チャットボット
チャットボットはAIとNLPを活用して人間の会話をシミュレートするデジタルツールで、24時間体制のサポート、拡張性、コスト効率を実現します。チャットボットの仕組みや種類、利点、実際の活用事例をFlowHuntと一緒にご紹介します。...
1 分で読める
AI
Chatbot
+3
リトリーバルパイプラインとは、チャットボットがユーザーの問い合わせに対して関連情報を取得・処理し、返答するための技術的なアーキテクチャおよびプロセスを指します。単純な事前学習済み言語モデルだけに依存したQAシステムとは異なり、リトリーバルパイプラインは外部ナレッジベースやデータソースを組み込みます。これにより、チャットボットは言語モデル自体に含まれていないデータであっても、正確かつ文脈に沿った最新の応答が可能となります。
リトリーバルパイプラインは通常、データ取り込み、エンベディング生成、ベクターストレージ、コンテキストリトリーブ、応答生成など複数の構成要素から成ります。多くの場合、**リトリーバル強化生成(RAG)の実装を活用し、データリトリーバルシステムと大規模言語モデル(LLM)**の強みを融合して応答生成を行います。
リトリーバルパイプラインは、チャットボットの機能を拡張し、以下を可能にします。
ドキュメント取り込み
PDFやテキストファイル、データベース、APIなどの生データを収集・前処理します。LangChainやLlamaIndexなどのツールがデータ取り込みでよく使われます。
例:カスタマーサポートのFAQや製品仕様書をシステムにロードする。
ドキュメント前処理
長文ドキュメントを、意味的にまとまりのある小さなチャンクに分割します。これは、通常トークン数制限(例:512トークン)のあるエンベディングモデルにテキストを収めるために不可欠です。
コード例:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
エンベディング生成
テキストデータをエンベディングモデルで高次元ベクトルに変換します。エンベディングはデータの意味的情報を数値的に表現します。
エンベディングモデル例:OpenAIの text-embedding-ada-002 や Hugging Faceの e5-large-v2。
ベクターストレージ
エンベディングを類似検索に最適化されたベクターデータベースに保存します。Milvus、Chroma、PGVectorなどがよく用いられます。
例:製品説明文とそのエンベディングを保存し効率的な検索を可能にする。
クエリ処理
ユーザーからの質問を同じエンベディングモデルでクエリベクトルに変換します。これにより保存済みエンベディングと意味的な類似度マッチングが可能となります。
コード例:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
データリトリーブ
コサイン類似度などでスコアリングし、最も関連性の高いデータチャンクを取得します。SQLデータベースやナレッジグラフ、ベクター検索を組み合わせたマルチモーダルリトリーブも可能です。
応答生成
取得したデータとユーザーの質問を組み合わせて大規模言語モデル(LLM)に渡し、最終的な自然言語応答を生成します。この工程は強化生成とも呼ばれます。
プロンプトテンプレート例:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
ポストプロセスと検証
高度なパイプラインでは、幻覚検出や関連性チェック、応答評価などで出力の正確性・妥当性を担保します。
カスタマーサポート
チャットボットが製品マニュアルやトラブルシューティングガイド、FAQをリトリーブして即座に回答します。
例:ルーターのリセット方法をユーザーマニュアルから該当部分を取得して案内する。
企業ナレッジ管理
社内向けチャットボットが人事・ITサポート・コンプライアンス関連の独自データにアクセスします。
例:従業員が社内チャットボットに病欠ルールを問い合わせる。
ECサイト
商品詳細・レビュー・在庫情報などをリトリーブしてユーザーに案内します。
例:「製品Yの主な特徴は?」
医療
医学文献やガイドライン、患者データをリトリーブし医療従事者や患者を支援します。
例:医薬品データベースから薬剤の相互作用警告を取得するチャットボット。
教育・研究
学術チャットボットがRAGパイプラインで論文を取得・要約・質問回答を行う。
例:「この2023年の気候変動研究の要点をまとめて」
法務・コンプライアンス
法律文書や判例・規制要件をリトリーブして専門家を支援します。
例:「GDPR規則の最新アップデートは?」
企業の年次財務報告書(PDF)から質問に答えるチャットボット。
SQL、ベクター検索、ナレッジグラフを組み合わせて従業員の質問に答えるチャットボット。
リトリーバルパイプラインを活用することで、チャットボットは静的な訓練データの制約を超え、動的かつ正確、そしてコンテキストに富んだ対話を実現できます。
リトリーバルパイプラインは現代のチャットボットシステムにおいて、知的かつ文脈を理解した対話を可能にする重要な役割を果たしています。
「Lingke: A Fine-grained Multi-turn Chatbot for Customer Service」Pengfei Zhuら(2018)
複数ターンの会話に対応するため情報検索を統合したチャットボットLingkeを提案。構造化されていない文書からの応答抽出や、連続対話のための文脈重視マッチングなど細粒度パイプライン処理を導入し、複雑なユーザー質問への対応力を大きく向上させました。
論文はこちら。
「FACTS About Building Retrieval Augmented Generation-based Chatbots」Rama Akkirajuら(2024)
エンタープライズ向けRAGパイプラインとLLMを用いたチャットボット開発の課題と手法を検討。Freshness(鮮度)、Architectures(構造)、Cost(コスト)、Testing(検証)、Security(セキュリティ)に重点を置いたFACTSフレームワークを提案し、LLMスケーリング時の精度と遅延のトレードオフなど、実践的な設計知見を紹介しています。論文はこちら。
「From Questions to Insightful Answers: Building an Informed Chatbot for University Resources」Subash Neupaneら(2024)
大学向けチャットボットシステムBARKPLUG V.2を紹介。RAGパイプラインを活用し、キャンパスリソースに関する正確でドメイン特化した回答を提供。RAG Assessment(RAGAS)などの評価フレームワークを用いて効果検証し、学術環境での有用性を示しています。論文はこちら。
リトリーバルパイプラインは、チャットボットが外部ソースから関連情報を取得・処理・リトリーブするための技術的なアーキテクチャです。データの取り込み、エンベディング生成、ベクターストレージ、LLMによる応答生成などを組み合わせ、動的かつ文脈を考慮した返答を実現します。
RAGはデータリトリーバルシステムと大規模言語モデル(LLM)の強みを組み合わせることで、チャットボットが正確かつ最新の外部データに基づいた応答を生成できるようにし、幻覚(誤情報)を減らして精度を高めます。
主な構成要素は、ドキュメント取り込み、前処理、エンベディング生成、ベクターストレージ、クエリ処理、データリトリーブ、応答生成、ポストプロセスによる検証です。
カスタマーサポート、企業ナレッジ管理、EC商品情報、医療ガイダンス、教育・研究、法務コンプライアンス支援などがあります。
リアルタイムリトリーブによる遅延、運用コスト、データプライバシー、膨大なデータ量へのスケーラビリティ対応などの課題があります。
チャットボットはAIとNLPを活用して人間の会話をシミュレートするデジタルツールで、24時間体制のサポート、拡張性、コスト効率を実現します。チャットボットの仕組みや種類、利点、実際の活用事例をFlowHuntと一緒にご紹介します。...
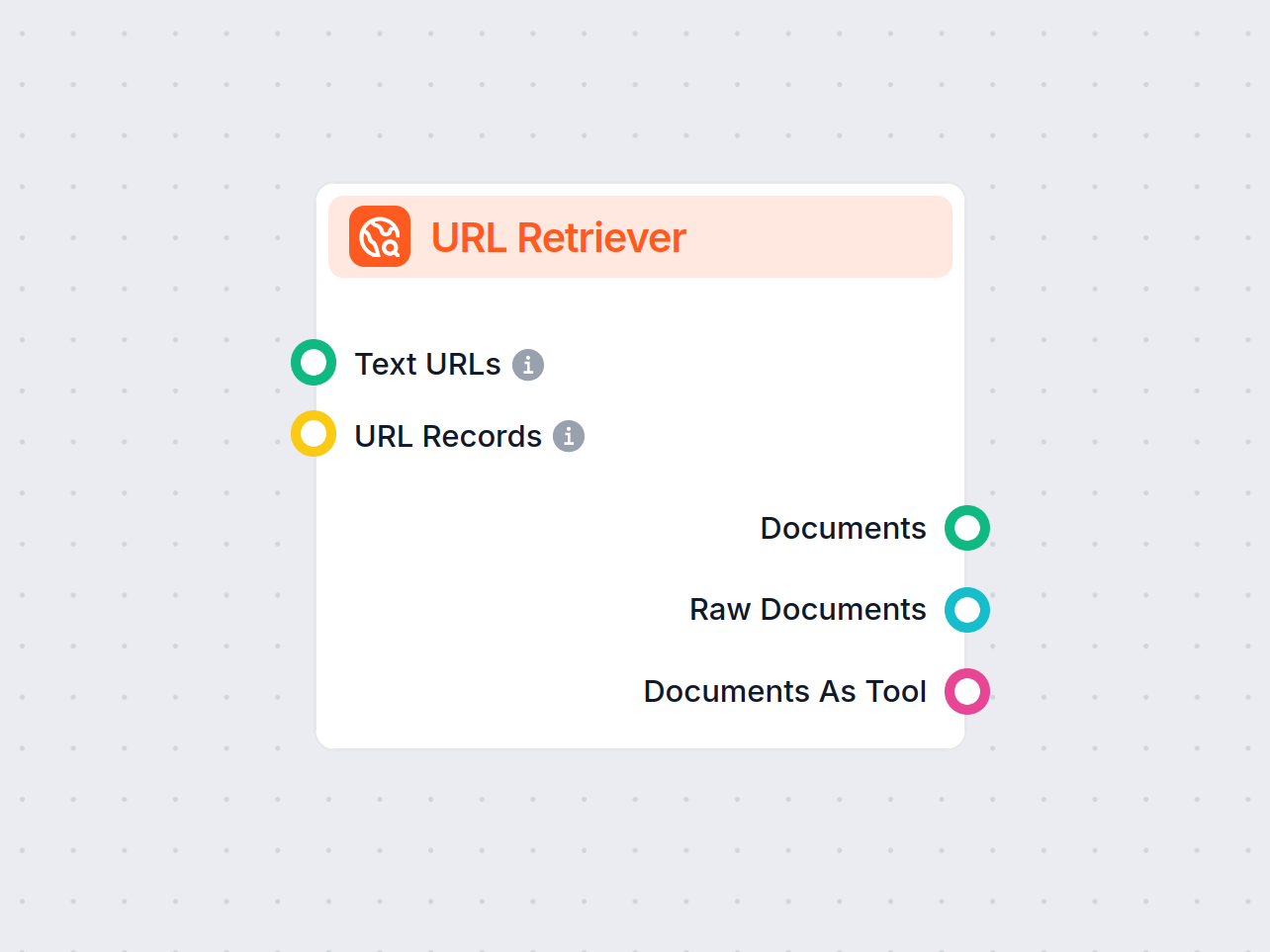
URLリトリーバーコンポーネントでワークフローにウェブコンテンツを取り込みましょう。あらゆるURLリスト(ウェブ記事、ドキュメントなど)からテキストやメタデータを簡単に抽出・処理できます。画像のOCR、高度なメタデータ抽出、カスタマイズ可能なキャッシュなどのオプションをサポートし、知識豊富なAIフローや自動化の構築に最...
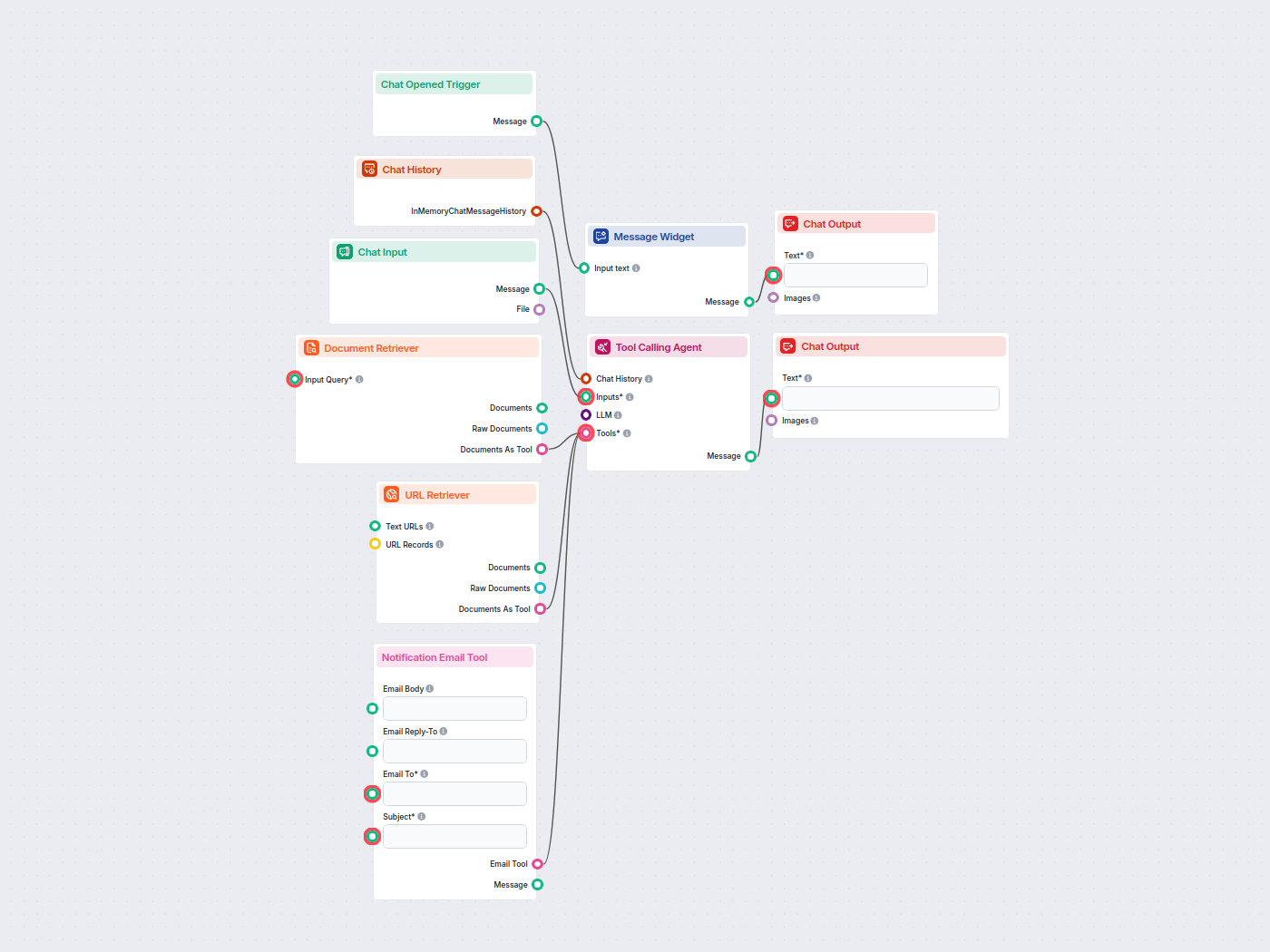
このAI搭載リード獲得チャットボットは、社内ナレッジベースを活用したパーソナライズされた顧客対応を実現し、見込み顧客をリアルタイムで特定、商品やサービスに関心を示した訪問者がいた場合は営業チームに自動でメール通知します。リード取得の自動化と迅速な営業フォローを両立し、マーケティング・営業自動化に最適です。...