クロスバリデーション
クロスバリデーションは、データを複数回トレーニングセットと検証セットに分割することで、機械学習モデルを評価・比較する統計的手法です。これにより、モデルが未知のデータに対しても汎化できることを保証し、過学習を防ぐのに役立ちます。...
1 分で読める
AI
Machine Learning
+3
クロスバリデーションは、データを複数回トレーニングセットと検証セットに分割することで、機械学習モデルを評価・比較する統計的手法です。これにより、モデルが未知のデータに対しても汎化できることを保証し、過学習を防ぐのに役立ちます。...
コグニティブ・コンピューティングは、複雑な状況において人間の思考プロセスをシミュレートする変革的な技術モデルです。AIと信号処理を統合し、人間の認知を再現することで、構造化データと非構造化データの膨大な量を処理し、意思決定を強化します。...
コンピュータビジョンは、人工知能(AI)の分野の一つで、コンピュータが視覚的な世界を解釈し理解できるようにすることに焦点を当てています。カメラやビデオ、ディープラーニングモデルからのデジタル画像を活用することで、機械は物体を正確に識別・分類し、見たものに応じて反応することができます。...
サイバーセキュリティにおける人工知能(AI)は、機械学習や自然言語処理(NLP)などのAI技術を活用し、サイバー脅威の検出、防止、対応を自動化し、データ分析や脅威インテリジェンスの強化によって堅牢なデジタル防御を実現します。...
AIベースのOCRを使った請求書データ抽出のためのスケーラブルなPythonソリューションをご紹介します。PDFの変換、画像のFlowHunt APIへのアップロード、構造化データのCSV形式での効率的な取得方法を学び、ドキュメント処理ワークフローを効率化しましょう。...
スクリプト型とAIチャットボットの主な違いや実用例、さまざまな業界で顧客対応をどのように変革しているかを探ります。...
セマンティック解析は、テキストから意味を解釈・抽出する重要な自然言語処理(NLP)技術です。これにより機械が言語の文脈、感情、ニュアンスを理解し、ユーザー体験やビジネスインサイトを向上させます。...
ゼロショットラーニングは、AIにおける手法の一つで、モデルが明示的に学習していないカテゴリの物体やデータを、意味的な記述や属性を用いて推論することで認識します。特に、学習データの収集が困難または不可能な場合に有効です。...
ヒューマン・イン・ザ・ループ(HITL)がAIチャットボットにおいてどのように重要であり、人間の専門知識がAIシステムの精度向上、倫理基準の遵守、ユーザー満足度の向上に役立つのかを、さまざまな業界での活用事例とともにご紹介します。...
ディープ・ビリーフ・ネットワーク(DBN)は、深層アーキテクチャと制限付きボルツマンマシン(RBM)を利用して、階層的なデータ表現を学習する高度な生成モデルであり、画像認識や音声認識などの教師あり・教師なしタスクに活用されます。...
ディープラーニングは、人工知能(AI)における機械学習の一分野であり、人間の脳の働きを模倣してデータを処理し、意思決定に利用するパターンを作り出します。これは人工ニューラルネットワークと呼ばれる脳の構造と機能に着想を得ています。ディープラーニングのアルゴリズムは複雑なデータの関係性を分析・解釈し、高精度な音声認識、画像...
ディープフェイクは、AIを活用して非常にリアルだが偽物の画像、動画、または音声を生成する合成メディアの一種です。「ディープフェイク」という用語は、「ディープラーニング」と「フェイク」を組み合わせた造語であり、この技術が高度な機械学習手法に依存していることを示しています。...
テキスト分類(テキストカテゴリ化やテキストタグ付けとも呼ばれる)は、事前に定義されたカテゴリをテキスト文書に割り当てるNLPの主要なタスクです。機械学習モデルを用いて、感情分析、スパム検出、トピック分類などのプロセスを自動化し、非構造化データを分析のために整理・構造化します。...
AIや機械学習におけるトレーニングエラーは、モデルの予測出力と実際の出力との間の訓練中の差異を指します。これはモデル性能を評価するための重要な指標ですが、過学習や過少学習を避けるためにはテストエラーと併せて考慮する必要があります。...
トレーニングデータとは、AIアルゴリズムに指示を与え、パターン認識、意思決定、結果予測を可能にするために使用されるデータセットのことです。このデータにはテキスト、数値、画像、動画などが含まれ、高品質で多様かつ正確にラベル付けされていることが、AIモデルの効果的なパフォーマンスには不可欠です。...
トップk精度は、真のクラスが上位k個の予測クラス内に含まれているかどうかを評価する、機械学習の評価指標です。マルチクラス分類タスクにおいて、より包括的かつ柔軟な指標を提供します。...
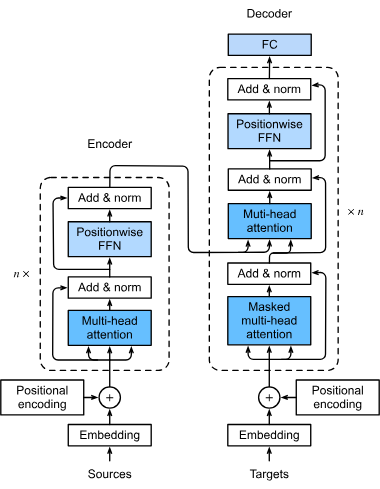
トランスフォーマーは、人工知能、特に自然言語処理に革命をもたらしたニューラルネットワークアーキテクチャです。2017年の「Attention is All You Need」で導入され、効率的な並列処理を可能にし、BERTやGPTなどのモデルの基盤となり、NLPや画像処理など幅広い分野に影響を与えています。...
ドロップアウトはAI、特にニューラルネットワークにおける正則化手法で、トレーニング中にランダムにニューロンを無効化することで過学習を防ぎ、頑健な特徴学習と新しいデータへの汎化能力を向上させます。...
ナイーブベイズはベイズの定理に基づく分類アルゴリズムのファミリーで、特徴量が条件付きで互いに独立であるという単純化した仮定のもと条件付き確率を適用します。それにもかかわらず、ナイーブベイズ分類器は効果的でスケーラブルであり、スパム検出やテキスト分類などの用途で利用されています。...
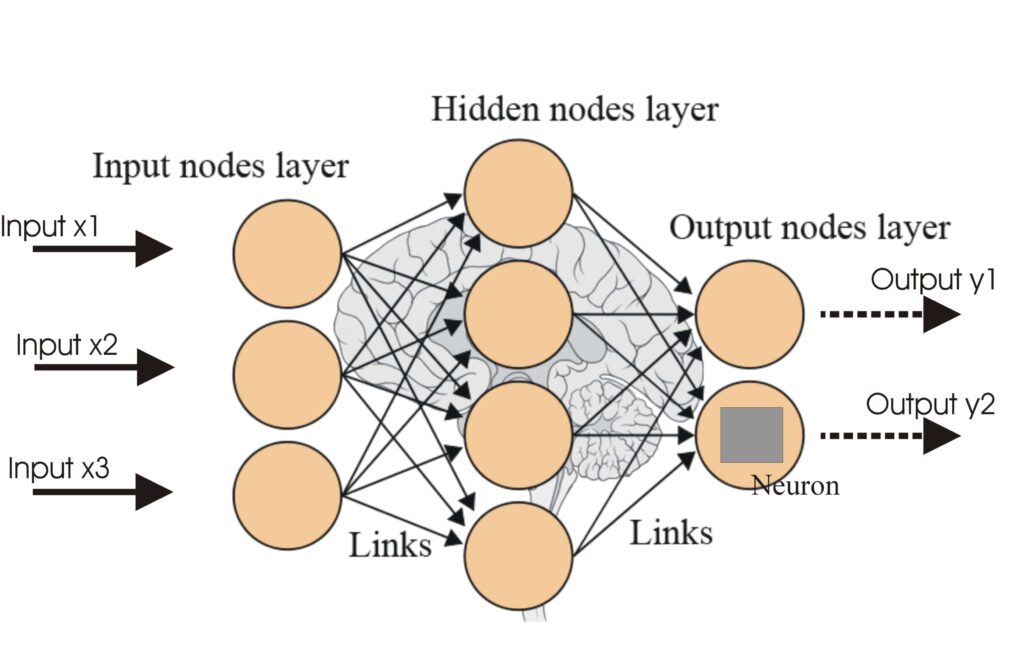
ニューラルネットワーク(人工ニューラルネットワーク / ANN)は、人間の脳に着想を得た計算モデルであり、パターン認識、意思決定、ディープラーニング応用など、AIや機械学習に不可欠です。...
パターン認識は、データ内のパターンや規則性を特定するための計算処理であり、AI、コンピュータサイエンス、心理学、データ分析などの分野で重要な役割を果たします。音声・テキスト・画像・抽象的なデータセット内の構造を自動的に認識し、コンピュータビジョン、音声認識、OCR、不正検出などのインテリジェントなシステムやアプリケーシ...
AIにおけるバイアスを探求:その発生源、機械学習への影響、実例、そして公正かつ信頼性の高いAIシステムを構築するための緩和策を理解しましょう。...
ハイパーパラメータチューニングは、学習率や正則化などのパラメータを調整することでモデル性能を最適化する、機械学習において基本となるプロセスです。グリッドサーチ、ランダムサーチ、ベイズ最適化などの手法を探ってみましょう。...
バギング(Bootstrap Aggregatingの略)は、AIと機械学習における基本的なアンサンブル学習手法で、ブートストラップされたデータサブセットで複数のベースモデルを学習し、それらの予測を集約することでモデルの精度と堅牢性を向上させます。...
バックプロパゲーションは、予測誤差を最小限に抑えるために重みを調整し、人工ニューラルネットワークを訓練するアルゴリズムです。その仕組みやステップ、ニューラルネットワーク訓練の原則について学びましょう。...
バッチ正規化は、ディープラーニングにおいて内部共変量シフトを解消し、活性化を安定させることで、ニューラルネットワークの学習プロセスを大幅に強化し、より速く安定した学習を可能にする画期的な手法です。...
パラメータ効率の高いファインチューニング(PEFT)は、AI や自然言語処理(NLP)分野における革新的なアプローチであり、大規模な事前学習済みモデルのパラメータの一部のみを更新することで、特定タスクへの適応を可能にし、計算コストや学習時間を削減し、効率的な運用を実現します。...
ヒューマン・イン・ザ・ループ(HITL)は、AIおよび機械学習において人間の専門知識をAIシステムの学習、調整、適用プロセスに組み込む手法であり、精度の向上、エラーの削減、倫理的な遵守を実現します。...
ヒューリスティクスは、経験的知識や経験則を活用することで、AIにおいて迅速かつ満足のいく解決策を提供し、複雑な探索問題を単純化し、A*やヒルクライミングなどのアルゴリズムが有望な経路に集中することで効率性を高めます。...
モデルのファインチューニングは、事前学習済みのモデルを新しいタスクに適応させるために軽微な調整を行い、データやリソースの必要性を削減します。ファインチューニングが転移学習をどのように活用し、さまざまな手法、ベストプラクティス、評価指標によってNLPやコンピュータビジョンなどの分野で効率的にモデル性能を向上させるかを学び...
フェデレーテッドラーニングは、複数のデバイスがトレーニングデータをローカルに保持したまま、共有モデルを共同で学習する機械学習手法です。このアプローチはプライバシーを強化し、遅延を削減し、生データを共有することなく何百万ものデバイスでスケーラブルなAIを実現します。...
ベイジアンネットワーク(BN)は、変数とその条件付き依存関係を有向非巡回グラフ(DAG)で表現する確率的グラフィカルモデルです。ベイジアンネットワークは不確実性をモデル化し、推論や学習をサポートし、医療、AI、金融など幅広い分野で利用されています。...
ヘルスケアにおける人工知能(AI)は、機械学習、自然言語処理(NLP)、ディープラーニングなどの先進的なアルゴリズムや技術を活用し、複雑な医療データを分析、診断の強化、治療の個別化、業務効率の向上を実現し、患者ケアを変革しつつ創薬の加速も促進します。...
モデルコラプスは、人工知能において、特に合成データやAI生成データに依存した場合に、訓練済みモデルが時間とともに劣化する現象です。これにより、出力の多様性が低下し、安全な応答が増え、創造的または独自のコンテンツを生み出す能力が損なわれます。...
モデルチェイニングは、複数のモデルを順次連結し、それぞれのモデルの出力が次のモデルの入力となる機械学習技術です。この手法は、AI、LLM、エンタープライズアプリケーションなどの複雑なタスクにおいて、モジュール性、柔軟性、スケーラビリティを向上させます。...
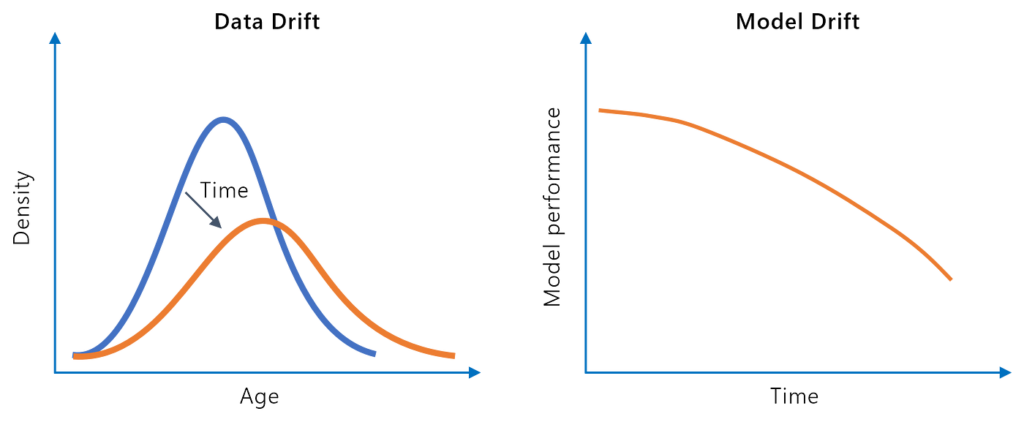
モデルドリフト(またはモデル劣化)とは、現実世界の環境変化によって機械学習モデルの予測精度が時間とともに低下する現象を指します。AIや機械学習におけるモデルドリフトの種類、原因、検出方法、対策について解説します。...
モデルのロバスト性とは、機械学習(ML)モデルが入力データの変動や不確実性にもかかわらず、一貫した正確なパフォーマンスを維持する能力を指します。ロバストなモデルは、信頼性の高いAIアプリケーションに不可欠であり、ノイズ、外れ値、分布の変化、敵対的攻撃に対する耐性を確保します。...
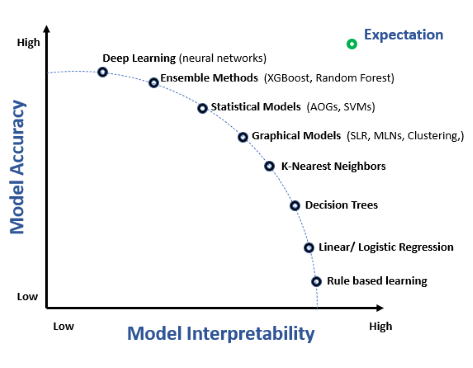
モデルの解釈性とは、機械学習モデルが行う予測や意思決定を理解し、説明し、信頼できる能力を指します。これはAIにとって重要であり、特に医療、金融、自律システムにおける意思決定の際に不可欠です。複雑なモデルと人間の理解力のギャップを埋める役割を果たします。...
ランダムフォレスト回帰は予測分析に用いられる強力な機械学習アルゴリズムです。複数の決定木を構築し、その出力の平均を取ることで、精度・ロバスト性・多様性が向上し、さまざまな業界で活用されています。...
リトリーバル拡張生成(RAG)とキャッシュ拡張生成(CAG)のAIにおける主な違いを解説します。RAGはリアルタイム情報を動的に取得し、柔軟かつ正確な応答を実現。一方CAGは事前キャッシュされたデータを活用し、高速かつ一貫した出力を提供します。プロジェクトのニーズに合った手法の選び方や、実用例、強みと制約を紹介します。...
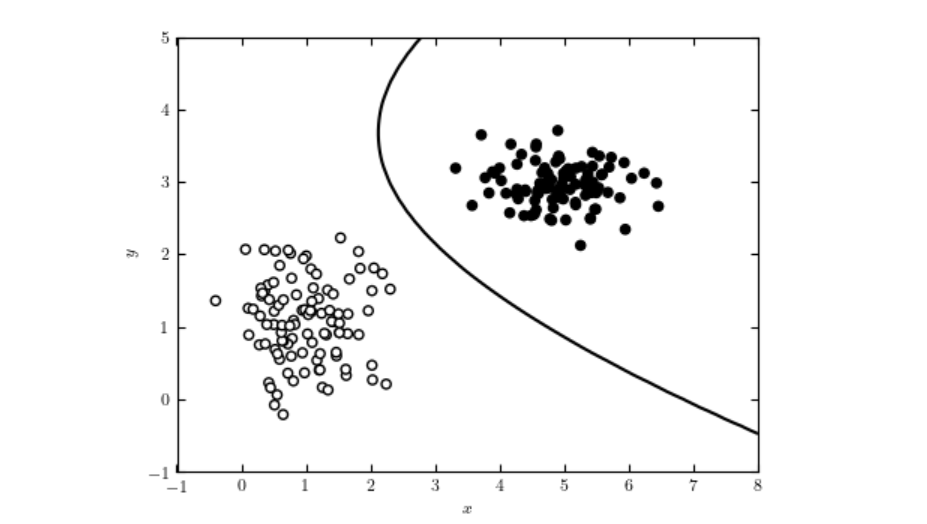
ロジスティック回帰は、データから2値(バイナリ)アウトカムを予測するために用いられる統計および機械学習手法です。1つまたは複数の独立変数に基づいて事象が発生する確率を推定し、医療、金融、マーケティング、AIなど幅広い分野で活用されています。...
依存構文解析は、NLPにおける構文解析手法の一つであり、文中の単語間の文法的関係を特定し、機械翻訳、感情分析、情報抽出などのアプリケーションに不可欠な木構造を形成します。...
異常検知は、データセット内で期待される基準から逸脱したデータポイント、イベント、またはパターンを特定するプロセスであり、AIや機械学習を活用して、サイバーセキュリティ、金融、医療などの業界でリアルタイムかつ自動的に検知を行います。...
因果推論は、変数間の因果関係を特定するための方法論的アプローチであり、単なる相関を超えて因果メカニズムを理解し、交絡変数などの課題に対応するために科学分野で重要です。...
隠れマルコフモデル(HMM)は、基礎となる状態が観測できないシステムに対する高度な統計モデルです。音声認識、バイオインフォマティクス、金融分野で広く利用されており、HMMは隠れたプロセスを解釈し、ビタビやバウム・ウェルチなどのアルゴリズムによって動作します。...
音声認識は、自動音声認識(ASR)や音声からテキストへの変換とも呼ばれ、コンピュータが話し言葉を解釈して書き起こしテキストへ変換できる技術です。バーチャルアシスタントからアクセシビリティツールまで、幅広いアプリケーションを支え、人と機械のインタラクションを革新します。...
過学習は人工知能(AI)および機械学習(ML)における重要な概念であり、モデルが訓練データを過度に学習し、ノイズまで取り込んでしまうことで新しいデータへの汎化性能が低下する現象です。過学習の特定方法や効果的な防止技術について学びましょう。...
FlowHunt.ioのAPIとワークフロービルダーを使って、画像から説明文を自動生成する方法を学び、著者のオンラインプレゼンスを一貫性と魅力あるコンテンツで強化しましょう。...
AIにおける画像認識とは何か、その用途、最新トレンド、類似技術との違いについてご紹介します。
会話型AIとは、NLP(自然言語処理)、機械学習、その他の言語技術を用いて、コンピューターが人間の会話を模倣できるようにする技術を指します。チャットボット、バーチャルアシスタント、音声アシスタントなど、カスタマーサポート、ヘルスケア、小売業など幅広い分野で活用され、効率化やパーソナライズを実現します。...
人工知能における学習曲線は、モデルの学習パフォーマンスとデータセットのサイズやトレーニング反復回数などの変数との関係を示すグラフであり、バイアス-バリアンストレードオフの診断、モデル選択、トレーニングプロセスの最適化に役立ちます。...
活性化関数は人工ニューラルネットワークの基礎であり、非線形性を導入して複雑なパターンの学習を可能にします。本記事では、AI・ディープラーニング・ニューラルネットワークにおける活性化関数の目的、種類、課題、主要な応用例について解説します。...
感情分析(センチメント分析)は、オピニオンマイニングとも呼ばれ、テキストの感情的なトーンを肯定的、否定的、中立的として分類・解釈するための重要なAIおよびNLPタスクです。その重要性、種類、アプローチ、そしてビジネスへの実用的な応用例をご紹介します。...
基盤AIモデルは、大量のデータで訓練された大規模な機械学習モデルであり、幅広いタスクに適応可能です。基盤モデルは、NLPやコンピュータビジョンなど様々な分野で、専門的なAIアプリケーションの柔軟な基礎としてAIを革新しました。...
機械学習(ML)は人工知能(AI)の一分野であり、機械がデータから学習し、パターンを特定し、予測を行い、明示的なプログラミングなしで時間とともに意思決定を改善できるようにします。...
機械学習におけるリコール(再現率)について探ります。リコールはモデルの性能評価において重要な指標であり、特に正例を正しく識別することが重要な分類タスクで不可欠です。その定義、計算方法、重要性、ユースケース、改善戦略について学びましょう。...
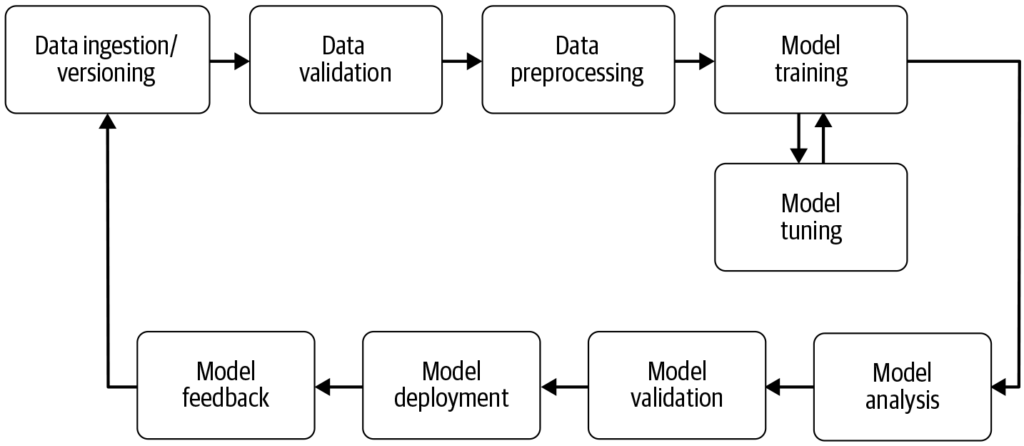
機械学習パイプラインは、機械学習モデルの開発、トレーニング、評価、デプロイメントを自動化し、未加工データを効率的かつ大規模に実用的なインサイトへと変換するワークフローです。...
共参照解析は、テキスト内の同一の実体を指す表現を特定しリンクする、自然言語処理(NLP)の基本タスクです。要約、翻訳、質問応答などのアプリケーションで機械による理解に不可欠です。...
強化学習(RL)は、機械学習の一分野であり、エージェントが環境内で一連の意思決定を行い、報酬や罰則というフィードバックを通じて最適な行動を学習することに焦点を当てています。強化学習の主要な概念、アルゴリズム、応用例、課題について探ってみましょう。...
強化学習(RL)は、エージェントが行動し、フィードバックを受け取ることで意思決定を学習する、機械学習モデルの訓練手法です。報酬やペナルティという形で得られるフィードバックが、エージェントのパフォーマンス向上を導きます。RLは、ゲーム、ロボティクス、金融、ヘルスケア、自動運転車など幅広い分野で活用されています。...
教師あり学習は、機械学習や人工知能における基本的なアプローチで、アルゴリズムがラベル付きデータセットから学習し、予測や分類を行います。そのプロセス、種類、主要なアルゴリズム、応用例、課題について探ります。...
教師あり学習は、アルゴリズムがラベル付きデータで訓練され、新しい未知のデータに対して正確な予測や分類を行う、AIや機械学習の基本的な概念です。その主要な要素、種類、利点について学びましょう。...
教師なし学習は、ラベル付けされていないデータからパターンや構造、関係性を見つけ出すことに焦点を当てた機械学習の分野であり、クラスタリングや次元削減、アソシエーションルール学習などのタスクを通じて、顧客セグメンテーション、異常検知、レコメンデーションエンジンなどのアプリケーションに活用されます。...
教師なし学習は、ラベル付けされていないデータに対してアルゴリズムを訓練し、隠れたパターンや構造、関係性を発見する機械学習手法です。代表的な手法にはクラスタリング、アソシエーション、次元削減などがあり、顧客セグメンテーション、異常検知、マーケットバスケット分析などに応用されています。...
曲線下面積(AUC)は、機械学習における基本的な指標で、二値分類モデルの性能を評価するために使用されます。AUCは、受信者動作特性(ROC)曲線の下の面積を計算することで、モデルが正例と負例を区別する全体的な能力を定量化します。...
金融詐欺検出におけるAIとは、金融サービス内での不正行為を特定・防止するために人工知能技術を活用することを指します。これらの技術には、機械学習、予測分析、異常検知が含まれ、大規模なデータセットを分析して、通常とは異なる疑わしい取引やパターンを特定します。...
決定木は、意思決定や予測分析において強力かつ直感的なツールであり、分類や回帰タスクの両方で使用されます。その木構造は解釈が容易で、機械学習、金融、医療など幅広い分野で広く活用されています。...
決定木は、入力データに基づいて意思決定や予測を行うために使用される教師あり学習アルゴリズムです。内部ノードはテスト、枝は結果、葉ノードはクラスラベルや値を表す、木構造として視覚化されます。...
固有表現認識(NER)は、AIにおける自然言語処理(NLP)の重要な分野であり、テキスト中の人物、組織、場所などのエンティティを識別・分類することで、データ分析を強化し情報抽出の自動化を実現します。...
光学文字認識(OCR)は、スキャンした書類、PDF、画像などのドキュメントを編集・検索可能なデータに変換する革新的な技術です。OCRの仕組み、種類、用途、メリット、制限、そしてAIを活用した最新のOCRシステムの進歩について学びましょう。...
勾配ブースティングは、回帰や分類のための強力な機械学習のアンサンブル手法です。意思決定木などのモデルを順次構築し、予測の最適化、精度向上、過学習の防止を実現します。データサイエンスの競技やビジネスソリューションで広く活用されています。...
勾配降下法は、機械学習や深層学習で広く用いられる基本的な最適化アルゴリズムで、モデルのパラメータを反復的に調整することでコスト関数や損失関数を最小化します。ニューラルネットワークなどのモデル最適化に不可欠であり、バッチ、確率的、ミニバッチ勾配降下法などの形式で実装されます。...
合成データとは、現実世界のデータを模倣するように人工的に生成された情報のことです。アルゴリズムやコンピューターシミュレーションを用いて作成され、本物のデータの代替や補完として活用されます。AIの分野では、合成データは機械学習モデルの訓練・テスト・検証において非常に重要です。...
混同行列は、機械学習における分類モデルの性能評価ツールです。真陽性・偽陽性・真陰性・偽陰性を詳細に可視化し、特に不均衡なデータセットで精度以上の洞察を提供します。...
財務予測は、過去のデータ、市場動向、およびその他の関連要因を分析することで、企業の将来的な財務結果を予測する高度な分析プロセスです。主要な財務指標を予測し、意思決定、戦略的計画、リスク管理を可能にします。...
次元削減はデータ処理や機械学習における重要な手法であり、データセット内の入力変数の数を減らしつつ、本質的な情報を保持することでモデルを簡素化し、パフォーマンスを向上させます。...
自然言語処理(NLP)は、計算言語学、機械学習、ディープラーニングを用いて、コンピュータが人間の言語を理解・解釈・生成できるようにする技術です。NLPは翻訳、チャットボット、感情分析などのアプリケーションを支え、産業を変革し、人間とコンピュータのインタラクションを向上させています。...
自然言語処理(NLP)は、人工知能(AI)の一分野であり、コンピューターが人間の言語を理解・解釈・生成できるようにします。主要な側面や仕組み、産業分野での応用についてご紹介します。...
自動運転車(自動運転車両)について探求しましょう。AI、センサー、コネクティビティを活用し、人間の操作なしで走行する車です。その主要技術、AIの役割、LLMの統合、課題、そしてスマート輸送の未来について学べます。...
自動分類は、機械学習、自然言語処理(NLP)、セマンティック解析などの技術を用いて、コンテンツの特性を分析し、タグを自動的に割り当てることでコンテンツの分類を自動化します。これにより、業界を問わず効率化、検索性向上、データガバナンスの強化が実現します。...
AIにおける収束(コンバージェンス)とは、機械学習やディープラーニングモデルが反復学習を通じて安定した状態に到達し、予測値と実際の結果との差(損失関数)を最小化することで正確な予測を実現するプロセスを指します。これは、自動運転車やスマートシティなど、さまざまなアプリケーションにおけるAIの有効性と信頼性の基盤となります...
小売業における人工知能(AI)は、機械学習、自然言語処理、コンピュータビジョン、ロボティクスなどの先進技術を活用し、顧客体験の向上、在庫の最適化、サプライチェーンの効率化、業務効率の向上を実現します。...
少数ショット学習は、わずかな数のラベル付き例だけでモデルが正確な予測を行えるようにする機械学習の手法です。従来の教師あり学習とは異なり、限られたデータからの一般化に重点を置き、メタラーニング、転移学習、データ拡張などの技術を活用します。...
情報検索は、AI、NLP、機械学習を活用して、ユーザーの要件を満たすデータを効率的かつ正確に検索します。ウェブ検索エンジン、デジタルライブラリ、エンタープライズソリューションの基盤となっており、曖昧さやアルゴリズムバイアス、スケーラビリティなどの課題に対応し、今後は生成AIや深層学習への注目が高まっています。...
人間のフィードバックによる強化学習(RLHF)は、強化学習アルゴリズムのトレーニング過程に人間の入力を取り入れる機械学習手法です。従来の強化学習があらかじめ定義された報酬信号のみに依存していたのに対し、RLHFは人間の判断を活用してAIモデルの振る舞いを形成・洗練します。このアプローチにより、AIは人間の価値観や好みに...
人工ニューラルネットワーク(ANN)は、人間の脳をモデルにした機械学習アルゴリズムの一種です。これらの計算モデルは、相互に接続されたノード(「ニューロン」)で構成されており、複雑な問題を解決するために協力します。ANNは、画像や音声認識、自然言語処理、予測分析などの分野で広く利用されています。...
人工超知能(ASI)は、全ての領域で人間の知能を凌駕し、自己改良やマルチモーダルな能力を持つ理論上のAIです。その特徴、構成要素、応用例、利点、そして倫理的リスクについてご紹介します。...
推論は、情報、事実、論理に基づいて結論を導き出したり、推測を行ったり、問題を解決したりする認知プロセスです。AIにおけるその重要性、OpenAIのo1モデルや高度な推論能力について探ります。...
人工知能(AI)における正則化とは、機械学習モデルの学習時に制約を導入することで過学習を防ぎ、未知のデータに対する汎化性能を高めるための一連の手法を指します。...
製造業における人工知能(AI)は、生産性、効率性、意思決定を高めるために先端技術を統合し、製造現場を変革しています。AIは複雑な作業を自動化し、精度を向上させ、ワークフローを最適化することで、イノベーションと業務の卓越性を推進します。...
AIの説明可能性とは、人工知能システムが行った決定や予測を理解し、解釈できる能力を指します。AIモデルがより複雑になるにつれて、説明可能性はLIMEやSHAPなどの手法を通じて透明性、信頼性、規制遵守、バイアスの軽減、モデルの最適化を実現します。...
線形回帰は、統計学や機械学習における基盤的な分析手法であり、従属変数と独立変数の関係をモデル化します。そのシンプルさと解釈のしやすさで知られ、予測分析やデータモデリングの基本となっています。...
対数損失(ログ損失/クロスエントロピー損失)は、機械学習モデルの性能を評価するための主要な指標であり、特に2値分類において、予測確率と実際の結果の乖離を測定し、不正確または過度に自信のある予測をペナルティとして評価します。...
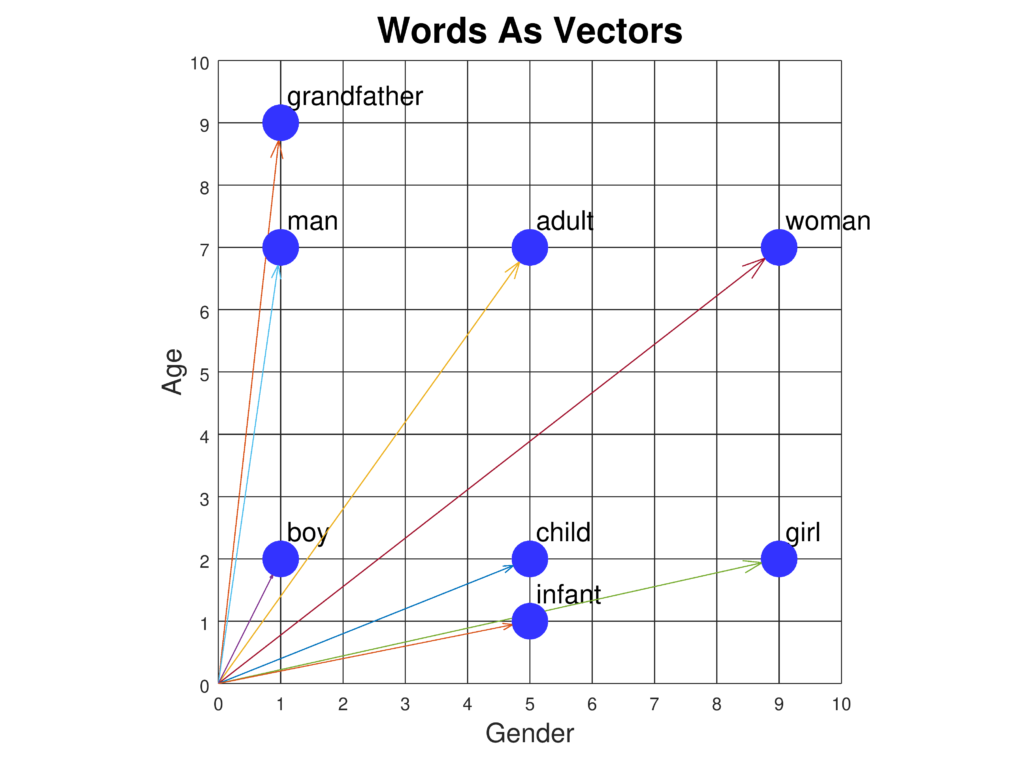
単語埋め込みは、単語を連続的なベクトル空間で表現する高度な手法であり、意味的・構文的な関係性を捉えることで、テキスト分類、機械翻訳、感情分析などの高度なNLPタスクに活用されます。...
調整済みR二乗値は、回帰モデルの当てはまりの良さを評価するための統計的指標であり、説明変数の数を考慮することで過学習を防ぎ、モデル性能をより正確に評価します。...
敵対的生成ネットワーク(GAN)は、生成器と識別器という2つのニューラルネットワークが競い合い、本物と見分けがつかないデータを生成する機械学習フレームワークです。2014年にIan Goodfellowによって提案され、画像生成、データ拡張、異常検知など幅広く活用されています。...
転移学習は、あるタスクで訓練されたモデルを関連する別のタスクに再利用する高度な機械学習手法であり、特にデータが不足している場合に効率と性能を向上させます。...
転移学習は、事前学習済みモデルを新たなタスクに適応させ、限られたデータでも性能を向上させ、画像認識や自然言語処理(NLP)など多様なアプリケーションで効率性を高める強力なAI/ML技術です。...
特徴抽出は、生データを情報量の多い特徴セットに変換することで、データを簡素化し、モデル性能を向上させ、計算コストを削減します。本ガイドでは、手法や応用分野、ツール、科学的知見まで幅広く解説します。...
特徴量エンジニアリングと抽出が、生データを価値あるインサイトに変換することでAIモデルの性能を向上させる方法を探ります。特徴量作成、変換、PCA、オートエンコーダなどの主要な手法を知り、MLモデルの精度と効率を改善しましょう。...