From H1 if exists – Start Extraction at the Main Title
Load from pointer – Extract Starting from a Specific Marker
Skip Last Header – Exclude Footer or Redundant Headings
Max tokens – Control the Maximum Output Length
Strategy – Controlling How Multiple Documents Are Transformed to Text
Other parameters of Document Retriever
Document Count
Document Categories
Hide Resources
Schedules
Threshold
Troubleshooting
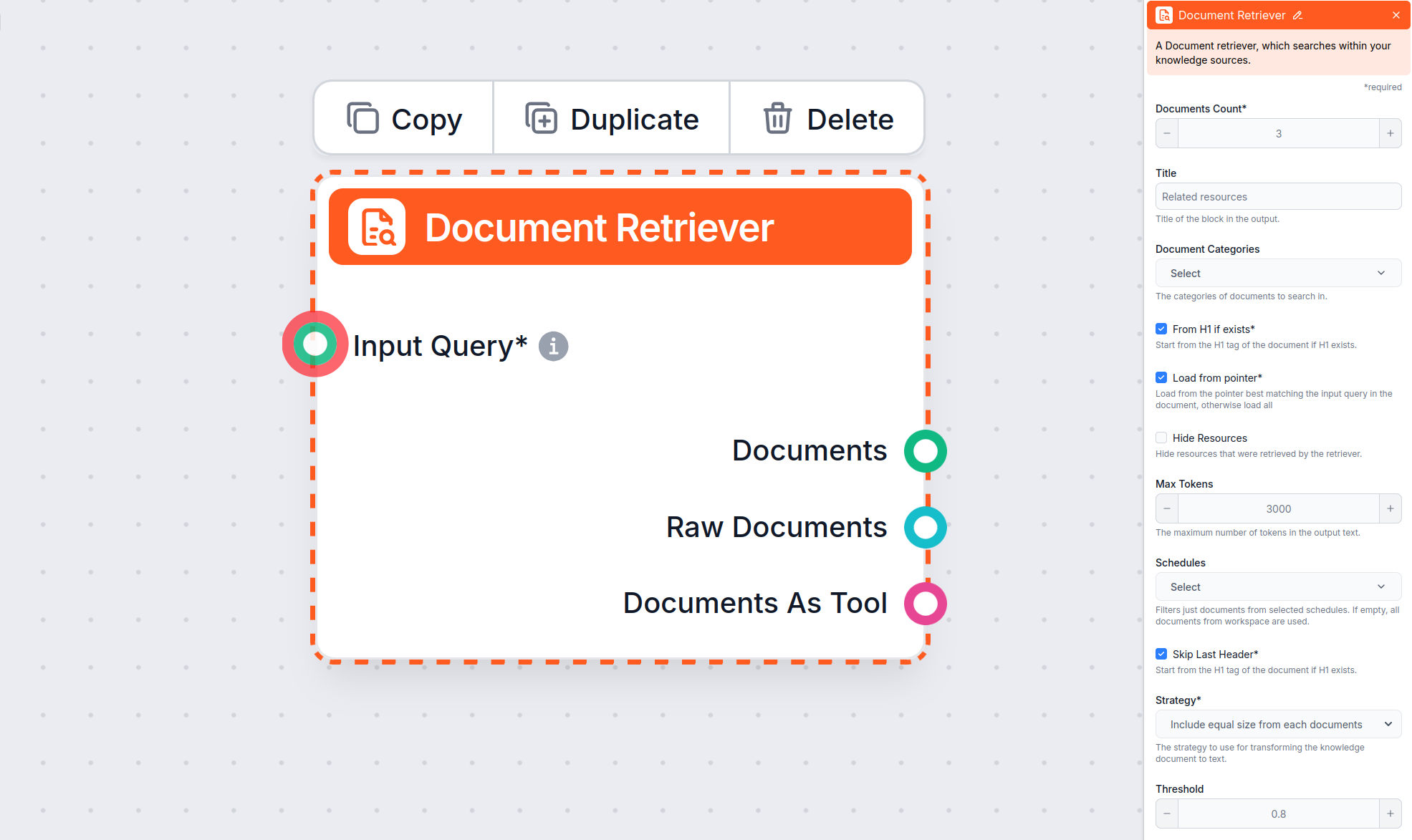
Document Retriever component
allows the chatbot to retrieve knowledge from sources you specified in the Documents and Schedules. The role of this component is to control retrieval, and multiple parameters affect how the component retrieves information from those documents.
From H1 if exists – Start Extraction at the Main Title
The From H1 if exists option tells the retriever to begin extracting content from the H1 header it finds (usually the article’s main title).
What Happens?
If checked: Everything before the first H1 (like navigation, breadcrumbs, or login links) is ignored. Extraction starts at the main article content.
If unchecked: Content extraction begins at the very top of the page, including all navigation, headers, and any metadata above the main article.
Use Case Example: You want to only retrieve the actual guide, without any site navigation or page header clutter that exists on your website.
Note: From H1 if exists is enabled in the Document Retriever component by default.
Load from pointer – Extract Starting from a Specific Marker
The Load from pointer option gives you more precision by allowing Document Retriever to load only data from a pointer in the possibly longer article.
What Happens?
If checked (and a pointer is set): Extraction starts at the specified pointer, skipping everything before it, even if it comes after the H1.
If unchecked: Extraction starts from the default position (top of the document, or from the first H1 if that option is also checked).
What is a “pointer”? A pointer is typically a unique string or heading present in the document (for example, an H2 or a specific phrase or section title).
Use Case Example: You want to skip introductory sections and retrieve information for a specific relevant section of a possibly long article or document (e.g., from “Step 4: Add a live chat button” in a setup guide).
Ready to grow your business?
Start your free trial today and see results within days.
Skip Last Header – Exclude Footer or Redundant Headings
The Skip Last Header option is useful for ignoring the last header in the document, which is often repeated or used for navigation or footer purposes.
What Happens?
If checked: The last header (e.g., a repeated article title or “Other Articles” section) is ignored during extraction.
If unchecked: All headers, including the last one, are included in the output.
Use Case Example: You want to avoid Document Retriever to load a footer navigation header (such as “Other Articles” at the end of a help page), ensuring that only the main content is processed.
Note: Skip Last Header can help with documents that auto-generate footers or repetitive navigation elements. However, if you do not have such sections, using this parameter might cause the part of the article with valid information to not be retrieved. Therefore, it’s recommended to keep this option unchecked until there is a valid reason to enable it.
Max tokens – Control the Maximum Output Length
The Max tokens parameter allows you to control the maximum number of tokens (words and punctuation marks, as counted by the underlying AI model) that the Document Retriever will output from the extracted text.
What Happens?
The extracted content is limited to the specified number of tokens. Any additional content exceeding this limit will be truncated and excluded from the output.
This parameter helps manage very long documents, ensuring that the output remains within the processing limits of AI models.
Default Value: The default value is typically 3000 tokens, but if needed, you can adjust this.
Use Case Example: If you are processing lengthy documents, setting a lower Max tokens value helps keep responses concise. However, for best results, consider enabling the “Load from pointer” parameter. This ensures that the extracted text starts at the most relevant section of the document, rather than from the beginning, allowing you to obtain a focused and manageable chunk of information within your specified token limit. This combination is especially useful when you want concise, contextually relevant outputs from large sources.
Note: If you find that information is being cut off, try increasing the Max tokens value. Conversely, if you want shorter, more focused outputs, reduce the Max tokens parameter.
Strategy – Controlling How Multiple Documents Are Transformed to Text
When the Document Retriever finds several relevant documents, the Strategy parameter determines how they’re merged into a single text output for your chatbot, taking into account the “Max tokens” limit.
Two strategy options:
Include equal size from each document: The token limit is divided evenly. For example, with three documents and a 3,000-token limit, each gets up to 1,000 tokens. This ensures that all sources contribute equally, which is useful when you want a balanced answer that draws from multiple documents.
Use when: You have documentation where different aspects of a topic are distributed across multiple documents, and creating a comprehensive answer requires drawing from several sources equally. This approach is most effective when no single document contains all the necessary details, and you want to ensure that information from each relevant document is represented in the response, thereby providing a diverse or well-rounded perspective.
Concat documents, fill from first up to the tokens limit: Documents are added in order of relevance until the token limit is reached. The most relevant document fills the space first; if there’s room left, less relevant documents are added in order. If the first document is long, it might use the whole limit by itself.
Use when: You have documentation containing detailed information about each topic within a single document, and answering questions would benefit from using as much as possible from this document, rather than combining information from multiple documents that might be about similar topics.
How to choose?
Use Include equal size from each document if you want balanced representation from all sources.
Use Concat documents, fill from first up to tokens limit if you want the most relevant document(s) to be prioritized, and are less concerned about including every source.
Note: These strategies only affect how the text is constructed from the retrieved documents before it is passed to the next step (such as AI generation). They do not change which documents are retrieved—only how their content is merged and trimmed to fit within the Max tokens setting.
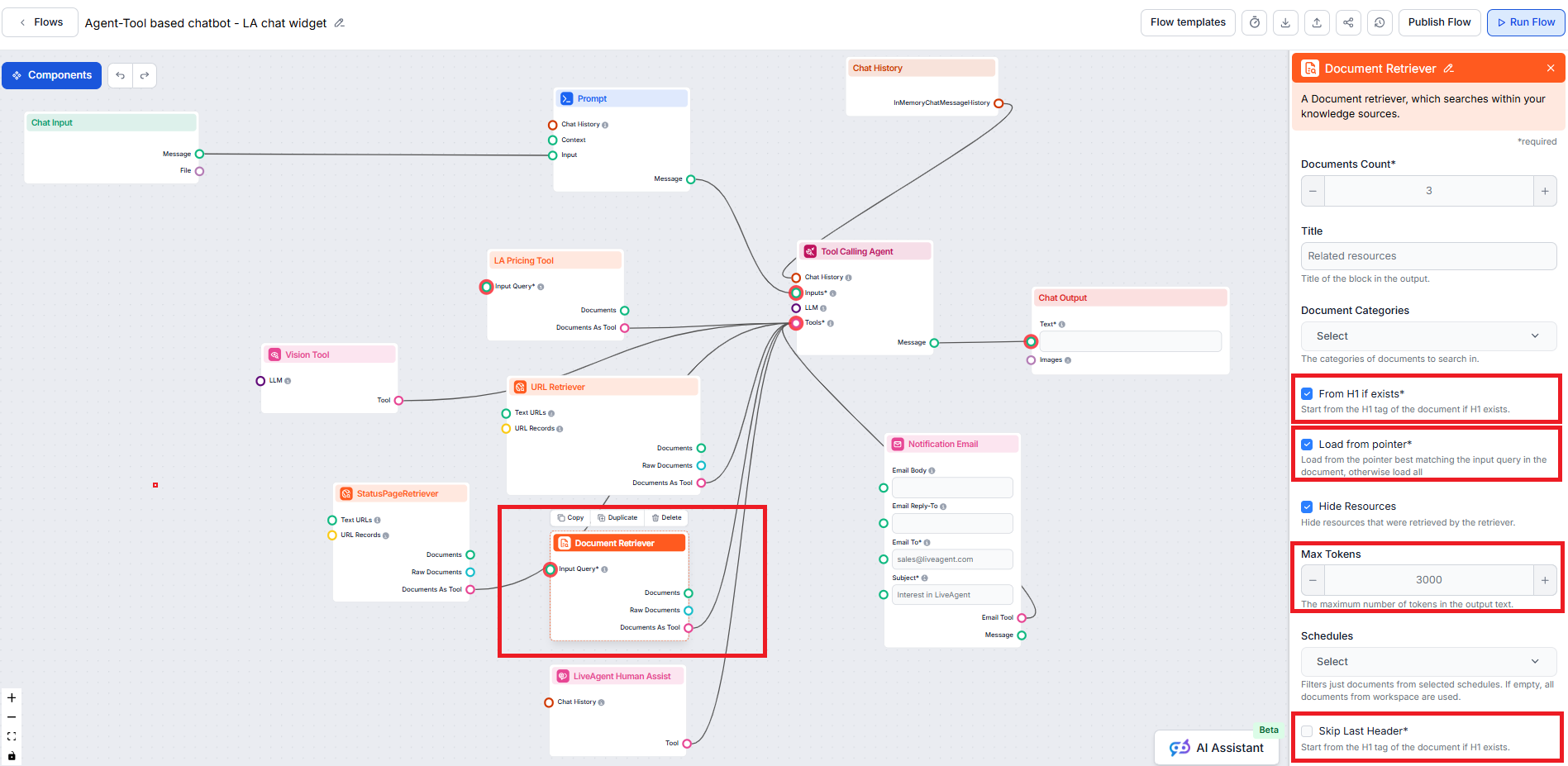
Other parameters of Document Retriever
While this article focuses on setting up the ‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’, and ‘Max tokens’ parameters, the Document Retriever also offers additional parameters that help control how documents are selected and retrieved:
Document Count
This setting limits the number of documents the flow should retrieve, ensuring results remain relevant and responses are generated quickly.
Document Categories
This optional setting allows you to limit retrieval to one or more categories you’ve created in the Documents section of Knowledge Sources.
Hide Resources
This allows you to include or hide a separate section, before the actual chatbot answer, with a list of resources that were retrieved by the retriever. For integration with LiveAgent, it must be checked, as this section is not supported and won’t be displayed correctly in the LiveAgent chatbot widget.
Schedules
Let’s you restrict retrieval to one or more Schedules you have specified for crawling or updating content in Knowledge Sources.
Threshold
Controls how closely the retrieved documents must match the input query, using a relevance score (from 0 to 1). For example, a threshold of 0.7–0.8 is recommended for highly relevant answers. Higher thresholds give more precise matches, while lower thresholds may include less relevant documents.
Example: If you set a threshold of 0.6 and have four articles with relevance scores of 0.8, 0.65, 0.5, and 0.9, only those above 0.6 (i.e., 0.8, 0.65, and 0.9) will be used for extraction.
Troubleshooting
If the answer provided by the chatbot doesn’t contain information that you are certain the chatbot has available in your documents or schedules, try checking the conversation history with the “Verbose” option to see detailed logs of whether the Document Retriever was used and what documents were retrieved. If necessary, adjust your settings and prompt based on these logs.
How to Feed a FlowHunt Chatbot with Selected cPanel Documentation Sections (Not the Whole Site)
A detailed guide for importing only specific sections of docs.cpanel.net into your FlowHunt chatbot, so it becomes an expert in targeted cPanel topics without i...
7 min read
FlowHunt
integrations
+3
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.