
MLflow
MLflowは、機械学習(ML)ライフサイクルの効率化と管理を目的としたオープンソースプラットフォームです。実験管理、コードパッケージング、モデル管理、コラボレーションのためのツールを提供し、MLプロジェクトの再現性、展開、ライフサイクル管理を強化します。...
1 分で読める
MLflow
Machine Learning
+3
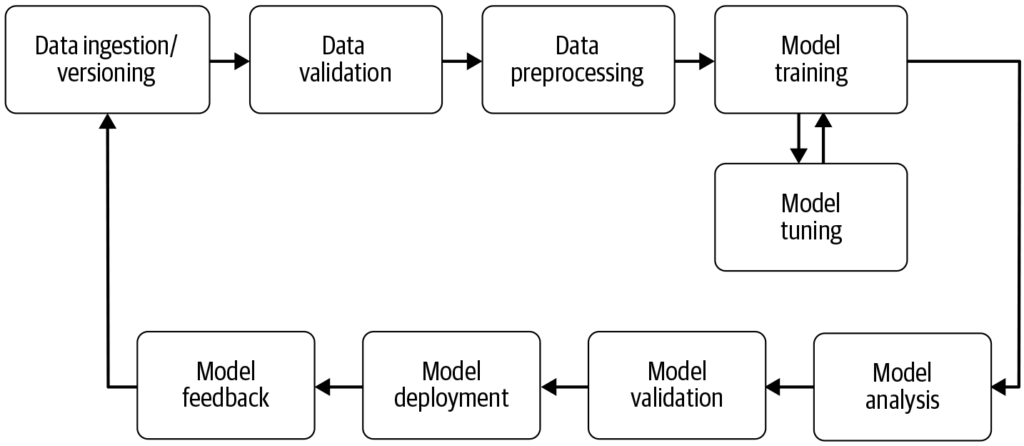
機械学習パイプラインは、データ収集からモデルデプロイメントまでの工程を自動化し、機械学習プロジェクトにおける効率性、再現性、スケーラビリティを向上させます。
機械学習パイプラインは、モデルの開発・学習・評価・デプロイメントを効率化する自動化ワークフローです。データ収集からモデルの運用・保守までのタスクを効率的に進め、再現性とスケーラビリティを高めます。
機械学習パイプラインは、機械学習モデルの開発、学習、評価、デプロイメントに関わる一連の工程を包含した自動化ワークフローです。未加工データから実用的なインサイトを機械学習アルゴリズムによって導き出すためのプロセスを効率化・標準化するよう設計されています。パイプライン方式は、データ処理、モデル学習、デプロイメントの効率的な運用を可能にし、機械学習の運用管理やスケールを容易にします。
データ収集: データベース、API、ファイルなど様々なソースからデータを収集する初期段階です。データ収集は、特定のビジネス目的に合った一貫性のあるデータセットを構築するため、意味のある情報を体系的に取得する手法です。この未加工データはモデル構築に不可欠ですが、利用するには前処理が必要な場合が多いです。AltexSoftが指摘するように、データ収集は分析や意思決定を支援するための情報を組織的に蓄積するプロセスであり、パイプラインのすべての後続工程の基礎となります。また、モデルが最新かつ関連性の高いデータで学習されるよう、継続的に行われることが多いです。
データ前処理: 未加工データをクリーンで学習に適した形式へ変換します。一般的な前処理ステップには、欠損値の処理、カテゴリ変数のエンコーディング、数値特徴量のスケーリング、学習データとテストデータへの分割などがあります。この段階でデータの整合性を確保し、モデルのパフォーマンスに影響する不一致を取り除きます。
特徴量エンジニアリング: データから新しい特徴量を生成したり、予測力の高い特徴量を選択したりします。この工程にはドメイン知識や創造性が求められます。特徴量エンジニアリングは、未加工データを問題の本質をより良く表現する意味のある特徴量へと変換し、モデルのパフォーマンスを向上させます。
モデル選択: 問題の種類(分類・回帰など)、データの特性、パフォーマンス要件に基づき、適切な機械学習アルゴリズムを選択します。この段階ではハイパーパラメータチューニングも考慮されます。適切なモデルを選ぶことは、予測精度や効率性に大きく影響します。
モデル学習: 選択したモデルを学習データセットで学習させます。データ内のパターンや関係性を学習し、場合によっては既存の学習済みモデルを利用することもあります。学習フェーズは、モデルがデータから学び、予測を行うための重要なステップです。
モデル評価: 学習後、テストデータや交差検証を用いてモデルの性能を評価します。評価指標は問題によって異なり、精度、適合率、再現率、F1スコア、平均二乗誤差などが用いられます。この段階でモデルが未知データにも十分な性能を発揮できるか確認します。
モデルデプロイメント: 十分に評価されたモデルは、本番環境にデプロイされ、未知の新しいデータに対して予測を行います。API化や他システムとの連携も含まれます。デプロイメントはモデルが実際の業務で活用されるための最終ステップです。
監視と保守: デプロイ後は、モデルのパフォーマンスを継続的に監視し、データの変化に応じて再学習などを行い、現実環境でも正確かつ信頼性の高い状態を保ちます。この継続的なメンテナンスにより、モデルの有効性を長期間維持できます。
自然言語処理(NLP): NLPタスクは、データ取り込み、テキストクリーニング、トークナイズ、感情分析など複数の反復工程を含みます。パイプラインによってこれらのステップをモジュール化し、他の部分に影響を与えず簡単に修正や更新が可能です。
予知保全: 製造業などの分野では、センサーデータを解析して設備故障を予測し、プロアクティブな保守やダウンタイム削減に役立ちます。
金融: 金融データの処理を自動化し、不正検知、信用リスク評価、株価予測などの意思決定を高度化します。
医療: 医療画像や患者記録の処理を通じて診断支援や患者アウトカムの予測を行い、治療戦略の最適化に貢献します。
機械学習パイプラインは、AIと自動化 に不可欠な存在であり、機械学習タスクを自動化するための構造化された枠組みを提供します。AI自動化 の領域では、パイプラインによってモデルの学習やデプロイメントが効率化され、[チャットボット]などのAIシステムが人手を介さず新たなデータに適応できるようになります。この自動化は、AIアプリケーションをスケールし、多様な分野で一貫した高パフォーマンスを提供する上で重要です。パイプラインを活用することで、組織はAI活用力を強化し、変化する環境でも機械学習モデルの有効性と信頼性を保つことができます。
機械学習パイプラインに関する研究
“Deep Pipeline Embeddings for AutoML”(Sebastian Pineda ArangoおよびJosif Grabocka著・2023年)は、AutoMLにおける機械学習パイプライン最適化の課題に着目しています。本論文では、パイプライン構成要素間の深い相互作用を捉える新しいニューラルアーキテクチャを提案しています。各構成要素ごとのエンコーダによりパイプラインを潜在表現に埋め込み、ベイズ最適化フレームワークで最適なパイプラインを探索します。メタラーニングによりネットワークパラメータをチューニングし、複数データセットで最先端の最適化結果を示しています。 続きを読む
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model”(Tien-Dung Nguyenら・2020年)は、AutoMLプロセスにおけるパイプライン評価の時間的非効率性を扱っています。従来のベイズ的・遺伝的最適化手法の非効率性を指摘し、実行せずにパイプライン妥当性を評価できる代理モデル「AVATAR」を提案。これにより複雑なパイプラインの構成と最適化が大幅に加速され、不適切なものを早期に除外できます。 続きを読む
“Data Pricing in Machine Learning Pipelines”(Zicun Congら・2021年)は、機械学習パイプラインにおけるデータの役割と、複数ステークホルダー間の協業を促進するためのデータ価格設定の重要性を考察しています。本論文は、パイプライン各段階でのデータ取引や価格付けの最新動向を概観し、学習データ収集・協調的なモデル学習・サービス提供までの価格戦略や、動的なエコシステム形成について論じています。 続きを読む
機械学習パイプラインは、データ収集や前処理からモデルの学習、評価、デプロイメントまでの一連のステップを自動化し、機械学習モデルの構築と運用を効率化・標準化する仕組みです。
主な構成要素には、データ収集、データ前処理、特徴量エンジニアリング、モデル選択、モデル学習、モデル評価、モデルデプロイメント、継続的な監視と保守があります。
機械学習パイプラインは、モジュール化、効率性、再現性、スケーラビリティ、コラボレーションの向上、モデルの本番環境へのデプロイメントの容易化などの利点を提供します。
ユースケースには、自然言語処理(NLP)、製造業における予知保全、金融リスク評価や不正検知、医療診断などがあります。
課題には、データ品質の確保、パイプラインの複雑さの管理、既存システムとの統合、計算リソースやインフラにかかるコストの管理などがあります。
MLflowは、機械学習(ML)ライフサイクルの効率化と管理を目的としたオープンソースプラットフォームです。実験管理、コードパッケージング、モデル管理、コラボレーションのためのツールを提供し、MLプロジェクトの再現性、展開、ライフサイクル管理を強化します。...
FlowHuntをReexpress MCPサーバーと統合することで、高度な統計的検証、リアルタイム信頼度スコアリング、動的なモデル適応をLLMパイプラインに導入できます。透明性が高く堅牢なAI検証とエンタープライズ向けカスタマイズにより、ソフトウェア開発・データサイエンスのワークフローを強化します。...
FlowHuntをModel Context Protocol(MCP)経由でZenMLと統合し、MLパイプラインへのアクセスを標準化・セキュア化・効率化します。リアルタイムのワークフロー監視、パイプラインのトリガー、AIによる自動化を通じてZenMLリソースとシームレスに連携できます。...

