
選択したcPanelドキュメントセクションのみをFlowHuntチャットボットに取り込む方法(サイト全体ではなく)
docs.cpanel.netの特定セクションのみをFlowHuntチャットボットにインポートし、全体のドキュメントポータルを取り込むことなく、対象のcPanelトピックに特化した専門家にするための詳細ガイドです。...
1 分で読める
FlowHunt
integrations
+3
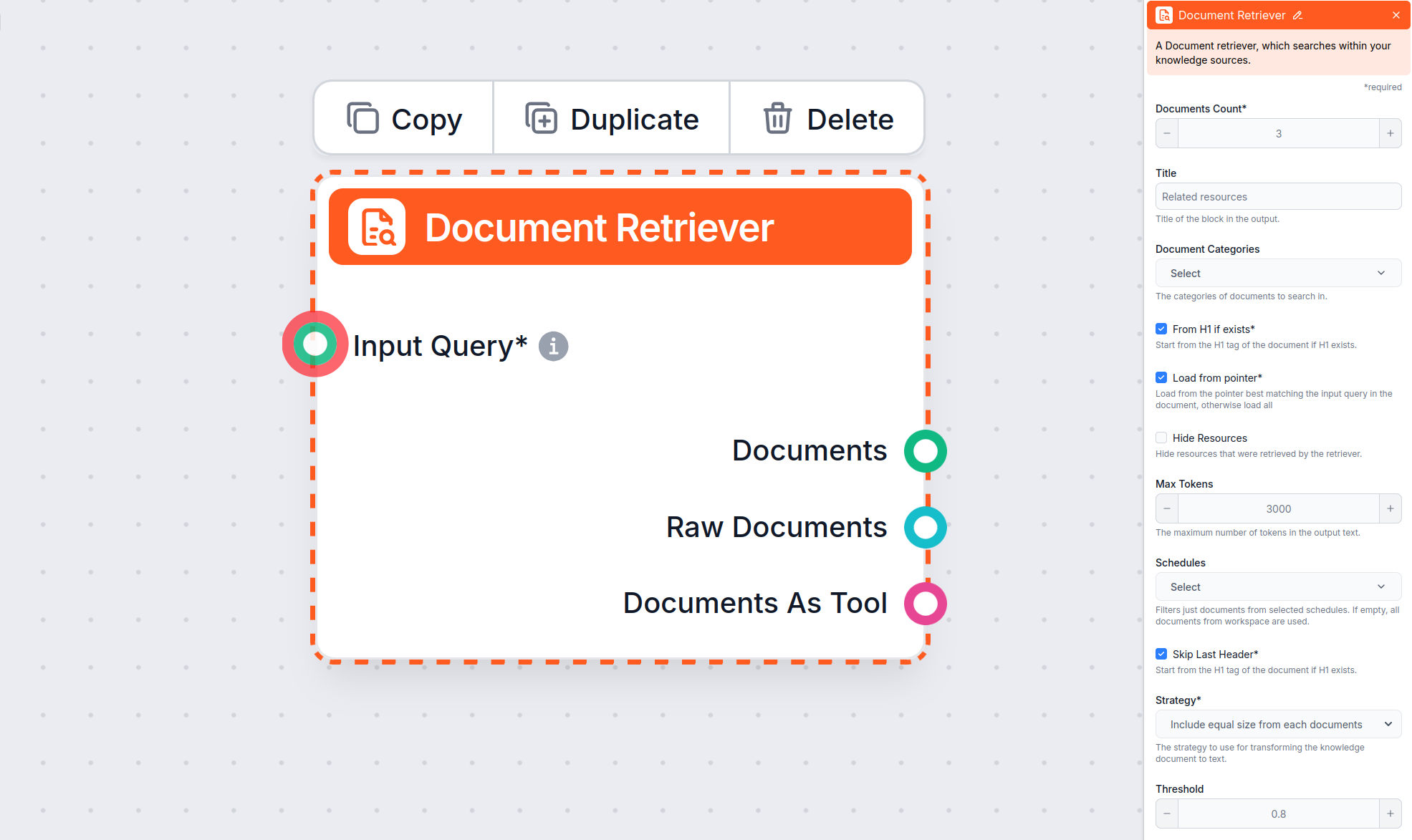
‘From H1 if exists’、‘Load from pointer’、‘Skip Last Header’ パラメータの設定方法をご紹介します。
Document Retrieverコンポーネント は、チャットボットが「ドキュメント」や「スケジュール」で指定したソースから知識を取得できるようにします。このコンポーネントの役割は情報の取得を制御することであり、取得方法に影響する複数のパラメータがあります。
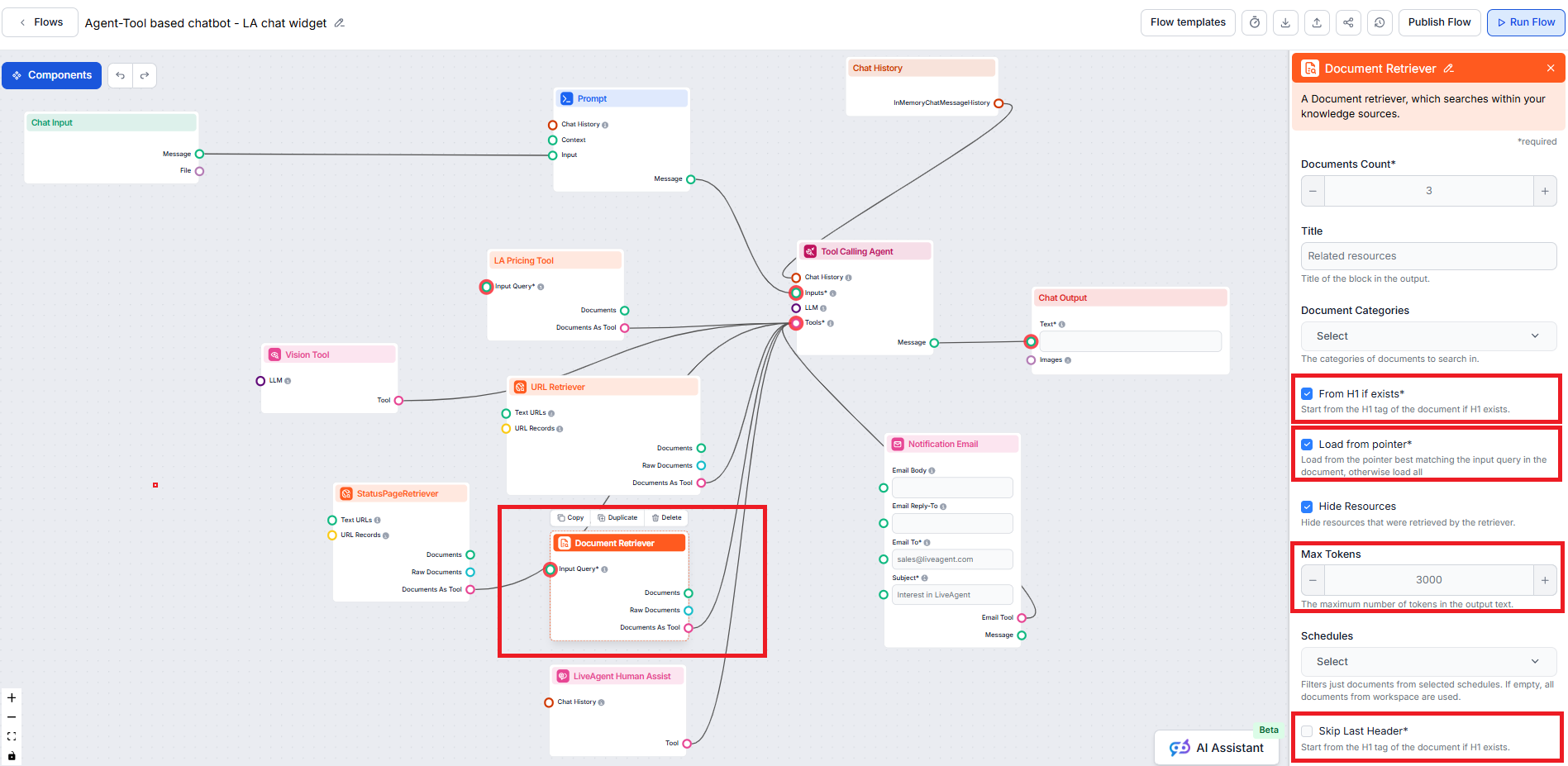
From H1 if exists オプションは、リトリーバーにH1ヘッダー(通常は記事のメインタイトル)からコンテンツの抽出を始めるよう指示します。
どうなるのか?
利用例:
サイトのナビゲーションやページヘッダーなどの不要な要素を除き、実際のガイドのみを取得したい場合。
注意:
From H1 if existsはDocument Retrieverコンポーネントでデフォルト有効です。
Load from pointer オプションは、長い記事の中から特定のポインター以降のみを取得するなど、より精密な制御を可能にします。
どうなるのか?
「ポインター」とは?
ポインターとは、ドキュメント内に存在する一意な文字列や見出し(例:H2や特定のフレーズ、セクションタイトル)です。
利用例:
導入部分を飛ばして、長い記事やドキュメントの中の特定セクション(例:「ステップ4:ライブチャットボタンを追加」)から情報を取得したい場合。
Skip Last Header オプションは、ドキュメント末尾のヘッダーを無視したい場合に有用です。これらはナビゲーションやフッターのために繰り返し使われることが多いです。
どうなるのか?
利用例:
ヘルプページ末尾の「他の記事」など、フッターナビゲーションヘッダーを除外し、メインコンテンツのみを処理したい場合。
注意:
Skip Last Headerは、フッターや繰り返しナビゲーション要素が自動生成されるドキュメントに有効です。ただし、そのようなセクションがない場合、このパラメータを有効にすると有用な情報部分が取得されなくなる場合があるため、正当な理由がない限りオフのままにしておくことを推奨します。
Max tokens パラメータは、Document Retrieverが抽出テキストから出力する最大トークン数(単語や句読点など、AIモデルによってカウントされる単位)を制御できます。
どうなるのか?
デフォルト値:
通常は3,000トークンですが、必要に応じて調整可能です。
利用例:
長いドキュメントを処理する場合、Max tokens値を低く設定すると、回答を簡潔に保てます。ただし、最良の結果には「Load from pointer」パラメータの併用をおすすめします。これにより、抽出テキストがドキュメント内の最も関連性の高いセクションから始まり、指定トークン内で集中的かつ管理しやすい情報を取得できます。特に大規模ソースから簡潔で文脈に沿った出力が欲しい際に有効です。
注意:
情報が途中で切れてしまう場合は、Max tokens値を増やしてください。逆に、短く焦点を絞った出力が必要な場合は、Max tokens値を減らしましょう。
Document Retrieverが複数の関連ドキュメントを見つけた場合、Strategyパラメータが「Max tokens」制限を考慮しつつ、それらをどのように一つのテキスト出力へまとめるかを決定します。
2つの戦略オプション:
各ドキュメントから均等サイズを含める:
トークン上限を均等に分配します。例えば、3つのドキュメントと3,000トークン上限の場合、各ドキュメントに最大1,000トークンずつ割り当てます。すべてのソースを均等に反映したい場合に有効です。
ドキュメントを連結し、最初からトークン上限まで詰める:
関連性の高い順にドキュメントを追加し、トークン上限に達するまで埋めます。最も関連性の高いドキュメントが最初に埋められ、余裕があれば次に関連性の高いものが追加されます。最初のドキュメントが長い場合、それだけで上限を使い切ることもあります。
選び方のポイント:
注意:
これらの戦略は、取得されたドキュメントからテキストをどのように構成するか(AI生成などの次のステップへ渡す直前)にのみ影響します。どのドキュメントが取得されるかには影響せず、あくまで取得済みドキュメントの内容を「Max tokens」設定内でまとめたりカットしたりする方法です。
この記事では「From H1 if exists」「Load from pointer」「Skip Last Header」「Max tokens」各パラメータの設定に焦点を当てましたが、Document Retrieverにはほかにもドキュメントの選択・取得方法を制御するための追加パラメータがあります。
取得するドキュメント数の上限を設定でき、結果の関連性を維持しつつ、迅速な応答が可能です。
オプション設定で、「ナレッジソース」内のドキュメントセクションで作成したカテゴリのうち、1つまたは複数に絞って取得できます。
取得されたリソースのリストを、実際のチャットボット回答の前に別セクションとして含めるか、非表示にできます。LiveAgent連携の場合はチェック必須です(このセクションはサポートされず、LiveAgentチャットボットウィジェットで正しく表示されません)。
「ナレッジソース」でクロールまたは更新用に指定した1つまたは複数のスケジュールに取得を限定できます。
取得するドキュメントが入力クエリとどれだけ近いかを、関連度スコア(0~1)で制御します。例えば、0.7~0.8のスレッショルドが高い関連性の回答に推奨されます。値が高いほど厳密な一致、低いほど関連性の低いドキュメントも含まれる場合があります。
例:
スレッショルドを0.6に設定し、4つの記事がそれぞれ0.8、0.65、0.5、0.9の関連度スコアを持つ場合、0.6を超える(0.8、0.65、0.9)の記事のみが抽出対象となります。
チャットボットの回答に、ドキュメントやスケジュール内に確実に存在するはずの情報が含まれていない場合、「Verbose」オプションで会話履歴をチェックし、Document Retrieverが利用されたか・どのドキュメントが取得されたかの詳細ログを確認してください。必要に応じて、これらのログを元に設定やプロンプトを調整しましょう。
docs.cpanel.netの特定セクションのみをFlowHuntチャットボットにインポートし、全体のドキュメントポータルを取り込むことなく、対象のcPanelトピックに特化した専門家にするための詳細ガイドです。...
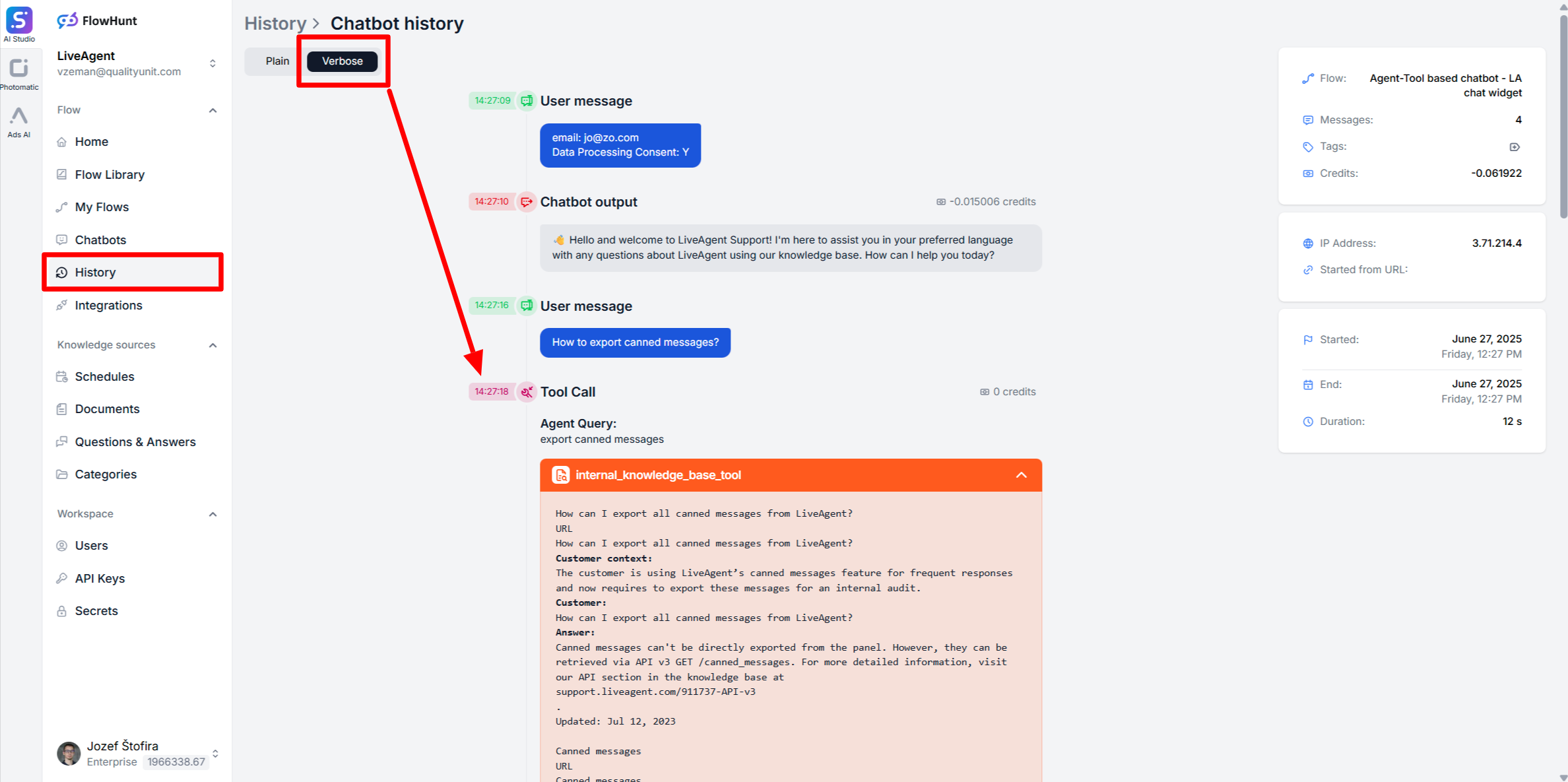
冗長な履歴の活用、チャットボットの回答の見直し、よくある問題の修正など、チャットボットの応答をデバッグするための効果的な戦略を学びましょう。...
あなたのチャットボットは、ドキュメント、HTMLページ、さらにはYouTube動画にも瞬時にアクセスし活用でき、独自のコンテキストをカスタマイズできます。非公開にしたいがチャットボットには参照させたい情報を追加するのに最適です。...