
検索拡張生成(RAG)
検索拡張生成(RAG)は、従来の情報検索システムと生成型大規模言語モデル(LLM)を組み合わせた先進的なAIフレームワークであり、外部知識を統合することで、より正確で最新かつ文脈に即したテキスト生成を可能にします。...
1 分で読める
RAG
AI
+4

検索拡張生成(RAG)による質問応答は、情報検索と自然言語生成を組み合わせることで、大規模言語モデル(LLM)の応答に外部ソースからの関連性が高く最新のデータを補完し、精度・関連性・適応性を向上させます。このハイブリッド手法は、動的な分野における正確性や柔軟性を高めます。
検索拡張生成(RAG)による質問応答は、リアルタイムな外部データを統合することで、言語モデルの応答をより正確かつ関連性の高いものに強化します。動的な分野でのパフォーマンスを最適化し、精度の向上、動的コンテンツ、関連性の強化を実現します。
検索拡張生成(RAG)による質問応答は、情報検索と自然言語生成の強みを組み合わせて人間らしいテキストをデータから生成し、AIやチャットボット、レポート、パーソナライズ体験を強化する革新的な手法です。このハイブリッドアプローチは、大規模言語モデル(LLM)の応答に外部データソースから取得した関連性が高く最新の情報を補完することで、その能力を高めます。従来の事前学習済みモデルに頼る手法と異なり、RAGは外部データを動的に統合し、特に最新情報や専門知識が必要な分野で、より正確かつ文脈に即した回答を可能にします。
RAGは、内部データセットだけでなくリアルタイムかつ権威あるソースに基づいて回答を生成することで、LLMのパフォーマンスを最適化します。このアプローチは、情報が絶えず更新される動的な分野での質問応答タスクに不可欠です。
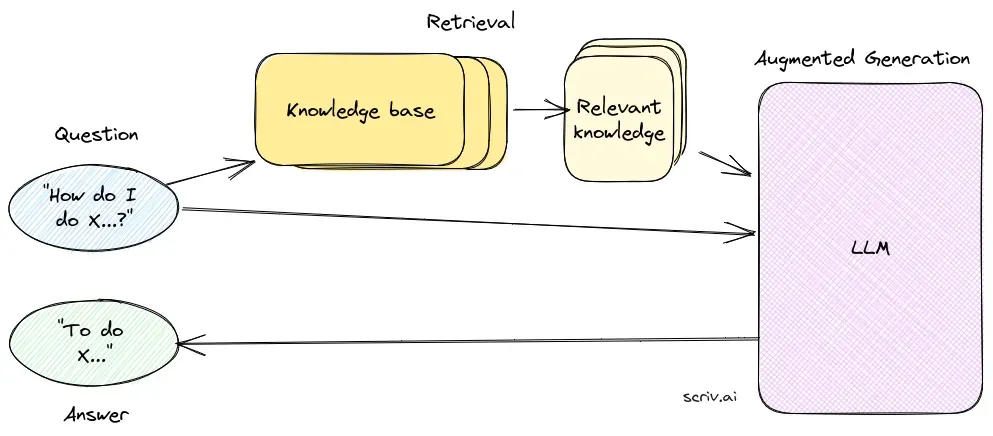
検索コンポーネントは、膨大なデータセット(通常はベクターデータベースに格納)から関連情報を取得する役割を担います。このコンポーネントはセマンティックサーチ技術を用い、ユーザーのクエリに高く関連するテキスト断片や文書を特定・抽出します。
生成コンポーネントは、通常GPT-3やBERTなどのLLMが担当し、ユーザーのクエリと取得した文脈を組み合わせて回答を生成します。このコンポーネントは、一貫性があり文脈に即した応答を生み出すために重要です。
最新のヒント、トレンド、お得な情報を無料で入手。
RAGシステムの実装には、いくつかの技術的なステップが必要です。
検索拡張生成(RAG)による質問応答の研究
検索拡張生成(RAG)は、検索機構と生成モデルを組み合わせて質問応答システムを強化する手法です。近年、様々な文脈でのRAGの有効性と最適化に関する研究が進められています。
検索拡張生成(RAG)が、チャットボットやサポートソリューションのリアルタイムかつ正確な応答をどのように強化できるかをご紹介します。
検索拡張生成(RAG)は、従来の情報検索システムと生成型大規模言語モデル(LLM)を組み合わせた先進的なAIフレームワークであり、外部知識を統合することで、より正確で最新かつ文脈に即したテキスト生成を可能にします。...

検索拡張生成(RAG)がどのようにエンタープライズAIを変革しているのか、基本原則からFlowHuntのような高度なエージェント型アーキテクチャまで紹介。RAGがどのようにLLMを実データで裏付け、幻覚を減らし、次世代ワークフローを実現するのか学びましょう。...

エージェンティックRAGが従来の検索拡張生成をどのように変革し、AIエージェントがインテリジェントな意思決定を行い、複雑な問題を推論し、エンタープライズ向けアプリケーションのために動的にデータ検索を管理できるようにするかをご紹介します。...