Sitemap에서 LLM.txt로 변환하는 AI 컨버터
웹사이트의 sitemap.xml을 LLM에 최적화된 문서 형식으로 자동 변환하세요. 이 AI 기반 컨버터는 웹 콘텐츠를 추출, 처리, 구조화하여 AI 학습 및 LLM 애플리케이션에 적합한 표준화된 llms.txt 형식으로 전환합니다....
2 분 읽기
AI
Documentation
+4
llms.txt는 웹사이트 콘텐츠를 LLM에 맞게 단순화하여, 구조화되고 기계가 읽을 수 있는 인덱스를 제공함으로써 AI 기반 상호작용을 향상시킵니다.
llms.txt 파일은 대규모 언어 모델(LLM)이 웹사이트에서 정보를 접근, 이해, 처리하는 방식을 개선하기 위해 고안된 표준화된 마크다운 형식의 텍스트 파일입니다. 웹사이트의 루트 경로(예: /llms.txt)에 위치하며, 이 파일은 추론 중 기계가 읽고 이해할 수 있도록 구조화되고 요약된 콘텐츠를 선별적으로 제공합니다. 그 주된 목적은 내비게이션 메뉴, 광고, 자바스크립트 등 전통적인 HTML 콘텐츠의 복잡성을 피하고, 명확하고 인간 및 기계 모두가 읽을 수 있는 데이터를 제공하는 데 있습니다.
robots.txt나 sitemap.xml과 같은 기존 웹 표준과 달리, llms.txt는 검색 엔진이 아닌 ChatGPT, Claude, Google Gemini와 같은 추론 엔진을 위해 특별히 설계되었습니다. 이 파일은 AI 시스템이 컨텍스트 윈도우 내에서 가장 관련성 높고 가치 있는 정보만을 효율적으로 추출하도록 돕습니다. 대부분의 LLM 컨텍스트 윈도우는 전체 웹사이트 콘텐츠를 모두 처리하기엔 너무 작기 때문입니다.
이 개념은 Answer.AI의 공동 창립자인 Jeremy Howard가 2024년 9월에 제안했습니다. 이는 LLM이 복잡한 웹사이트와 상호작용할 때 마주치는 비효율성을 해결하기 위한 해결책으로 등장했습니다. 기존 HTML 페이지를 처리하는 방식은 종종 연산 자원의 낭비와 콘텐츠 오해로 이어집니다. llms.txt와 같은 표준을 도입함으로써 웹사이트 소유자는 AI 시스템이 자신의 콘텐츠를 정확하고 효과적으로 파싱하도록 할 수 있습니다.
llms.txt 파일은 주로 인공지능 및 LLM 기반 상호작용 분야에서 여러 실용적인 목적을 수행합니다. 구조화된 형식을 통해 LLM이 웹사이트 콘텐츠를 효율적으로 검색·처리할 수 있게 하며, 컨텍스트 윈도우 크기 및 처리 효율성의 한계를 극복합니다.
llms.txt 파일은 사람과 기계 모두에 호환되도록 특정 마크다운 기반 스키마를 따릅니다. 구조는 다음과 같습니다:
예시:
# 예시 웹사이트
> 인공지능에 관한 지식과 리소스를 공유하는 플랫폼입니다.
## 문서
- [빠른 시작 가이드](https://example.com/docs/quickstart.md): 초보자를 위한 시작 안내서
- [API 참고서](https://example.com/docs/api.md): 자세한 API 문서
## 정책
- [이용 약관](https://example.com/terms.md): 플랫폼 이용을 위한 법적 안내
- [개인정보처리방침](https://example.com/privacy.md): 데이터 처리 및 사용자 개인정보 안내
## Optional
- [회사 연혁](https://example.com/history.md): 주요 이정표와 성과 연대기
llms.txt로 AI 시스템이 상품 분류, 환불 정책, 사이즈 가이드 등에 접근하도록 할 수 있습니다.FastHTML은 서버 렌더링 웹 애플리케이션을 위한 파이썬 라이브러리로, 문서 접근을 단순화하기 위해 llms.txt를 사용합니다. 이 파일에는 빠른 시작 가이드, HTMX 참고서, 예제 애플리케이션 등 개발자가 특정 리소스를 신속하게 찾을 수 있도록 링크가 포함되어 있습니다.
예시 코드:
# FastHTML
> 서버 렌더링 하이퍼미디어 애플리케이션 생성을 위한 파이썬 라이브러리입니다.
## Docs
- [빠른 시작](https://fastht.ml/docs/quickstart.md): 핵심 기능 개요
- [HTMX 참고서](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): HTMX 속성과 메서드 전체 안내
나이키와 같은 전자상거래 대기업은 llms.txt 파일을 활용해 AI 시스템에 상품 라인, 지속 가능성 이니셔티브, 고객 지원 정책 등에 관한 정보를 제공할 수 있습니다.
예시 코드:
# Nike
> 지속 가능성과 혁신을 강조하는 글로벌 스포츠 의류 및 신발 리더입니다.
## 상품 라인
- [러닝화](https://nike.com/products/running.md): React 폼, Vaporweave 기술 등 상세 설명
- [지속 가능성 이니셔티브](https://nike.com/sustainability.md): 2025년 목표 및 친환경 소재 안내
## 고객 지원
- [환불 정책](https://nike.com/returns.md): 60일 환불 기준 및 예외 사항
- [사이즈 가이드](https://nike.com/sizing.md): 신발 및 의류 사이즈 차트
세 표준 모두 자동화 시스템을 지원하기 위해 고안되었으나, 목적과 대상이 다릅니다.
llms.txt:
robots.txt:
sitemap.xml:
robots.txt와 sitemap.xml과 달리, llms.txt는 검색 엔진이 아닌 추론 엔진을 위해 설계됨llms.txt 및 llms-full.txt 자동 생성llms.txt 자동 생성https://example.com/llms.txt)에 위치llms_txt2ctx 등 도구로 검증llms.txt나 llms-full.txt 파일을 직접 업로드 가능llms.txt는 개발자와 소규모 플랫폼에서 인기를 얻고 있지만, OpenAI, Google 등 주요 LLM 제공사에서 공식 지원하지는 않습니다.llms-full.txt가 일부 LLM의 컨텍스트 윈도우 크기를 초과할 수 있음이러한 과제에도 불구하고, llms.txt는 AI 기반 시스템을 위한 콘텐츠 최적화의 미래지향적 접근법을 제시합니다. 이 표준을 도입함으로써 조직은 자신의 콘텐츠가 AI 시대에 접근 가능하고, 정확하며, 우선순위에 맞게 노출될 수 있도록 할 수 있습니다.
연구: 대규모 언어 모델(LLM)
대규모 언어 모델(LLM)은 챗봇, 콘텐츠 검열, 검색 엔진 등 자연어 처리 분야에서 핵심 기술로 자리잡았습니다. Nicholas와 Bhatia(2023)의 “Lost in Translation: 대규모 언어 모델의 비영어권 콘텐츠 분석"에서는 LLM의 작동 원리를 명확히 설명하고, 영어와 기타 언어 간 데이터 접근성 격차와 다국어 모델을 통한 격차 해소 노력을 다룹니다. 논문은 LLM을 활용한 콘텐츠 분석의 도전 과제(특히 다국어 환경에서)를 상세히 설명하고, 연구자·기업·정책 입안자에게 LLM의 개발 및 적용 관련 권고사항을 제시합니다. 저자들은 그간 진전에도 불구하고 비영어권 언어에서 여전히 상당한 한계가 존재함을 강조합니다. 논문 읽기
Müller와 Laurent(2022)의 “Cedille: 프랑스어 특화 대규모 오토리그레시브 언어 모델"은 Cedille이라는 대규모 프랑스어 전용 언어 모델을 소개합니다. Cedille은 오픈소스로, 기존 모델과 비교해 프랑스어 제로샷 벤치마크에서 더 우수한 성능을 보여주며, 몇몇 작업에서는 GPT-3에 필적합니다. 또한 데이터셋 필터링을 통한 독성 감소 등 안전성 평가 결과도 제공합니다. 이 연구는 특정 언어에 최적화된 LLM 개발의 중요성과 효과를 강조합니다. 논문 읽기
Ojo와 Ogueji(2023)의 “상업용 대규모 언어 모델은 아프리카 언어에서 얼마나 좋은가?” 논문은 상업용 LLM의 아프리카 언어 번역·분류 성능을 평가합니다. 결과에 따르면, 이 모델들은 아프리카 언어에서 전반적으로 낮은 성능을 보이며, 번역보다는 분류에서 더 나은 결과를 냅니다. 논문은 다양한 아프리카 언어에 대한 평가를 수행하며, 상업적 LLM에 더 많은 아프리카 언어 지원이 필요함을 지적합니다. 이 연구는 현재의 한계와 더 포괄적인 언어 모델 개발의 필요성을 조명합니다. 논문 읽기
Chang 등(2024)의 “Goldfish: 350개 언어를 위한 단일언어 언어 모델"은 저자원 언어에 대한 단일언어와 다언어 모델의 성능을 비교합니다. 연구 결과, 대형 다국어 모델은 많은 언어에서 단순 바이그램 모델보다도 낮은 성능을 보였으며, Goldfish는 350개 언어에 대해 단일언어로 학습되어 저자원 언어에서 성능을 크게 향상시켰습니다. 저자들은 저대표 언어에 대한 맞춤형 모델 개발의 필요성을 강조합니다. 이 연구는 현재 다국어 LLM의 한계와 단일언어 모델의 가능성을 보여줍니다. 논문 읽기
llms.txt는 웹사이트의 루트(e.g., /llms.txt)에 위치하는 표준화된 마크다운 파일로, 대규모 언어 모델에 최적화된 콘텐츠 인덱스를 제공하여 효율적인 AI 기반 상호작용을 가능하게 합니다.
robots.txt(검색 엔진 크롤링용)나 sitemap.xml(인덱싱용)과 달리, llms.txt는 LLM을 위해 설계되어, AI 추론을 위한 고가치 콘텐츠를 우선시하는 단순화된 마크다운 기반 구조를 제공합니다.
웹사이트 제목(H1 헤더), 블록 인용 요약, 추가 맥락을 위한 상세 섹션, 링크와 설명이 포함된 H2로 구분된 리소스 목록, 그리고 선택적 보조 리소스 섹션 등으로 구성되어 있습니다.
llms.txt는 2024년 9월 Answer.AI의 공동 창립자인 Jeremy Howard에 의해, LLM이 복잡한 웹사이트 콘텐츠를 처리할 때의 비효율성을 해결하기 위해 제안되었습니다.
llms.txt는 광고나 자바스크립트와 같은 노이즈를 줄이고, 컨텍스트 윈도우에 맞게 콘텐츠를 최적화하며, 기술 문서나 전자상거래 등 다양한 응용 분야에서 정확한 파싱을 가능하게 합니다.
마크다운으로 직접 작성하거나 Mintlify, Firecrawl과 같은 도구로 생성할 수 있습니다. llms_txt2ctx와 같은 검증 도구로 표준 준수 여부를 확인할 수 있습니다.
FlowHunt와 함께 llms.txt를 구현하여 귀하의 콘텐츠를 AI에 최적화하고 대규모 언어 모델과의 상호작용을 개선하는 방법을 알아보세요.
웹사이트의 sitemap.xml을 LLM에 최적화된 문서 형식으로 자동 변환하세요. 이 AI 기반 컨버터는 웹 콘텐츠를 추출, 처리, 구조화하여 AI 학습 및 LLM 애플리케이션에 적합한 표준화된 llms.txt 형식으로 전환합니다....
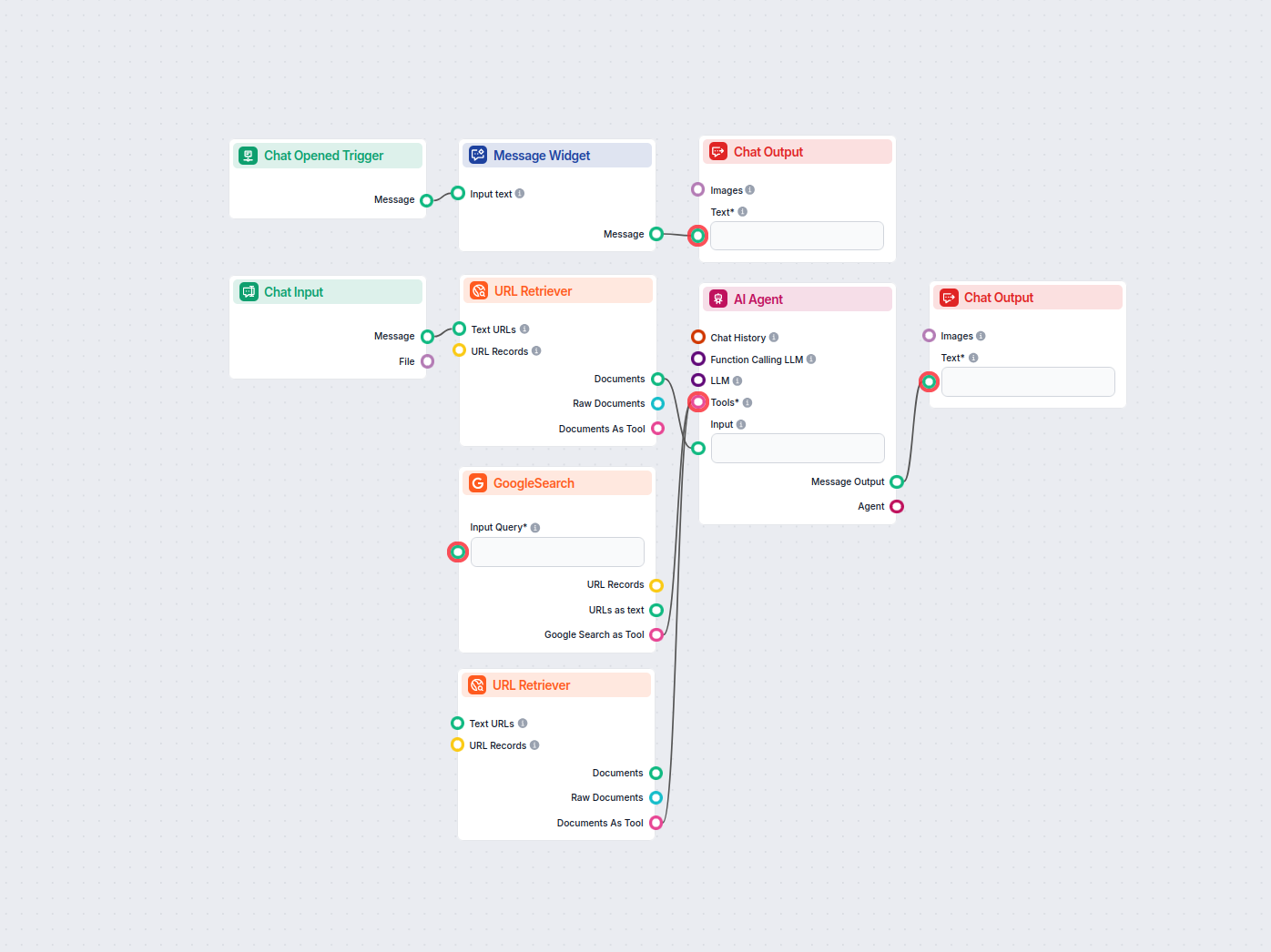
AI를 활용하여 sitemap.xml을 잘 구조화된 llms.txt 형식으로 변환하세요. 이 워크플로우는 sitemap에서 URL을 가져오고, 해당 콘텐츠를 수집 및 처리하며, AI 에이전트를 통해 AI 학습이나 지식 수집에 적합한 최적화된 llms.txt 파일을 생성합니다....
텍스트 요약은 방대한 문서를 간결한 요약으로 정제하여 핵심 정보와 의미를 보존하는 필수적인 AI 프로세스입니다. GPT-4, BERT와 같은 대형 언어 모델을 활용해 추상적, 추출적, 혼합적 방법을 통해 방대한 디지털 콘텐츠를 효율적으로 관리하고 이해할 수 있습니다....