自動分類
自動分類は、機械学習、自然言語処理(NLP)、セマンティック解析などの技術を用いて、コンテンツの特性を分析し、タグを自動的に割り当てることでコンテンツの分類を自動化します。これにより、業界を問わず効率化、検索性向上、データガバナンスの強化が実現します。...
2 分で読める
AI
Auto-classification
+5
テキスト分類(テキストカテゴリ化やテキストタグ付けとも呼ばれる)は、事前に決められたカテゴリをテキスト文書に割り当てる重要な自然言語処理(NLP)タスクです。この手法は非構造化テキストデータを整理・構造化し、分析や解釈を容易にします。テキスト分類は、感情分析やスパム検出、トピック分類など、さまざまな用途で利用されています。
AWSによると、テキスト分類はデータを整理・構造化・カテゴリ化する最初のステップとなり、自動的な文書ラベリングやタグ付けを通じて、大量のテキストデータを効率的に管理・分析できるようになります。文書のラベル付けを自動化することで、手作業の労力を削減し、データに基づく意思決定プロセスを強化します。
テキスト分類は機械学習によって実現され、AIモデルがラベル付きデータセットからテキスト特徴とカテゴリのパターン・相関を学習します。一度学習したモデルは、新しい未見のテキスト文書も高精度かつ効率的に分類できます。Towards Data Scienceによれば、このプロセスによりコンテンツの整理が簡単になり、ユーザーはウェブサイトやアプリ内での検索やナビゲーションがしやすくなります。
テキスト分類モデルは、テキストデータのカテゴリ化を自動化するアルゴリズムです。これらのモデルは、訓練データセットの例から学習し、新しいテキスト入力の分類に応用します。代表的なモデルとしては以下が挙げられます。
サポートベクターマシン(SVM): 2クラスまたは多クラス分類に有効な教師あり学習アルゴリズム。SVMは異なるカテゴリのデータ点を最もよく分離するハイパープレーンを見つけ出します。明確な決定境界が必要な用途に適しています。
ナイーブベイズ: 特徴の独立を仮定したベイズの定理に基づく確率的分類器。シンプルかつ効率的で大量データにも適しており、スパム検出や迅速な計算が求められるテキスト分析で広く利用されています。
ディープラーニングモデル: 畳み込みニューラルネットワーク(CNN)やリカレントニューラルネットワーク(RNN)など、複数層でテキストデータの複雑なパターンを捉えることができます。大規模テキスト分類や感情分析、言語モデリングにおいて高い精度を発揮します。
決定木・ランダムフォレスト: データ特徴に基づいた意思決定ルールで分類を行うツリーベース手法。解釈性が高く、顧客フィードバック分類や文書分類など多様な用途で用いられます。
テキスト分類のプロセスは主に以下のステップで構成されます。
データ収集と前処理: テキストデータの収集と前処理(トークン化、ステミング、ストップワード除去など)を行い、データをクリーンアップします。Levity AIによれば、テキストデータは消費者行動の理解に価値があり、適切な前処理が洞察の抽出には不可欠です。
特徴抽出: テキストを機械学習アルゴリズムが処理できる数値表現へ変換します。代表的な手法は以下の通りです。
モデル学習: ラベル付きデータセットを用いて機械学習モデルを訓練します。特徴とカテゴリの対応関係を学びます。
モデル評価: 精度、適合率、再現率、F1スコアなどの指標でモデル性能を評価します。未知データへの汎化を確保するため、交差検証も行われます。AWSは、テキスト分類のパフォーマンス評価が求める精度や信頼性の達成に重要だと強調しています。
予測と運用展開: モデルが検証された後、新しいテキストデータの分類に運用できます。
テキスト分類は様々な分野で広く活用されています。
感情分析: テキストに表現された感情を検出し、顧客フィードバックやSNS分析で世論を把握するのに利用されます。Levity AIは、テキスト分類がソーシャルリスニングに不可欠であり、コメントや意見の背後にある顧客感情の把握に役立つとしています。
スパム検出: スパムか正当なメールかを分類し、不正メールや有害メールを自動でフィルタリングします。Gmailなどに見られる自動フィルタリングとラベリングが代表例です。
トピック分類: ニュース記事やブログ、論文などのコンテンツを事前定義済みトピックごとに整理します。コンテンツ管理や検索性向上に貢献します。
カスタマーサポートチケット分類: 問い合わせ内容に基づきサポートチケットを適切な部署に自動振り分けします。業務効率化とサポートチームの負担軽減に繋がります。
言語検出: 多言語対応アプリケーション向けにテキストの言語を特定します。国際的に事業を展開する企業にとって不可欠な機能です。
テキスト分類にはいくつかの課題があります。
データの質と量: モデル性能は訓練データの質と量に大きく依存します。不十分またはノイズの多いデータでは精度が低下します。AWSは、正確な分類のために高品質なデータ収集とラベリングが必要だと述べています。
特徴選択: 適切な特徴選択はモデル精度に直結します。不適切な特徴では過学習が発生しやすくなります。
モデルの解釈性: ディープラーニングモデルは強力ですが、ブラックボックス化しやすく意思決定の根拠が分かりにくいという課題があります。特に解釈性が重要な業界では採用の障壁となることがあります。
スケーラビリティ: テキストデータ量の増加に伴い、モデルが効率よく大規模データを処理できることが求められます。効率的な処理技術やスケーラブルなインフラが不可欠です。
テキスト分類はAIによる自動化やチャットボットに不可欠です。自動でテキスト入力を分類・解釈することで、チャットボットは適切な応答をし、顧客対応や業務プロセスを効率化します。また、AI自動化においては、テキスト分類により大量データを最小限の人手で処理・分析でき、業務効率や意思決定力が向上します。
さらにNLPやディープラーニングの進展により、チャットボットは高度なテキスト分類能力を持ち、文脈や感情、意図を理解してよりパーソナライズされた正確な対話が可能になりました。AWSは、AIアプリケーションにテキスト分類を組み込むことで、適切かつタイムリーな情報提供を通じてユーザー体験が大幅に向上すると示唆しています。
テキスト分類に関する研究
テキスト分類は、テキストを自動的に事前定義されたラベルに割り当てる自然言語処理の重要なタスクです。以下は、テキスト分類に関連するさまざまな手法や課題についての最新の科学論文の要約です。
Model and Evaluation: Towards Fairness in Multilingual Text Classification
著者: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
発表日: 2023-03-28
この論文は多言語テキスト分類モデルにおけるバイアスの課題に取り組んでいます。外部言語リソースに依存しないコントラスト学習ベースのデバイアスフレームワークを提案し、多言語テキスト表現・言語融合・デバイアス・分類の各モジュールを含みます。また、多次元の公平性評価フレームワークも導入しており、多言語間の公平性向上を目指しています。本研究は多言語テキスト分類モデルの公平性と精度向上に重要な意義があります。続きを読む
Text Classification using Association Rule with a Hybrid Concept of Naive Bayes Classifier and Genetic Algorithm
著者: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
発表日: 2010-09-25
本研究は、アソシエーションルールとナイーブベイズ、遺伝的アルゴリズムを組み合わせた革新的なテキスト分類手法を提案しています。個々の単語ではなく単語間の関係から特徴を抽出し、遺伝的アルゴリズムの統合で最終的な分類性能を高めています。実験結果はこのハイブリッド手法が高い分類精度を実現することを示しています。続きを読む
Text Classification: A Perspective of Deep Learning Methods
著者: Zhongwei Wan
発表日: 2023-09-24
インターネットデータの爆発的増加を背景に、本論文はテキスト分類におけるディープラーニング手法の重要性を強調しています。さまざまなディープラーニング技術について議論し、複雑なテキストの分類精度と効率の向上を示しています。大規模データセットの扱いや高精度な分類結果におけるディープラーニングの進化した役割を明らかにしています。続きを読む
テキスト分類は、あらかじめ定義されたカテゴリをテキスト文書に割り当てる自然言語処理(NLP)のタスクです。これにより非構造化データの自動整理、分析、解釈が可能になります。
一般的なモデルには、サポートベクターマシン(SVM)、ナイーブベイズ、CNNやRNNなどのディープラーニングモデル、決定木やランダムフォレストなどのツリーベース手法があります。
テキスト分類は、感情分析、スパム検出、トピック分類、カスタマーサポートのチケット振り分け、言語検出など幅広く利用されています。
課題としては、データの質と量の確保、適切な特徴選択、モデルの解釈性、大量データに対応するスケーラビリティなどが挙げられます。
テキスト分類は、AIによる自動化やチャットボットがユーザー入力を効率的に解釈・分類・応答することを可能にし、顧客対応や業務プロセスの改善に役立ちます。
自動分類は、機械学習、自然言語処理(NLP)、セマンティック解析などの技術を用いて、コンテンツの特性を分析し、タグを自動的に割り当てることでコンテンツの分類を自動化します。これにより、業界を問わず効率化、検索性向上、データガバナンスの強化が実現します。...
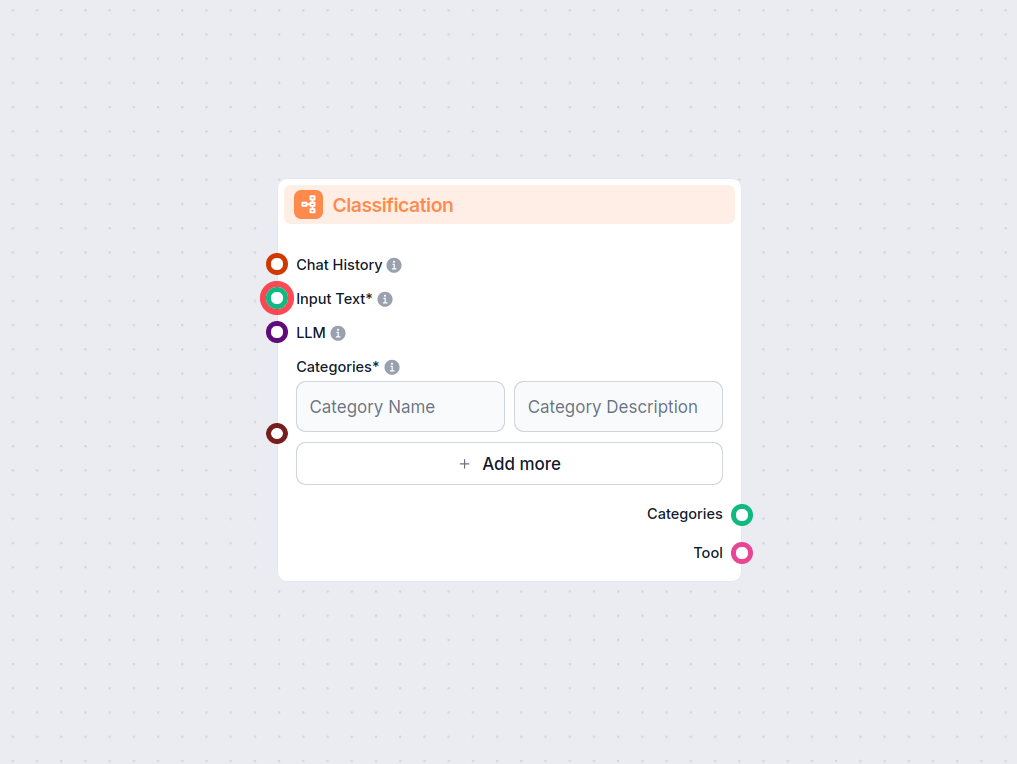
FlowHuntのテキスト分類コンポーネントでワークフローに自動テキスト分類を導入しましょう。AIモデルを活用して、入力テキストをユーザー定義のカテゴリに簡単に分類できます。チャット履歴やカスタム設定のサポートにより、文脈に沿った正確な分類が可能となり、ルーティング、タグ付け、コンテンツモデレーションなどのタスクに最適...
AI分類器は、入力データにクラスラベルを割り当て、過去のデータから学習したパターンに基づいて情報をあらかじめ定義されたクラスに分類する機械学習アルゴリズムです。分類器はAIやデータサイエンスの基礎的なツールとして、さまざまな業界で意思決定を支えています。...