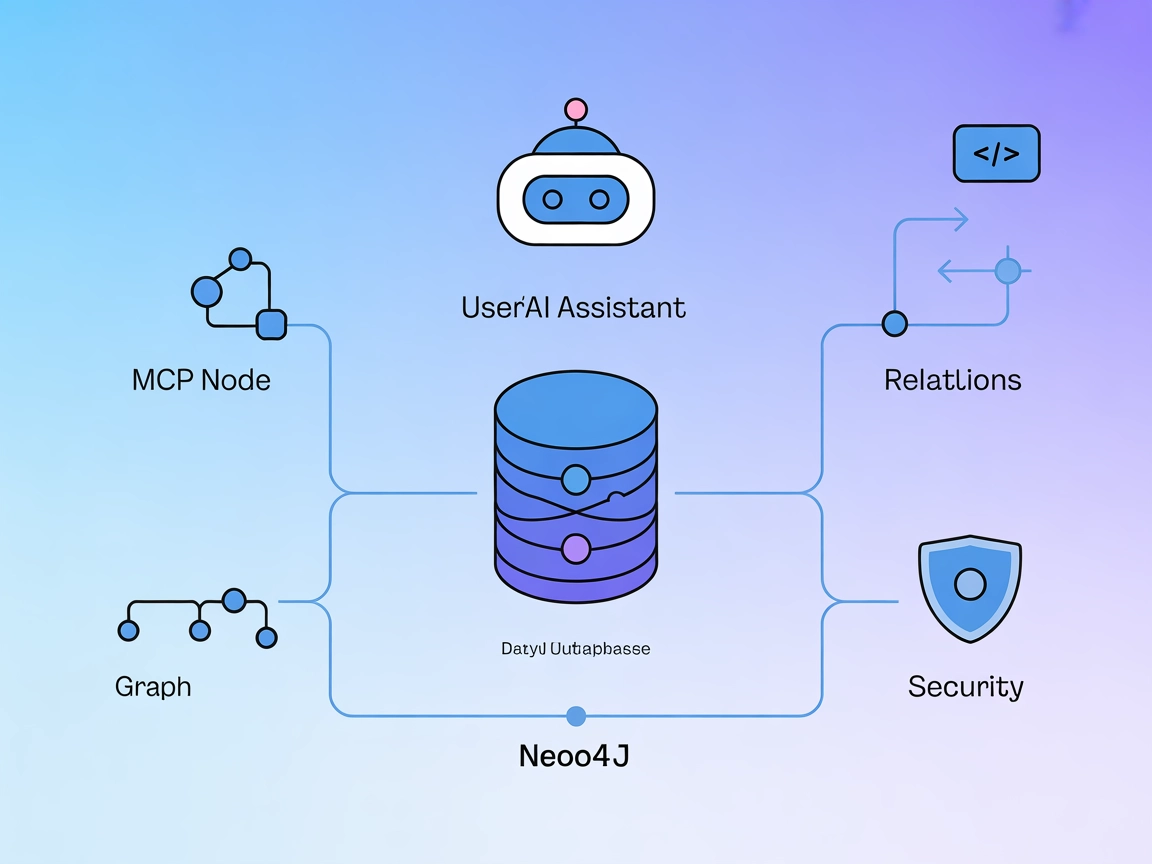
Neo4j MCPサーバー統合
Neo4j MCPサーバーはAIアシスタントとNeo4jグラフデータベースを橋渡しし、セキュアで自然言語によるグラフ操作、Cypherクエリ、自動データ管理をFlowHuntのようなAI対応環境から直接実現します。...
2 分で読める
AI
Graph Database
+5
Neo4j MCPサーバーはAIアシスタントとNeo4jグラフデータベースを橋渡しし、セキュアで自然言語によるグラフ操作、Cypherクエリ、自動データ管理をFlowHuntのようなAI対応環境から直接実現します。...
NASA MCPサーバーは、AIモデルや開発者が20以上のNASAデータソースへアクセスできる統合インターフェイスを提供します。NASAの科学・画像データの取得、処理、管理を標準化し、研究・教育・探査ワークフローへのシームレスな統合を可能にします。...
MCPコードエグゼキューターMCPサーバーは、FlowHuntや他のLLM駆動ツールによるPythonコードの安全な実行、依存関係の管理、コード実行環境の動的設定を、分離された環境下で可能にします。自動コード評価、再現性のあるデータサイエンスワークフロー、FlowHuntフロー内での動的な環境構築に最適です。...
Reexpress MCP サーバーは、統計的な検証機能をLLMワークフローにもたらします。Similarity-Distance-Magnitude(SDM)推定器を用いて、AI出力に対する堅牢な信頼度推定、適応的検証、安全なファイルアクセスを提供し、信頼できる監査可能なLLMレスポンスを必要とする開発者やデータサイ...
データ探索MCPサーバーは、AIアシスタントと外部データセットを接続し、インタラクティブな分析を可能にします。ユーザーはCSVやKaggleデータセットを探索し、分析レポートや可視化を生成でき、データ駆動型の意思決定を効率化します。...
Databricks Genie MCPサーバーは、Genie APIを通じてDatabricks環境と大規模言語モデルを連携させ、会話型データ探索、自動SQL生成、ワークスペースのメタデータ取得を標準化されたModel Context Protocol(MCP)ツールで実現します。...
JupyterMCPは、Jupyter Notebook(6.x)とAIアシスタントをModel Context Protocolでシームレスに統合します。コード実行の自動化、セル管理、出力の取得をLLMで実現し、データサイエンスのワークフローを効率化し、生産性を向上させます。...
AIデータアナリストは、従来のデータ分析スキルと人工知能(AI)、機械学習(ML)を融合し、インサイトの抽出、トレンド予測、意思決定の向上をあらゆる業界で実現します。...
Anacondaは、PythonとRのパッケージ管理と展開を簡素化するために設計された、包括的なオープンソースのディストリビューションです。科学技術計算、データサイエンス、機械学習のための強力なプラットフォームであり、Anaconda, Inc.によって開発され、データサイエンティスト、開発者、ITチーム向けのツールを...
BigMLは、予測モデルの作成と導入を簡素化するために設計された機械学習プラットフォームです。2011年に設立され、誰もが機械学習を利用しやすく、理解しやすく、手頃な価格で提供することを使命とし、ユーザーフレンドリーなインターフェースと機械学習ワークフローを自動化するための強力なツールを提供しています。...
Google Colaboratory(Google Colab)は、Googleが提供するクラウドベースのJupyterノートブックプラットフォームで、ユーザーがブラウザ上でPythonコードを記述・実行でき、無料でGPUやTPUにもアクセスできるため、機械学習やデータサイエンスに最適です。...
Jupyter Notebookは、ライブコード、数式、可視化、説明文を含むドキュメントの作成と共有を可能にするオープンソースのウェブアプリケーションです。データサイエンス、機械学習、教育、研究で広く利用されており、40以上のプログラミング言語やAIツールとのシームレスな統合をサポートします。...
K-Meansクラスタリングは、データポイントとそのクラスタ重心間の二乗距離の合計を最小化することで、データセットを事前に定められた数の明確で重なりのないクラスタに分割する、人気の高い教師なし機械学習アルゴリズムです。...
k-近傍法(KNN)アルゴリズムは、機械学習における分類や回帰タスクで使用される非パラメトリックな教師あり学習アルゴリズムです。'k'個の最も近いデータポイントを見つけ、距離指標や多数決を利用して予測を行うことで、そのシンプルさと多用途性で知られています。...
Kaggleは、データサイエンティストや機械学習エンジニアが協力し、学び、競い合い、知見を共有するためのオンラインコミュニティおよびプラットフォームです。2017年にGoogleに買収されて以来、Kaggleはコンペティション、データセット、ノートブック、教育リソースのハブとなり、AIにおけるイノベーションとスキル向上...
NumPyは、数値計算に不可欠なオープンソースのPythonライブラリであり、高速かつ効率的な配列操作や数学関数を提供します。科学技術計算、データサイエンス、機械学習のワークフローを支え、大規模データの迅速な処理を可能にします。...
Pandasは、オープンソースのPython用データ操作・分析ライブラリであり、その多用途性、強力なデータ構造、複雑なデータセットの扱いやすさで高く評価されています。データアナリストやデータサイエンティストにとって不可欠な基盤であり、効率的なデータクリーニング、変換、分析をサポートします。...
Scikit-learnは、Python向けの強力なオープンソース機械学習ライブラリで、予測データ分析のためのシンプルで効率的なツールを提供します。データサイエンティストや機械学習実務者に広く利用されており、分類、回帰、クラスタリングなど幅広いアルゴリズムを備え、Pythonエコシステムにシームレスに統合されています。...
データクリーニングは、分析や意思決定における正確性、一貫性、信頼性を高めるために、データ内のエラーや不整合を検出・修正し、データ品質を向上させる重要なプロセスです。主要なプロセス、課題、ツール、効率的なデータクリーニングにおけるAIや自動化の役割について解説します。...
データマイニングは、膨大な生データを分析してパターンや関係性、洞察を明らかにし、ビジネス戦略や意思決定に役立てる高度なプロセスです。高度な分析手法を活用することで、組織はトレンドを予測し、顧客体験を向上させ、業務効率を改善できます。...
AIにおけるバイアスを探求:その発生源、機械学習への影響、実例、そして公正かつ信頼性の高いAIシステムを構築するための緩和策を理解しましょう。...
モデルチェイニングは、複数のモデルを順次連結し、それぞれのモデルの出力が次のモデルの入力となる機械学習技術です。この手法は、AI、LLM、エンタープライズアプリケーションなどの複雑なタスクにおいて、モジュール性、柔軟性、スケーラビリティを向上させます。...
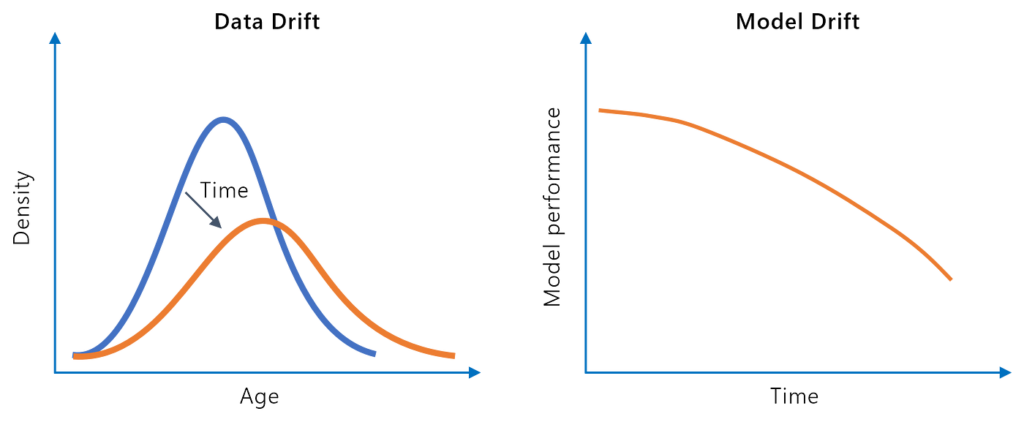
モデルドリフト(またはモデル劣化)とは、現実世界の環境変化によって機械学習モデルの予測精度が時間とともに低下する現象を指します。AIや機械学習におけるモデルドリフトの種類、原因、検出方法、対策について解説します。...
因果推論は、変数間の因果関係を特定するための方法論的アプローチであり、単なる相関を超えて因果メカニズムを理解し、交絡変数などの課題に対応するために科学分野で重要です。...
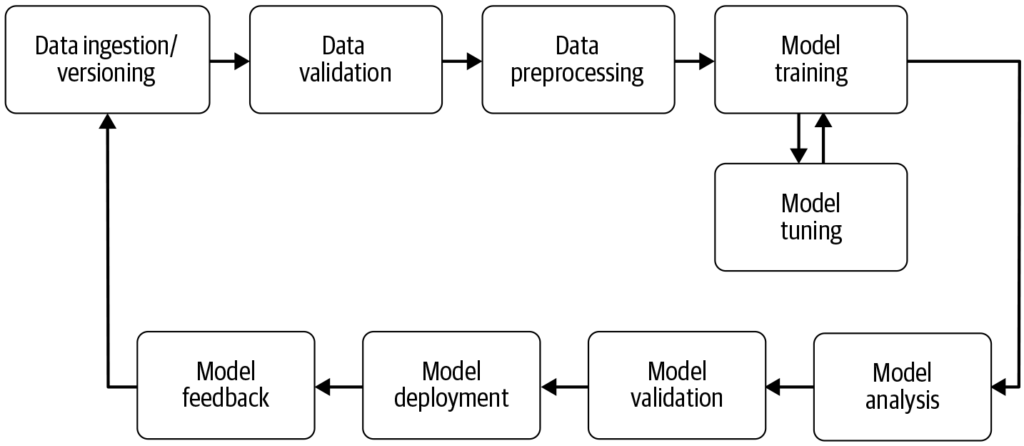
機械学習パイプラインは、機械学習モデルの開発、トレーニング、評価、デプロイメントを自動化し、未加工データを効率的かつ大規模に実用的なインサイトへと変換するワークフローです。...
曲線下面積(AUC)は、機械学習における基本的な指標で、二値分類モデルの性能を評価するために使用されます。AUCは、受信者動作特性(ROC)曲線の下の面積を計算することで、モデルが正例と負例を区別する全体的な能力を定量化します。...
決定木は、意思決定や予測分析において強力かつ直感的なツールであり、分類や回帰タスクの両方で使用されます。その木構造は解釈が容易で、機械学習、金融、医療など幅広い分野で広く活用されています。...
勾配ブースティングは、回帰や分類のための強力な機械学習のアンサンブル手法です。意思決定木などのモデルを順次構築し、予測の最適化、精度向上、過学習の防止を実現します。データサイエンスの競技やビジネスソリューションで広く活用されています。...
次元削減はデータ処理や機械学習における重要な手法であり、データセット内の入力変数の数を減らしつつ、本質的な情報を保持することでモデルを簡素化し、パフォーマンスを向上させます。...
線形回帰は、統計学や機械学習における基盤的な分析手法であり、従属変数と独立変数の関係をモデル化します。そのシンプルさと解釈のしやすさで知られ、予測分析やデータモデリングの基本となっています。...
調整済みR二乗値は、回帰モデルの当てはまりの良さを評価するための統計的指標であり、説明変数の数を考慮することで過学習を防ぎ、モデル性能をより正確に評価します。...
特徴量エンジニアリングと抽出が、生データを価値あるインサイトに変換することでAIモデルの性能を向上させる方法を探ります。特徴量作成、変換、PCA、オートエンコーダなどの主要な手法を知り、MLモデルの精度と効率を改善しましょう。...
半教師あり学習(SSL)は、ラベル付きデータとラベルなしデータの両方を活用してモデルをトレーニングする機械学習手法です。すべてのデータにラベル付けをするのが現実的でなかったりコストがかかる場合に最適です。教師あり学習と教師なし学習の強みを組み合わせて、精度と汎化性能を向上させます。...
AI分類器は、入力データにクラスラベルを割り当て、過去のデータから学習したパターンに基づいて情報をあらかじめ定義されたクラスに分類する機械学習アルゴリズムです。分類器はAIやデータサイエンスの基礎的なツールとして、さまざまな業界で意思決定を支えています。...
予測モデリングは、過去のデータパターンを分析して将来の結果を予測する、データサイエンスおよび統計学における高度なプロセスです。統計的手法や機械学習アルゴリズムを用いて、金融、医療、マーケティングなどの分野でトレンドや行動を予測するモデルを構築します。...