AI로 OCR 문제 해결하기
AI 기반 OCR이 데이터 추출을 혁신하고, 문서 처리 자동화와 효율성 향상을 어떻게 이끄는지 알아보세요. 금융, 의료, 리테일 등 다양한 산업에서의 발전 과정, 실제 활용 사례, OpenAI Sora와 같은 최신 솔루션을 소개합니다....
3 분 읽기
AI
OCR
+5

FlowHunt API와 함께 AI 기반 OCR 및 파이썬을 이용해 송장 데이터 추출을 자동화하는 방법을 배워보세요. 빠르고 정확하며 확장 가능한 문서 처리가 가능합니다.
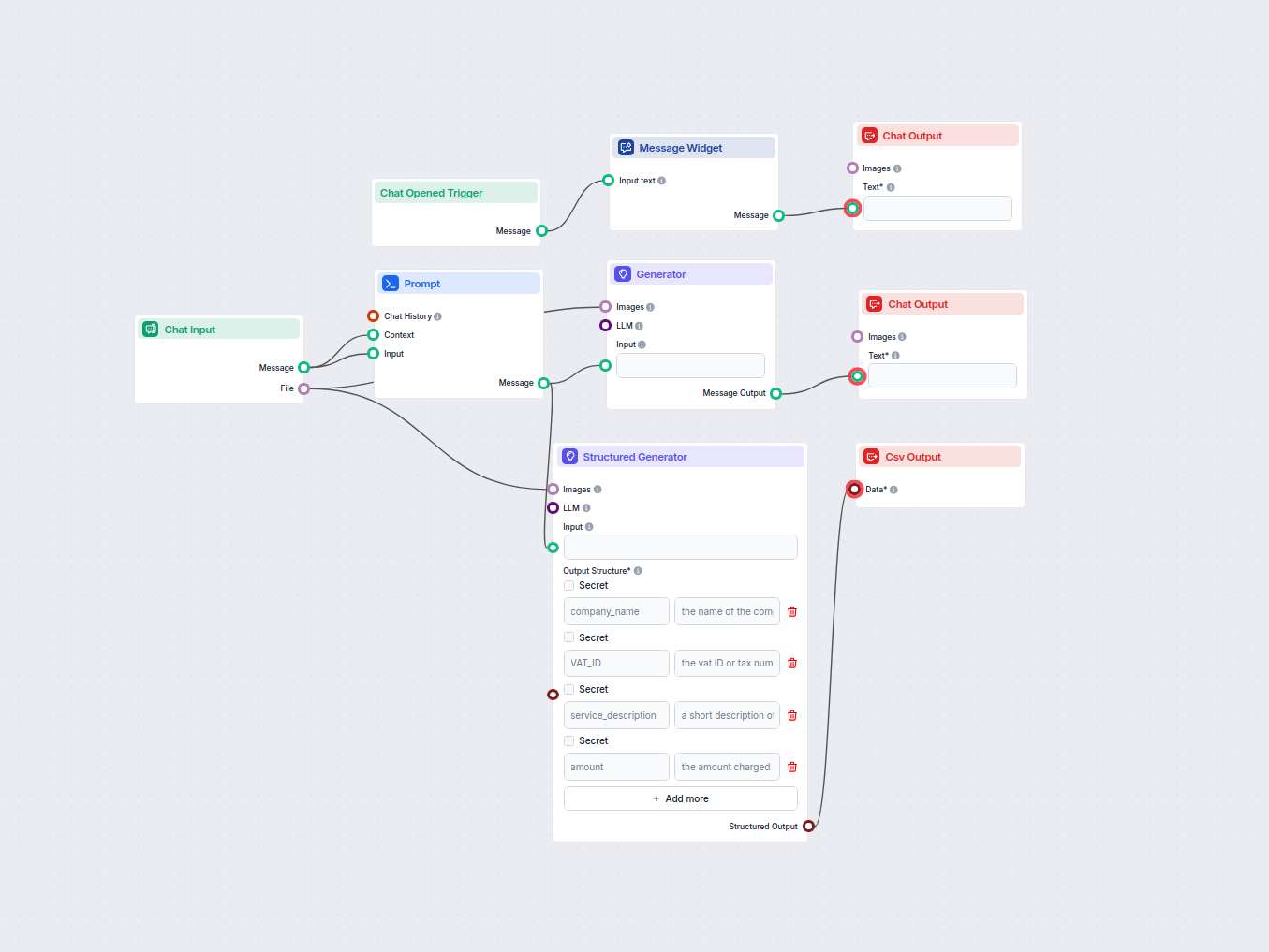
AI 기반 OCR은 기존의 OCR이 가진 한계를 뛰어넘어, 인공지능을 통해 문서의 맥락을 이해하고 다양한 레이아웃을 처리하며, 복잡한 문서에서도 고품질의 구조화된 데이터 추출을 가능하게 합니다. 기존 OCR이 고정된 형식의 텍스트만 인식하는 반면, AI OCR은 송장 등 다양한 비즈니스 문서에서 흔히 볼 수 있는 여러 형태와 구성을 유연하게 처리할 수 있습니다.
회계, 물류, 구매 등 어떤 부서든 송장은 효율적이고 정확하게 처리되어야 합니다. AI OCR은 데이터 추출을 자동화하여 워크플로우를 간소화하고 데이터 정확도를 높입니다.
대부분의 전통적 기업들은 직원이 직접 송장에서 데이터를 추출합니다. 이는 많은 시간과 비용이 소요되며, 세무·법률·금융 등 다양한 분야에서 자동화가 가능한 업무입니다.
이 과정을 FlowHunt로 자동화하면 515초, 0.010.02 크레딧으로 처리할 수 있습니다. 인력을 사용할 경우 시간당 $15~$30이 드는 것과 비교하면 혁신적인 절감입니다.
| 처리 방식 | 연간 비용 | 연간 송장 처리량 | 송장당 비용 |
|---|---|---|---|
| 사람 | $30,000 | 12,000 | $2.50 |
| FlowHunt | $162 | 12,000 | $0.013 |
| FlowHunt (연 $30,000 가정) | $30,000 | 2,250,000 | $0.0133 |
FlowHunt가 압도적으로 효율적임을 알 수 있습니다.
OCR은 매우 유용하지만 몇 가지 도전과제가 있습니다:
이런 문제를 해결하려면 강력하고 유연한 OCR 도구가 필요합니다. FlowHunt API는 복잡한 문서 구조도 안정적으로 처리해 대규모 OCR 프로젝트에 이상적입니다.
프로세스 자동화를 위해 다음 파이썬 라이브러리를 설치하세요:
pip install requests pdf2image git+https://github.com/QualityUnit/flowhunt-python-sdk.git
설치되는 구성요소:
이 코드는 PDF를 이미지로 변환, 각 이미지를 FlowHunt로 전송해 OCR 처리, 결과를 CSV로 저장합니다.
라이브러리 임포트
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
json, os, re, time: JSON 처리, 파일 관리, 정규식, 시간 간격 관리requests: HTTP 요청 및 OCR 결과 다운로드flowhunt: FlowHunt SDK로 인증 및 OCR API 통신pdf2image: PDF 페이지를 이미지로 변환PDF 페이지를 이미지로 변환하는 함수
def convert_pdf_to_image(path: str) -> None:
"""
PDF 파일을 이미지로 변환해 각 페이지를 JPEG로 저장합니다.
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page' + str(i) + '.jpg', 'JPEG')
convert_from_path: 각 PDF 페이지를 이미지로 변환images[i].save: 각 페이지를 JPEG로 저장해 OCR에 활용OCR 결과 첨부파일 URL 추출 함수
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
API 설정 및 인증
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(
host="https://api.flowhunt.io",
api_key={"APIKeyHeader": "<API_KEY_HERE>"}
)
API 클라이언트 초기화
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
workspace_id 획득플로우 세션 시작
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(flow_id=FLOW_ID)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
OCR 처리를 위한 이미지 업로드
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
OCR 처리 요청 및 결과 폴링
invoke_rsp = flows_api.invoke_flow_response(
create_session_rsp.session_id,
flowhunt.FlowSessionInvokeRequest(message="")
)
while True:
get_flow_rsp = flows_api.poll_flow_response(
create_session_rsp.session_id, invoke_rsp.message_id
)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
break
time.sleep(3)
OCR 결과 다운로드 및 저장
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
스크립트 실행 방법:
data/ 폴더에 넣으세요.<FLOW_ID_HERE>, <API_KEY_HERE>를 FlowHunt 계정 정보로 대체하세요.이 파이썬 스크립트는 대규모 문서 처리에 적합한 OCR 자동화 솔루션을 제공합니다. FlowHunt API와 함께라면 문서를 CSV로 쉽게 변환해 워크플로우를 간소화하고 생산성을 높일 수 있습니다.
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
def convert_pdf_to_image(path: str) -> None:
"""
Convert a pdf file to an image
:return:
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page'+ str(i) +'.jpg', 'JPEG')
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(host = "https://api.flowhunt.io",
api_key = {"APIKeyHeader": "<API_KEY_HERE>"})
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(
flow_id=FLOW_ID
)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
invoke_rsp = flows_api.invoke_flow_response(create_session_rsp.session_id, flowhunt.FlowSessionInvokeRequest(
message="",
))
while True:
get_flow_rsp = flows_api.poll_flow_response(create_session_rsp.session_id, invoke_rsp.message_id)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
print("Attachment URL: ", attachment_url, "\n Downloading the file...")
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
break
time.sleep(3)
except ApiException as e:
print("error for file ", image)
print(e)
AI 기반 OCR은 머신러닝과 NLP를 활용하여 문서의 맥락을 이해하고 복잡한 레이아웃을 처리하며, 송장에서 구조화된 데이터를 추출합니다. 기존 OCR은 고정된 형식의 텍스트 인식에 의존하는 반면, AI OCR은 다양한 문서 유형과 레이아웃을 유연하게 처리할 수 있습니다.
AI OCR은 속도, 정확성, 확장성, 구조화된 출력물 제공 등 여러 장점을 지니며, 수작업을 줄이고 오류를 최소화하며, 비즈니스 시스템과의 원활한 통합을 지원합니다.
FlowHunt의 파이썬 SDK를 사용하여 PDF를 이미지로 변환하고, 이 이미지를 FlowHunt API로 보내 OCR 처리 후 구조화된 CSV 데이터를 받아 전체 추출 과정을 자동화할 수 있습니다.
흔한 문제점으로는 저화질 이미지, 복잡한 문서 레이아웃, 다양한 언어 등이 있으며, FlowHunt API는 고급 AI 모델과 유연한 처리 기능으로 이러한 문제를 효과적으로 해결합니다.
FlowHunt의 AI OCR은 사람보다 훨씬 저렴한 비용으로 몇 초 만에 송장을 처리할 수 있어, 탁월한 효율성과 확장성을 제공합니다.
아르시아는 FlowHunt의 AI 워크플로우 엔지니어입니다. 컴퓨터 과학 배경과 AI에 대한 열정을 바탕으로, 그는 AI 도구를 일상 업무에 통합하여 생산성과 창의성을 높이는 효율적인 워크플로우를 설계하는 데 전문성을 가지고 있습니다.
AI 기반 OCR이 데이터 추출을 혁신하고, 문서 처리 자동화와 효율성 향상을 어떻게 이끄는지 알아보세요. 금융, 의료, 리테일 등 다양한 산업에서의 발전 과정, 실제 활용 사례, OpenAI Sora와 같은 최신 솔루션을 소개합니다....
송장 이미지를 업로드하고 송장 번호, 유형, 언어, 품목, 가격, 총액 등 주요 송장 데이터를 추출하여 송장 처리를 자동화합니다. 결과는 마크다운 표와 구조화된 CSV 파일로 출력되어 효율적인 금융 업무를 지원합니다....
광학 문자 인식(OCR)은 스캔된 문서, PDF 또는 이미지를 편집 가능하고 검색 가능한 데이터로 변환하는 혁신적인 기술입니다. OCR의 작동 원리, 종류, 응용 분야, 장점, 한계, 그리고 AI 기반 OCR 시스템의 최신 발전에 대해 알아보세요....