

AI 평가를 위한 LLM 판사(Judge) 활용법
대형 언어 모델을 판사로 활용하여 AI 에이전트와 챗봇을 평가하는 종합 가이드입니다. LLM 판사 평가 방법론, 효과적인 판사 프롬프트 작성법, 평가 지표, 그리고 FlowHunt 도구를 활용한 실전 적용 사례까지 모두 배우실 수 있습니다....
6 분 읽기
AI
LLM
+10

FlowHunt의 새로운 오픈소스 CLI 툴킷은 LLM 판사 기반의 종합 플로우 평가와 상세 리포팅, AI 워크플로우의 자동 품질 진단을 제공합니다.
우리는 FlowHunt CLI 툴킷 출시를 기쁜 마음으로 알립니다. 이 오픈소스 명령줄 도구는 AI 플로우의 평가와 테스트 방식을 혁신적으로 개선하도록 설계되었습니다. 엔터프라이즈급 플로우 평가 역량과 고급 리포팅, 그리고 혁신적인 “LLM 판사” 구현을 오픈소스 커뮤니티에 제공합니다.
FlowHunt CLI 툴킷은 AI 워크플로우 테스트와 평가 분야에서 중요한 진전을 의미합니다. GitHub에서 지금 바로 사용할 수 있으며, 개발자들에게 다음과 같은 종합 도구를 제공합니다:
이 툴킷은 투명성과 커뮤니티 중심 개발에 대한 우리의 의지를 담고 있으며, 전 세계 개발자들에게 고급 AI 평가 기술을 개방합니다.
CLI 툴킷의 가장 혁신적인 기능 중 하나는 “LLM 판사” 구현입니다. 이 방식은 인공지능이 AI 생성 응답의 품질과 정확도를 평가하도록 하여, AI가 AI의 성능을 정교한 추론 능력으로 심사할 수 있게 합니다.
우리의 구현이 특별한 이유는 평가 플로우 자체를 FlowHunt로 구축했다는 점입니다. 이 메타적인 방식은 플랫폼의 파워와 유연성을 입증함과 동시에, 강력한 평가 시스템을 제공합니다. LLM 판사 플로우는 여러 상호 연결된 컴포넌트로 구성됩니다:
1. 프롬프트 템플릿: 평가 기준이 적용된 프롬프트를 생성
2. 구조적 출력 생성기: LLM을 활용해 평가를 처리
3. 데이터 파서: 결과를 리포팅용 구조로 포맷
4. 채팅 출력: 최종 평가 결과를 표시
LLM 판사 시스템의 핵심은 일관성 있고 신뢰도 높은 평가를 보장하는 정교한 프롬프트입니다. 다음은 우리가 사용하는 주요 프롬프트 템플릿입니다:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
이 프롬프트는 LLM 판사가 다음을 제공하도록 보장합니다:
LLM 판사 플로우는 FlowHunt의 시각적 플로우 빌더로 구축된 정교한 AI 워크플로우 설계의 예시입니다. 각 컴포넌트는 다음과 같이 협업합니다:
플로우는 채팅 입력 컴포넌트로 시작하며, 실제 응답과 기준 답변이 포함된 평가 요청을 받습니다.
프롬프트 템플릿 컴포넌트는 다음과 같이 동적으로 프롬프트를 만듭니다:
{target_response} 자리에 삽입{actual_response} 자리에 삽입구조적 출력 생성기가 선택된 LLM으로 프롬프트를 처리하여 다음을 생성합니다:
total_rating: 1~4점 수치 평가correctness: 정오 이진 분류reasoning: 상세 평가 이유데이터 파서 컴포넌트가 구조화된 결과를 읽기 쉬운 형태로 변환하고, 채팅 출력 컴포넌트가 최종 평가 결과를 표시합니다.
LLM 판사 시스템은 AI 플로우 평가에 특히 효과적인 여러 고급 기능을 제공합니다:
단순 문자열 일치와 달리, LLM 판사는
4점 척도는 세밀한 평가를 가능하게 합니다:
각 평가에는 상세한 이유가 포함되어 있어,
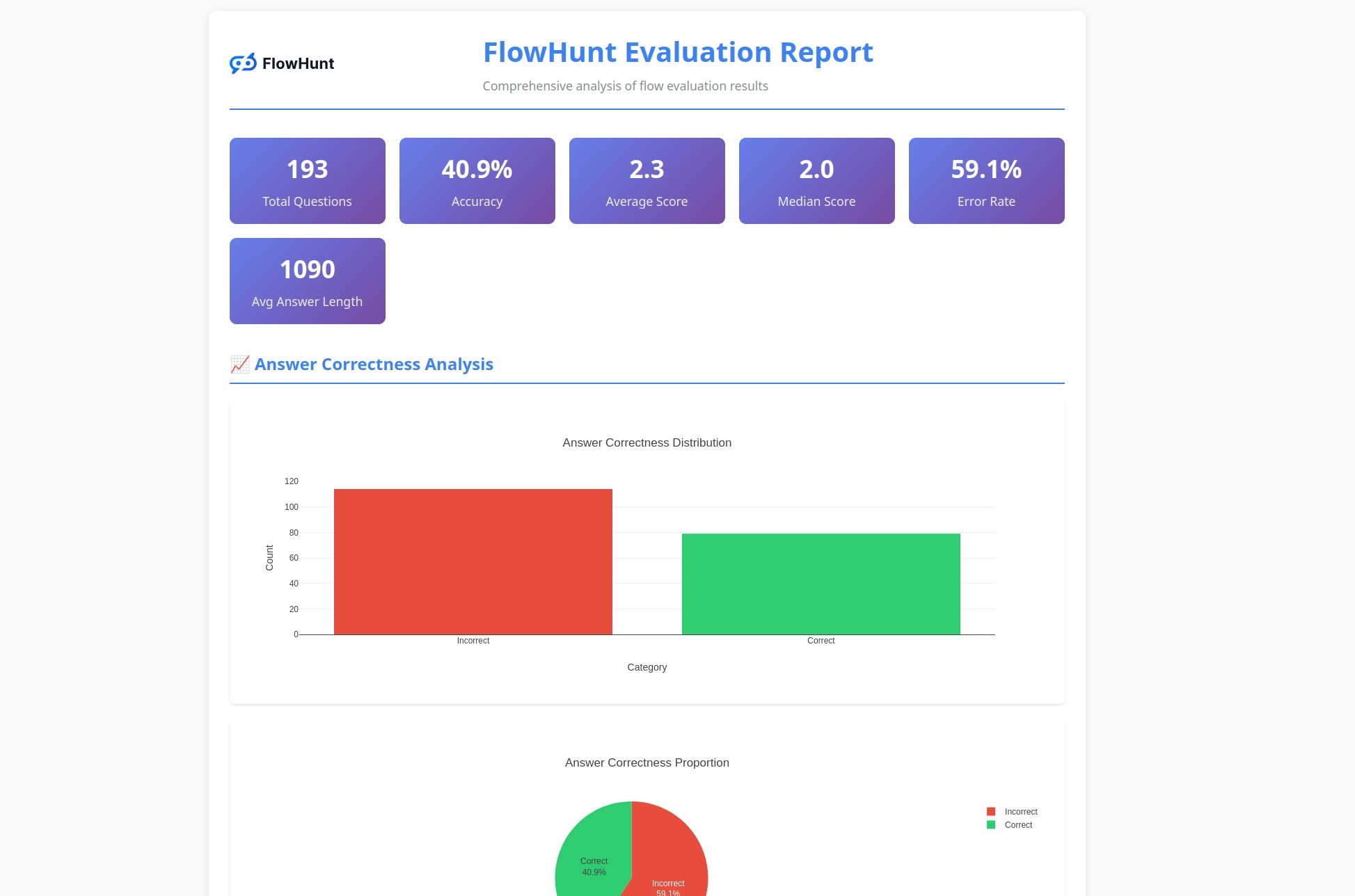
CLI 툴킷은 플로우 성능에 대한 실질적 인사이트를 제공하는 상세 리포트를 생성합니다:
전문가 수준 도구로 AI 플로우 평가를 시작할 준비가 되셨나요? 시작 방법은 다음과 같습니다:
원라인 설치(권장) - macOS 및 Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
이 명령어로 자동으로:
flowhunt 명령어 PATH에 등록수동 설치:
# 저장소 클론
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# pip로 설치
pip install -e .
설치 확인:
flowhunt --help
flowhunt --version
1. 인증 먼저 FlowHunt API에 인증하세요:
flowhunt auth
2. 플로우 목록 확인
flowhunt flows list
3. 플로우 평가 테스트 데이터를 CSV 파일로 준비하세요:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
LLM 판사로 평가 실행:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. 플로우 일괄 실행
flowhunt batch-run your-flow-id input.csv --output-dir results/
평가 시스템은 종합 분석을 제공합니다:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
주요 기능:
CLI 툴킷은 FlowHunt 플랫폼과 완벽하게 연동되어,
CLI 툴킷 출시는 단순한 도구 제공을 넘어, 다음과 같은 AI 개발의 미래 비전을 제시합니다:
품질의 계량화: 고급 평가 기술로 AI 성능을 수치화하고 비교 가능하게 만듭니다.
테스트의 자동화: 종합 테스트 프레임워크로 수작업을 줄이고 신뢰성을 높입니다.
투명성의 표준화: 상세 이유와 리포팅으로 AI 동작을 이해하고 디버깅할 수 있습니다.
커뮤니티 중심 혁신: 오픈소스 도구로 협업적 개선과 지식 공유를 촉진합니다.
FlowHunt CLI 툴킷의 오픈소스화는 우리의 다음과 같은 약속을 보여줍니다:
LLM 판사 기반 FlowHunt CLI 툴킷은 AI 플로우 평가 역량의 획기적 발전을 의미합니다. 정교한 평가 논리, 종합 리포팅, 오픈소스 접근성을 결합해, 더 나은 신뢰성의 AI 시스템 개발을 개발자에게 제공합니다.
FlowHunt 자체로 FlowHunt 플로우를 평가하는 메타적 접근은 플랫폼의 성숙함과 유연성을 입증함과 동시에, 더 넓은 AI 개발 커뮤니티에 강력한 도구를 제공합니다.
단순 챗봇부터 복잡한 멀티에이전트 시스템까지, FlowHunt CLI 툴킷은 품질, 신뢰성, 지속적 개선을 위한 평가 인프라를 제공합니다.
AI 플로우 평가의 수준을 높이고 싶으신가요? GitHub 저장소에서 FlowHunt CLI 툴킷을 지금 시작해보세요. LLM 판사의 강력함을 직접 경험할 수 있습니다.
AI 개발의 미래는 이미 시작되었습니다. 그리고 그 미래는 오픈소스입니다.
FlowHunt CLI 툴킷은 AI 플로우를 종합적으로 평가하고 리포팅할 수 있는 오픈소스 명령줄 도구입니다. LLM 판사 평가, 정오 결과 분석, 상세 성능 메트릭 등 다양한 기능을 제공합니다.
LLM 판사는 FlowHunt 내에서 직접 구축된 정교한 AI 플로우를 활용해 다른 플로우를 평가합니다. 실제 응답과 기준 답변을 비교해 점수, 정오 판정, 상세 이유를 제공합니다.
FlowHunt CLI 툴킷은 오픈소스로 GitHub(https://github.com/yasha-dev1/flowhunt-toolkit)에서 제공됩니다. 자유롭게 클론, 기여, 사용이 가능합니다.
툴킷은 정오 결과 분포, LLM 판사 평가(점수와 이유), 성능 메트릭, 다양한 테스트 케이스별 플로우 동작 분석 등 종합적인 리포트를 제공합니다.
네! LLM 판사 플로우는 FlowHunt 플랫폼으로 제작되어 다양한 평가 시나리오에 맞게 수정할 수 있습니다. 프롬프트 템플릿과 평가 기준을 원하는 대로 변경해 활용할 수 있습니다.
야샤는 파이썬, 자바, 머신러닝을 전문으로 하는 재능 있는 소프트웨어 개발자입니다. 야샤는 AI, 프롬프트 엔지니어링, 챗봇 개발에 관한 기술 기사를 작성합니다.
대형 언어 모델을 판사로 활용하여 AI 에이전트와 챗봇을 평가하는 종합 가이드입니다. LLM 판사 평가 방법론, 효과적인 판사 프롬프트 작성법, 평가 지표, 그리고 FlowHunt 도구를 활용한 실전 적용 사례까지 모두 배우실 수 있습니다....
FlowHunt의 LLM 컨텍스트를 통합하여 AI 지원 개발을 가속화하세요. 스마트 파일 선택, 고급 컨텍스트 관리, 직접적인 LLM 통합을 통해 관련 코드 및 문서 컨텍스트를 선호하는 대형 언어 모델 챗 인터페이스에 원활하게 주입할 수 있습니다....
FlowHunt와 Patronus MCP 서버를 통합하여 LLM 시스템의 최적화, 평가, 실험을 간소화하세요. AI 모델 테스트를 표준화하고, 데이터셋에서 실험을 자동화하며, 고급 모델 품질 보증을 위한 맞춤 평가기와 기준을 관리할 수 있습니다....