
json2video-mcp
FlowHunt를 json2video-mcp 서버와 연동하여 프로그램 방식의 동영상 생성 자동화, 맞춤형 템플릿 관리, 안전하고 유연한 API를 통한 에이전트, LLM, 자동화 도구와의 동영상 워크플로우 연결을 구현하세요....
3 분 읽기
AI
Video Automation
+3

Wan 2.1은 Alibaba에서 개발한 강력한 오픈소스 AI 비디오 생성 모델로, 텍스트나 이미지만으로 스튜디오급 영상을 누구나 무료로 직접 생성할 수 있습니다.
Wan 2.1(또는 WanX 2.1)은 Alibaba의 Tongyi Lab에서 개발한 완전 오픈소스 AI 비디오 생성 모델로, 영상 생성 분야의 새로운 지평을 열고 있습니다. 고가의 구독료나 API 접근이 필요한 기존 상용 비디오 생성 시스템과 달리, Wan 2.1은 동등하거나 더 뛰어난 품질을 제공하면서도 개발자, 연구자, 크리에이티브 전문가 누구에게나 완전히 무료로 개방되어 있습니다.
Wan 2.1의 진정한 강점은 접근성과 성능의 조화에 있습니다. 소형 T2V-1.3B 버전은 약 8.2GB의 GPU 메모리만 필요해, 대부분의 최신 소비자용 GPU에서 바로 사용할 수 있습니다. 대형 14B 파라미터 버전은 오픈소스 및 상용 모델을 표준 벤치마크에서 뛰어넘는 최첨단 성능을 보여줍니다.
Wan 2.1은 단순한 텍스트-투-비디오 생성에만 국한되지 않습니다. 다양한 아키텍처로 아래 작업을 지원합니다:
이처럼 유연한 구조 덕분에, 텍스트 프롬프트, 정지 이미지, 심지어 기존 영상을 시작점으로 삼아 원하는 대로 변환할 수 있습니다.
Wan 2.1은 생성된 영상 내에 읽을 수 있는 영어 및 중국어 텍스트를 렌더링할 수 있는 최초의 비디오 모델로, 글로벌 크리에이터를 위한 새로운 가능성을 엽니다. 이 기능은 다국어 자막이나 씬 텍스트가 필요한 영상 제작에 특히 유용합니다.
Wan 2.1의 효율성 중심에는 3D 인과적 Video Variational Autoencoder가 자리합니다. 이 획기적 기술은 시공간 정보를 고효율로 압축하여 모델이 다음과 같은 이점을 갖게 합니다:
소형 1.3B 모델은 단 8.19GB VRAM만 필요하며, RTX 4090에서 약 4분 만에 5초 분량의 480p 영상을 생성할 수 있습니다. 이처럼 효율적임에도 품질은 훨씬 덩치 큰 모델과 견줄 만하거나 능가해, 속도와 화질의 완벽한 균형을 이룹니다.
공개 평가에서 Wan 14B는 Wan-Bench 테스트에서 최고 종합 점수를 기록하며 경쟁 모델을 크게 앞질렀습니다:
OpenAI의 Sora나 Runway의 Gen-2 같은 폐쇄형 시스템과 달리, Wan 2.1은 자유롭게 로컬에서 실행할 수 있습니다. 기존의 오픈소스 모델(CogVideo, MAKE-A-VIDEO, Pika 등)은 물론, 다수 상용 솔루션보다도 품질 벤치마크에서 앞섭니다.
최근 업계 조사에서는 “다수의 AI 비디오 모델 중 Wan 2.1과 Sora가 두드러진다”고 평가했는데, Wan 2.1은 개방성과 효율성에서, Sora는 독자적 혁신에서 강점을 보입니다. 커뮤니티 테스트에서도 Wan 2.1의 이미지-투-비디오 기능이 선명도와 시네마틱한 느낌에서 타 모델을 압도한다는 평이 이어지고 있습니다.
Wan 2.1은 확산-트랜스포머 백본과 새로운 시공간 VAE를 기반으로 설계되었습니다. 작동 방식은 다음과 같습니다:
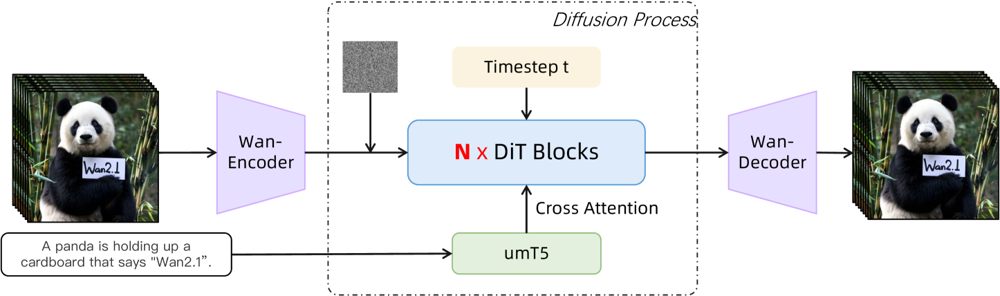
그림: Wan 2.1의 상위 아키텍처(텍스트-투-비디오 예시). 영상(또는 이미지)은 Wan-VAE 인코더에 의해 먼저 잠재 표현으로 인코딩됩니다. 이 잠재 표현은 N개의 확산 트랜스포머 블록을 거치며, 이때 텍스트 임베딩(umT5에서 추출)과 교차 어텐션으로 결합됩니다. 마지막으로 Wan-VAE 디코더가 영상 프레임을 복원합니다. 이 설계(“확산 트랜스포머를 감싼 3D 인과적 VAE 인코더/디코더 구조” (ar5iv.org))는 시공간 데이터의 효율적 압축과 고품질 비디오 출력을 모두 가능하게 만듭니다.
이 혁신적 아키텍처, 즉 “확산 트랜스포머를 감싼 3D 인과적 VAE 인코더/디코더” 구조는 시공간 데이터의 효율적 압축과 고품질 비디오 생성을 동시에 구현합니다.
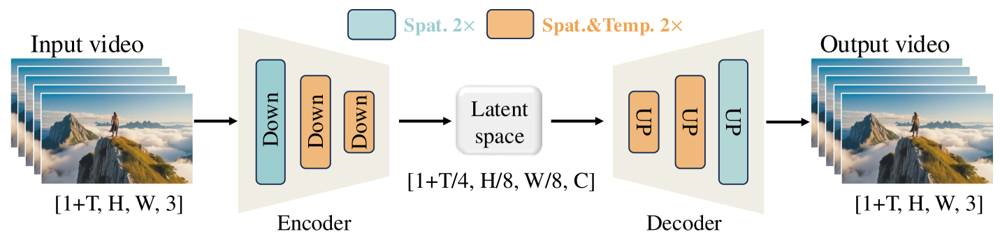
Wan-VAE는 영상에 특화되어 설계되었습니다. 입력을 시간 4배, 공간 8배(총 32배)로 압축해 컴팩트한 잠재 표현으로 만든 뒤, 이를 다시 풀어서 완전한 영상을 복원합니다. 3D 컨볼루션과 인과(시간 보존) 레이어를 활용해 생성물 전반에 걸쳐 일관된 움직임을 보장합니다.
그림: Wan 2.1의 Wan-VAE 프레임워크(인코더-디코더 구조). Wan-VAE 인코더(좌측)는 입력 영상(프레임 형태 [1+T, H, W, 3])에 다운샘플링 레이어(“Down”)를 연속적으로 적용해, 컴팩트한 잠재 표현([1+T/4, H/8, W/8, C])으로 만듭니다. Wan-VAE 디코더(우측)는 이 잠재 표현을 대칭적으로 업샘플링(“UP”)하여 원본 영상 프레임으로 복원합니다. 파란색 블록은 공간 압축, 주황색 블록은 공간+시간 동시 압축을 의미합니다(ar5iv.org). 시공간 볼륨 기준 256배 압축을 통해 Wan-VAE는 후속 확산 모델의 고해상도 비디오 모델링을 현실적으로 가능하게 만듭니다.
직접 Wan 2.1을 써보고 싶으신가요? 아래 단계를 따라 시작할 수 있습니다.
저장소 클론 및 의존성 설치:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
모델 가중치 다운로드:
pip install "huggingface_hub[cli]"
huggingface-cli login
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
첫 비디오 생성:
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
--offload_model True --t5_cpu 옵션으로 일부를 CPU로 오프로드할 수 있습니다--size 파라미터(예: 832*480)로 해상도/화면비 조절 가능합니다참고로 RTX 4090에서 5초 분량의 480p 영상을 약 4분 만에 생성할 수 있습니다. 대규모 사용을 위한 다중 GPU, FSDP, 양자화 등 다양한 성능 최적화도 지원됩니다.
Wan 2.1은 AI 비디오 생성의 거인들과 맞서는 오픈소스 강자로, 접근성의 새로운 전환점을 제시합니다. 무료이자 오픈소스라는 점 덕분에, 적당한 GPU만 있다면 누구나 최신 비디오 생성 기술을 구독료나 API 비용 없이 직접 경험할 수 있습니다.
개발자들에게는 오픈 라이선스로 모델 커스터마이즈와 개선이 가능하며, 연구자는 기능 확장, 크리에이터는 빠르고 효율적으로 영상 프로토타입을 제작할 수 있습니다.
점점 더 많은 AI 모델이 폐쇄적이고 유료화되는 시대에, Wan 2.1은 최첨단 성능도 모두가 누릴 수 있도록 민주화될 수 있음을 보여줍니다.
Wan 2.1은 Alibaba의 Tongyi Lab에서 개발한 완전 오픈소스 AI 비디오 생성 모델로, 텍스트 프롬프트, 이미지, 기존 영상을 활용해 고품질 비디오를 생성할 수 있습니다. 누구나 무료로 사용할 수 있고, 다양한 작업을 지원하며, 일반 소비자 GPU에서도 효율적으로 실행됩니다.
Wan 2.1은 멀티태스크 비디오 생성(텍스트-투-비디오, 이미지-투-비디오, 비디오 편집 등), 영상 내 다국어 텍스트 렌더링, 3D 인과적 Video VAE 기반의 높은 효율성, 그리고 벤치마크에서 상용 및 오픈소스 모델을 뛰어넘는 성능이 특징입니다.
Python 3.8 이상, CUDA가 지원되는 PyTorch 2.4.0 이상, NVIDIA GPU(소형 모델은 8GB 이상, 대형 모델은 16-24GB VRAM 필요)가 필요합니다. GitHub 저장소를 클론하고, 의존성 설치, 모델 가중치 다운로드 후 제공되는 스크립트로 직접 영상을 생성할 수 있습니다.
Wan 2.1은 오픈소스이자 무료로 제공되어, 최신 비디오 생성 기술 접근성을 혁신적으로 높입니다. 개발자, 연구자, 크리에이터가 비용 부담이나 폐쇄적 제한 없이 자유롭게 실험하고 혁신할 수 있습니다.
Sora, Runway Gen-2 같은 폐쇄형 모델들과 달리, Wan 2.1은 완전 오픈소스이며 로컬에서 실행 가능합니다. 기존 오픈소스 모델은 물론, 다수의 상용 솔루션보다 품질 벤치마크에서 뛰어납니다.
아르시아는 FlowHunt의 AI 워크플로우 엔지니어입니다. 컴퓨터 과학 배경과 AI에 대한 열정을 바탕으로, 그는 AI 도구를 일상 업무에 통합하여 생산성과 창의성을 높이는 효율적인 워크플로우를 설계하는 데 전문성을 가지고 있습니다.
FlowHunt에서 직접 나만의 AI 도구와 비디오 생성 워크플로를 구축하거나, 플랫폼 시연을 예약해 실제 활용 사례를 경험해보세요.
FlowHunt를 json2video-mcp 서버와 연동하여 프로그램 방식의 동영상 생성 자동화, 맞춤형 템플릿 관리, 안전하고 유연한 API를 통한 에이전트, LLM, 자동화 도구와의 동영상 워크플로우 연결을 구현하세요....
Gemini Flash 2.0은 향상된 성능, 속도, 멀티모달 기능으로 AI의 새로운 기준을 제시합니다. 실제 적용 사례에서 그 잠재력을 탐구해보세요....
'영상에서 자막 추출하기' 플로우가 동영상 자막을 손쉽게 읽을 수 있는 텍스트로 변환하는 방법을 알아보세요. 이 도구는 교육, 업무, 개인적인 용도 모두에 완벽하며 접근성과 효율성을 높여줍니다. FlowHunt에서 기능과 장점에 대해 더 알아보세요....

