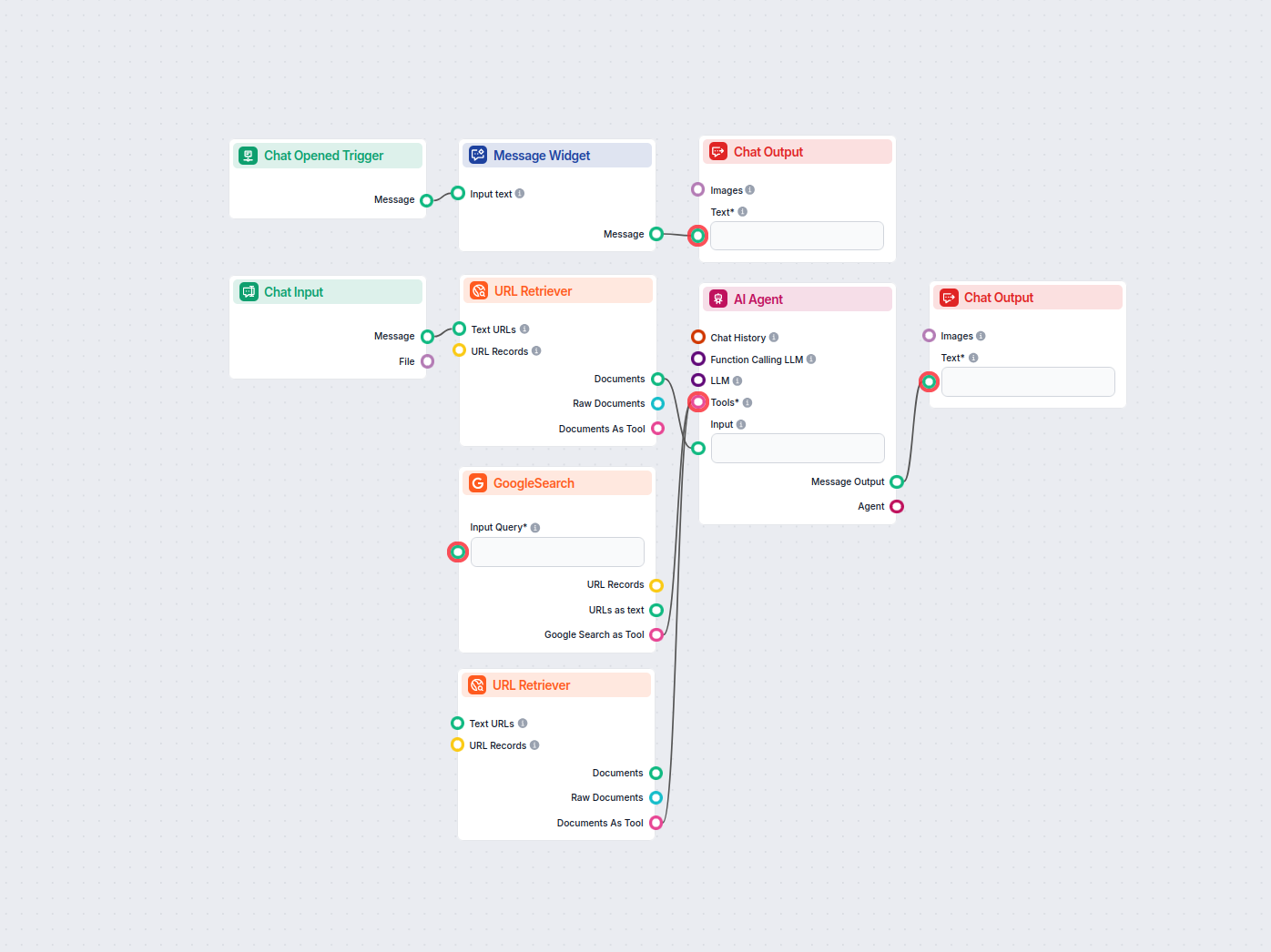
Sitemap から llms.txt AI 変換ツール
任意の sitemap.xml を AI を使って構造化された llms.txt 形式に変換します。このワークフローは、サイトマップから URL を取得し、その内容を取得・処理し、AI エージェントを活用して AI トレーニングやナレッジインジェストに適した最適化された llms.txt ファイルを生成します。...
1 分で読める
llms.txtは、ウェブサイトのコンテンツを簡素化してLLM向けに構造化された機械可読インデックスを提供し、AIによる対話を強化します。
llms.txtファイルは、ウェブサイトから大規模言語モデル(LLM)が情報をアクセス・理解・処理する方法を向上させるために設計された、標準化テキストファイル(Markdown形式)です。ウェブサイトのルートパス(例:/llms.txt)に設置されるこのファイルは、推論時に機械が消費しやすいように構造化・要約されたコンテンツのキュレーションインデックスとして機能します。主な目的は、ナビゲーションメニューや広告、JavaScriptなどの従来のHTMLコンテンツの複雑さを回避し、人間と機械の両方が読みやすい明確なデータを提示することです。
robots.txtやsitemap.xmlなどの他のウェブ標準とは異なり、llms.txtはChatGPT、Claude、Google Geminiのような推論エンジン専用に設計されています。これは、AIシステムがコンテキストウィンドウ内で最も関連性が高く価値のある情報のみを取得できるように支援します。多くのLLMはウェブサイト全体のコンテンツを処理するにはコンテキストウィンドウが小さすぎるため、llms.txtが有効です。
このコンセプトは、Answer.AI共同創設者のJeremy Howardによって2024年9月に提案されました。複雑なウェブサイトとLLMの間で発生する非効率を解決するために生まれたものです。従来のHTMLページ処理は、計算リソースの無駄やコンテンツの誤解釈を招きがちでした。llms.txtのような標準を用いることで、ウェブサイト管理者はAIシステムによる正確かつ効率的なパースを保証できます。
llms.txtファイルは、主にAIやLLM駆動の対話領域で実用的な役割を果たします。その構造化フォーマットにより、LLMがウェブサイトのコンテンツを効率的に取得・処理でき、コンテキストウィンドウのサイズや処理効率の限界を克服できます。
llms.txtは、人間と機械の両方に互換性のあるMarkdownベースのスキーマに従います。主な構成は以下の通りです。
例:
# Example Website
> 人工知能に関する知識やリソースを共有するプラットフォーム。
## Documentation
- [クイックスタートガイド](https://example.com/docs/quickstart.md): 初心者向けの導入ガイド。
- [APIリファレンス](https://example.com/docs/api.md): 詳細なAPIドキュメント。
## Policies
- [利用規約](https://example.com/terms.md): プラットフォーム利用の法的ガイドライン。
- [プライバシーポリシー](https://example.com/privacy.md): データ取扱とユーザープライバシーについて。
## Optional
- [会社沿革](https://example.com/history.md): 主なマイルストーンと実績のタイムライン。
FastHTMLは、サーバーレンダリング型ウェブアプリケーションを構築するPythonライブラリで、llms.txtを利用してドキュメントへのアクセスを簡素化しています。ファイルにはクイックスタートガイドやHTMXリファレンス、サンプルアプリなどへのリンクが含まれ、開発者が必要なリソースを迅速に取得できます。
例スニペット:
# FastHTML
> サーバーレンダリング型ハイパーメディアアプリケーションを作成するPythonライブラリ。
## Docs
- [クイックスタート](https://fastht.ml/docs/quickstart.md): 主要機能の概要。
- [HTMXリファレンス](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): HTMXの属性とメソッド一覧。
Nikeのような大手EC企業は、llms.txtファイルを使い、AIに商品ラインやサステナビリティ施策、カスタマーサポートポリシーなどの情報を提供できます。
例スニペット:
# Nike
> サステナビリティとイノベーションを重視する、世界的なアスレチックフットウェア・アパレルブランド。
## Product Lines
- [ランニングシューズ](https://nike.com/products/running.md): ReactフォームやVaporweave技術の詳細。
- [サステナビリティ施策](https://nike.com/sustainability.md): 2025年目標やエコ素材の取り組み。
## Customer Support
- [返品ポリシー](https://nike.com/returns.md): 60日間返品や例外事項について。
- [サイズガイド](https://nike.com/sizing.md): シューズ・アパレルサイズ表。
三つの標準はいずれも自動化システム支援のために設計されていますが、その目的や対象は大きく異なります。
llms.txt:
robots.txt:
sitemap.xml:
robots.txtやsitemap.xmlとは異なり、llms.txtは推論エンジン専用に設計。llms.txtやllms-full.txtを自動生成。llms.txtを作成。https://example.com/llms.txt)に設置。llms_txt2ctxなどのツールで標準準拠を検証。llms.txtやllms-full.txtを直接アップロード可能。llms.txtは開発者や中小プラットフォームで普及しつつありますが、OpenAIやGoogleなどの主要プロバイダーではまだ公式サポートされていません。llms-full.txtが一部LLMのコンテキストウィンドウを超える場合があります。これらの課題がありながらも、llms.txtはAI時代のコンテンツ最適化に向けた先進的なアプローチです。この標準を採用することで、組織は自社コンテンツをAIにとってアクセスしやすく、正確かつ優先的に扱われるようにできます。
研究:大規模言語モデル(LLM)
大規模言語モデル(LLM)は、チャットボット、コンテンツモデレーション、検索エンジンなど多様な自然言語処理アプリケーションを支える中核技術となっています。NicholasとBhatia(2023)による「Lost in Translation: Large Language Models in Non-English Content Analysis」では、LLMの技術的な仕組みをわかりやすく説明し、英語とそれ以外の言語のデータ格差、多言語モデルによる格差解消の取り組みを詳述。特に多言語環境におけるLLMのコンテンツ分析の課題や、研究者・企業・政策決定者への提言をまとめています。進展は見られるものの、非英語言語では依然として制約が大きいと強調されています。論文を読む
MüllerとLaurent(2022)による「Cedille: A large autoregressive French language model」は、フランス語特化の大規模言語モデルCedilleを紹介。Cedilleはオープンソースで、フランス語のゼロショットベンチマークで従来モデルを上回る性能を示し、いくつかのタスクではGPT-3にも匹敵します。データセットのフィルタリングにより有害性も低減できたことを評価。言語特化型LLM開発の重要性を強調しています。論文を読む
OjoとOgueji(2023)による「How Good are Commercial Large Language Models on African Languages?」は、商用LLMがアフリカ諸語でどの程度機能するかを翻訳・分類タスクで評価。分類は翻訳より良い結果でしたが、全体的にアフリカ諸語では性能が低いことが示されました。多様な言語・地域の8言語を対象に分析し、商用LLMにおけるアフリカ諸語の代表性強化の必要性を訴えています。論文を読む
Changら(2024)による「Goldfish: Monolingual Language Models for 350 Languages」は、低リソース言語に対する単言語・多言語モデルの性能比較を実施。多言語LLMは多くの言語で単純なバイグラムモデルにも劣ることが示され、Goldfishは350言語向けの単言語モデルによって低リソース言語の性能を大きく向上させました。今後は対象言語ごとの最適モデル開発が重要だと提言しています。論文を読む
llms.txtは、ウェブサイトのルート(例: /llms.txt)に設置される標準化されたMarkdownファイルで、大規模言語モデル向けに最適化されたコンテンツのキュレーションインデックスを提供し、効率的なAI対話を可能にします。
robots.txt(検索エンジンのクロール用)やsitemap.xml(インデックス用)とは異なり、llms.txtはLLM向けに設計され、Markdownベースのシンプルな構造でAI推論用の高価値コンテンツを優先して提供します。
H1ヘッダー(ウェブサイトのタイトル)、引用による要約、追加文脈や詳細のためのセクション、重要なリソースへのH2区切りのリスト(リンクと説明付き)、省略可能なセカンダリリソースセクションなどで構成されます。
llms.txtは、Answer.AI共同創設者のJeremy Howardによって2024年9月に提案され、LLMが複雑なウェブサイトコンテンツを処理する際の非効率を解決するために生まれました。
llms.txtはノイズ(広告やJavaScriptなど)を減らし、コンテキストウィンドウを最適化し、技術文書やECなどの用途で正確なパースを可能にすることでLLMの効率を高めます。
手動でMarkdown形式で作成するか、MintlifyやFirecrawlなどのツールで自動生成できます。llms_txt2ctxなどの検証ツールで標準準拠を確認できます。
任意の sitemap.xml を AI を使って構造化された llms.txt 形式に変換します。このワークフローは、サイトマップから URL を取得し、その内容を取得・処理し、AI エージェントを活用して AI トレーニングやナレッジインジェストに適した最適化された llms.txt ファイルを生成します。...
あなたのウェブサイトのsitemap.xmlを自動でLLM対応のドキュメント形式に変換します。このAI搭載コンバーターは、ウェブコンテンツを抽出・処理・構造化し、AIトレーニングやLLMアプリケーションに最適な標準化llms.txt形式に整えます。...
FlowHuntで利用できる人気の5つのモデルのライティング能力をテストし、コンテンツライティングに最適なLLMを見つけました。...

