
정보 검색
정보 검색은 AI, 자연어 처리(NLP), 그리고 기계 학습을 활용하여 사용자의 요구를 충족하는 데이터를 효율적이고 정확하게 검색합니다. 웹 검색 엔진, 디지털 도서관, 엔터프라이즈 솔루션의 기반이 되는 IR은 모호성, 알고리즘 편향, 확장성 등 다양한 과제를 해결하며, 미래에는 생성형...
5 분 읽기
Information Retrieval
AI
+4

AI 검색은 머신러닝과 벡터 임베딩을 활용해 검색 의도와 맥락을 이해하여, 단순한 키워드 일치 이상의 매우 관련성 높은 결과를 제공합니다.
AI 검색은 머신러닝을 활용해 검색 쿼리의 맥락과 의도를 이해하고, 이를 수치 벡터로 변환하여 더욱 정확한 결과를 제공합니다. 기존의 키워드 검색과 달리, AI 검색은 의미적 관계를 해석해 다양한 데이터 유형과 언어에 효과적입니다.
AI 검색(의미 기반 검색 또는 벡터 검색이라고도 함)은 머신러닝 모델을 활용해 검색 쿼리의 의도와 맥락적 의미를 이해하는 검색 방법론입니다. 기존의 키워드 기반 검색과 달리, AI 검색은 데이터와 쿼리를 벡터(임베딩)라는 수치적 표현으로 변환합니다. 이를 통해 서로 다른 데이터 간 의미적 관계를 파악하여, 정확한 키워드가 없어도 더 관련성 높고 정확한 결과를 제공합니다.
AI 검색은 검색 기술의 혁신적인 진보를 의미합니다. 기존 검색엔진은 쿼리와 문서 모두에 특정 키워드가 존재하는지를 기반으로 결과의 관련성을 평가합니다. 반면 AI 검색은 머신러닝 모델을 통해 쿼리와 데이터의 맥락과 의미를 파악합니다.
텍스트, 이미지, 오디오 등 비정형 데이터를 고차원 벡터로 변환함으로써, AI 검색은 다양한 콘텐츠 간의 유사성을 측정할 수 있습니다. 이 방식은 검색 쿼리에 정확한 키워드가 없어도 맥락적으로 적합한 결과를 제공할 수 있게 해줍니다.
핵심 요소:
AI 검색의 핵심은 벡터 임베딩 개념에 있습니다. 벡터 임베딩은 텍스트, 이미지 등 다양한 데이터의 의미를 수치적으로 표현한 고차원 벡터입니다. 유사한 데이터는 벡터 공간에서 서로 가까운 위치에 놓이게 됩니다.
작동 방식:
예시:
기존 키워드 기반 검색엔진은 쿼리와 문서에서 동일한 단어가 있는지를 확인하고, 역색인과 단어 빈도 등의 기법으로 결과를 산정합니다.
키워드 기반 검색의 한계:
AI 검색의 장점:
| 구분 | 키워드 기반 검색 | AI 검색 (의미/벡터 기반) |
|---|---|---|
| 일치 방식 | 정확한 키워드 일치 | 의미적 유사성 |
| 맥락 인식 | 제한적 | 높음 |
| 동의어 처리 | 수동 동의어 목록 필요 | 임베딩으로 자동 인식 |
| 오타 처리 | 퍼지 검색 없으면 실패 가능 | 의미 기반으로 오타에도 관대함 |
| 의도 이해 | 최소 | 매우 큼 |
의미 기반 검색(Semantic Search)은 사용자의 의도와 쿼리의 맥락적 의미를 이해하는 AI 검색의 핵심 응용입니다.
프로세스:
주요 기술:
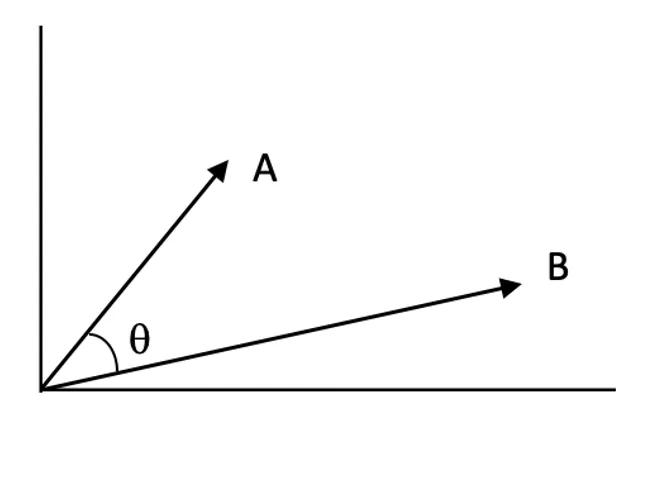
유사도 점수:
벡터 공간에서 두 벡터가 얼마나 유사한지 수치로 표현한 값입니다. 점수가 높을수록 쿼리와 문서의 관련성이 높음을 의미합니다.
근사 최근접 이웃(ANN) 알고리즘:
고차원 공간에서 정확한 최근접 이웃을 찾는 것은 연산량이 많으므로, ANN 알고리즘으로 근사적으로 빠르게 찾을 수 있습니다.
AI 검색은 단순 키워드 일치를 뛰어넘는 데이터 이해력으로 다양한 산업에서 폭넓게 활용됩니다.
설명: 쿼리의 의도를 해석하여 맥락적으로 적합한 결과를 반환해 사용자 경험을 향상시킵니다.
예시:
설명: 사용자 선호와 행동을 분석해 맞춤형 콘텐츠나 상품을 추천합니다.
예시:
설명: 문서에서 정밀하게 정보를 추출해, 사용자의 질문에 정확한 답을 제공합니다.
예시:
설명: 이미지, 오디오, 영상 등 비정형 데이터도 임베딩 변환 후 검색 가능
예시:
AI 검색을 자동화 시스템과 챗봇에 통합하면 기능이 크게 강화됩니다.
주요 효과:
구현 단계:
활용 예시:
AI 검색에는 다양한 장점이 있지만, 다음과 같은 도전 과제도 있습니다.
해결 전략:
AI의 의미/벡터 검색은 기존 키워드 및 퍼지 검색에 비해 쿼리의 맥락과 의미를 이해하여, 결과의 관련성과 정확성을 크게 높이는 강력한 대안으로 주목받고 있습니다.
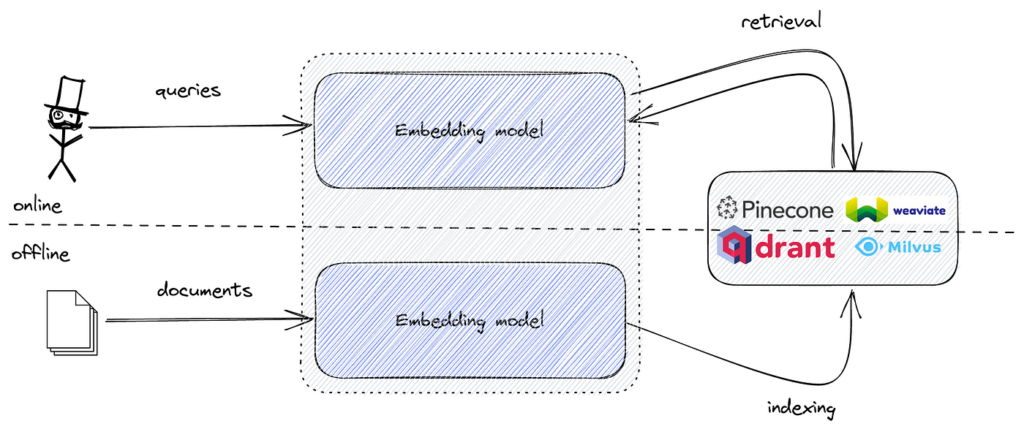
의미 기반 검색 구현 시, 텍스트 데이터를 의미 정보를 담은 벡터 임베딩으로 변환합니다. 이 임베딩은 고차원 수치 벡터입니다. 쿼리 임베딩과 가장 유사한 임베딩을 효율적으로 탐색하려면 고차원 유사도 검색에 특화된 도구가 필요합니다.
FAISS는 이 작업을 빠르고 효율적으로 처리하는 알고리즘과 데이터 구조를 제공합니다. 의미 임베딩과 FAISS를 결합하면, 대용량 데이터셋도 저지연으로 처리하는 강력한 의미 기반 검색 엔진을 구축할 수 있습니다.
Python에서 FAISS로 의미 기반 검색을 구현하는 기본 단계는 다음과 같습니다.
각 단계를 자세히 살펴보겠습니다.
데이터셋(예: 기사, 지원 티켓, 상품 설명 등)을 준비합니다.
예시:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
필요에 따라 텍스트 데이터를 정제·포맷팅합니다.
Hugging Face의 transformers나 sentence-transformers와 같은 라이브러리의 사전학습 트랜스포머 모델을 활용해 텍스트를 임베딩으로 변환합니다.
예시:
from sentence_transformers import SentenceTransformer
import numpy as np
# 사전학습 모델 불러오기
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 전체 문서 임베딩 생성
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
임베딩을 저장하고 효율적으로 검색할 수 있도록 FAISS 인덱스를 생성합니다.
예시:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2는 L2(유클리드 거리) 기반 완전탐색을 수행합니다.사용자 쿼리를 임베딩 변환 후, 최근접 이웃 검색을 수행합니다.
예시:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
검색된 인덱스를 활용해 관련 문서를 표시합니다.
예시:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
예상 출력:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS는 다양한 인덱스 타입을 제공합니다.
인버티드 파일 인덱스(IndexIVFFlat) 사용 예시:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
정규화 및 내적 기반 검색:
텍스트 데이터에 코사인 유사도를 사용하는 것이 더 효과적일 수 있습니다.
AI 검색은 머신러닝과 벡터 임베딩을 활용해 쿼리의 의도와 맥락적 의미를 이해하여, 기존 키워드 기반 검색보다 더 정확하고 관련성 높은 결과를 제공하는 현대적인 검색 방법론입니다.
키워드 기반 검색은 정확한 일치에 의존하는 반면, AI 검색은 쿼리의 의미적 관계와 의도를 해석하여 자연어와 모호한 입력에도 효과적으로 대응합니다.
벡터 임베딩은 텍스트, 이미지, 기타 데이터 유형의 의미를 수치적으로 표현한 것으로, 서로 다른 데이터 간의 의미적 유사성과 맥락을 측정할 수 있게 해줍니다.
AI 검색은 이커머스의 의미 검색, 스트리밍의 개인화 추천, 고객 지원의 질의응답 시스템, 비정형 데이터 탐색, 연구 및 엔터프라이즈의 문서 검색 등에 활용됩니다.
효율적인 벡터 유사도 검색을 위한 FAISS, 그리고 Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch, Pgvector와 같은 벡터 데이터베이스가 대표적입니다.
AI 검색을 통합하면 챗봇과 자동화 시스템이 사용자 쿼리를 더 깊이 이해하고, 맥락적으로 적합한 답변을 찾아 동적이고 개인화된 응답을 제공할 수 있습니다.
높은 연산 자원 요구, 모델 해석의 복잡성, 고품질 데이터 필요성, 민감 정보의 보안 및 프라이버시 확보 등이 주요 과제입니다.
FAISS는 고차원 벡터 임베딩의 효율적 유사도 검색을 위한 오픈소스 라이브러리로, 대규모 데이터셋을 처리할 수 있는 의미 기반 검색 엔진 구축에 널리 활용됩니다.
정보 검색은 AI, 자연어 처리(NLP), 그리고 기계 학습을 활용하여 사용자의 요구를 충족하는 데이터를 효율적이고 정확하게 검색합니다. 웹 검색 엔진, 디지털 도서관, 엔터프라이즈 솔루션의 기반이 되는 IR은 모호성, 알고리즘 편향, 확장성 등 다양한 과제를 해결하며, 미래에는 생성형...
FlowHunt를 Azure Wiki Search와 통합하여 AI 기반 색인화, 시맨틱 검색, 그리고 엔터프라이즈 위키 전반에 걸친 즉각적인 지식 검색을 활용하세요. 지식 관리 프로세스를 간소화하고, 생산성을 높이며, 팀이 빠르고 맥락에 맞는 답변을 얻을 수 있도록 지원합니다....
FlowHunt를 바이두 AI 검색과 통합하여 대형 언어 모델이 구동하는 지능형 실시간 웹 검색을 구현하세요. 맞춤형 페르소나 설정, 모델 선택, 쿼리 리라이팅, 타겟 검색 등 고급 AI 기능을 활용하여 업계 특화 워크플로우 및 최적화된 고객 경험을 제공합니다....