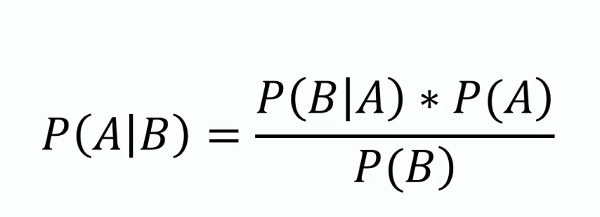
베이즈 네트워크
베이즈 네트워크(BN)는 변수와 그들의 조건부 의존성을 방향성 비순환 그래프(DAG)를 통해 표현하는 확률 그래프 모델입니다. 베이즈 네트워크는 불확실성을 모델링하고 추론 및 학습을 지원하며, 의료, AI, 금융 등 다양한 분야에서 널리 사용됩니다....
3 분 읽기
Bayesian Networks
AI
+3
나이브 베이즈는 베이즈 정리를 활용하는 간단하면서도 강력한 분류 알고리즘 군으로, 스팸 탐지와 텍스트 분류와 같은 확장 가능한 작업에 널리 사용됩니다.
나이브 베이즈는 베이즈 정리에 기반하여 특성 간 조건부 독립성을 가정하는 간단하고 효과적인 분류 알고리즘 군입니다. 단순함과 확장성 덕분에 스팸 탐지, 텍스트 분류 등 다양한 분야에서 널리 활용됩니다.
나이브 베이즈는 베이즈 정리에 기반한 분류 알고리즘의 한 종류로, 조건부 확률의 원리를 적용합니다. “나이브(naive)”라는 용어는 데이터셋 내 모든 특성이 클래스 레이블이 주어졌을 때 서로 조건부로 독립적이라는 단순화된 가정을 의미합니다. 이 가정은 실제 데이터에서는 자주 위배됨에도 불구하고, 나이브 베이즈 분류기는 텍스트 분류, 스팸 탐지 등 다양한 분야에서 그 단순함과 효과성으로 잘 알려져 있습니다.
베이즈 정리
이 정리는 나이브 베이즈의 기초가 되며, 새로운 증거나 정보가 주어졌을 때 가설의 확률 추정치를 갱신하는 방법을 제공합니다. 수식으로는 다음과 같이 표현됩니다:
여기서 ( P(A|B) )는 사후 확률, ( P(B|A) )는 우도, ( P(A) )는 사전 확률, ( P(B) )는 증거입니다.
조건부 독립성
각 특성이 클래스 레이블이 주어졌을 때 서로 독립적이라는 단순화 가정입니다. 이 가정 덕분에 계산이 단순해지고, 대용량 데이터셋에서도 알고리즘이 잘 확장됩니다.
사후 확률
베이즈 정리를 이용해 특성 값이 주어졌을 때 클래스 레이블의 확률을 계산합니다. 이는 나이브 베이즈 예측의 핵심 요소입니다.
나이브 베이즈 분류기의 유형
나이브 베이즈 분류기는 각 클래스에 대해 주어진 특성 집합을 바탕으로 사후 확률을 계산하고, 가장 높은 사후 확률을 가진 클래스를 선택합니다. 과정은 다음과 같습니다:
나이브 베이즈 분류기는 아래와 같은 분야에서 특히 효과적입니다:
나이브 베이즈를 활용한 스팸 필터링을 예로 들어보겠습니다. 학습 데이터는 “스팸” 혹은 “스팸 아님”으로 라벨링된 이메일로 구성되어 있습니다. 각 이메일은 특정 단어의 존재 유무 등 여러 특성으로 표현됩니다. 학습 단계에서 알고리즘은 각 클래스별 특정 단어의 확률을 계산합니다. 새로운 이메일이 들어오면 “스팸”과 “스팸 아님” 각각의 사후 확률을 계산하고, 더 높은 확률을 가진 클래스로 분류합니다.
나이브 베이즈 분류기는 AI 시스템과 챗봇에 통합되어 자연어 처리 기능을 강화함으로써 인간-컴퓨터 상호작용의 다리를 놓아줍니다. 예를 들어, 사용자 질문의 의도를 감지하거나, 텍스트를 미리 정의된 카테고리로 분류하거나, 부적절한 콘텐츠를 필터링하는 데 사용할 수 있습니다. 이러한 기능은 AI 기반 솔루션의 상호작용 품질과 적합성을 높이며, 알고리즘의 효율성 덕분에 실시간 응용에도 적합해 AI 자동화 및 챗봇 시스템에서 중요한 역할을 합니다.
나이브 베이즈는 특성 간 강한 독립성 가정을 가진 베이즈 정리를 적용한 간단하면서도 강력한 확률적 알고리즘 군입니다. 단순성과 효과성 덕분에 분류 작업에 널리 사용됩니다. 다음은 나이브 베이즈 분류기의 다양한 응용 및 개선을 다룬 논문들입니다:
나이브 베이즈와 간단한 k-최근접 이웃 탐색을 결합한 스팸 필터링 개선
저자: Daniel Etzold
발행일: 2003년 11월 30일
이 논문은 이메일 분류를 위한 나이브 베이즈의 사용에 대해 다루며, 그 구현의 용이성과 효율성을 강조합니다. 연구에서는 나이브 베이즈와 k-최근접 이웃 탐색을 결합함으로써 스팸 필터의 정확도를 높일 수 있음을 실험적으로 보여줍니다. 특성 수가 많은 경우 약간의 정확도 향상이 있었고, 특성 수가 적을수록 더 큰 개선 효과가 나타났습니다. 논문 읽기
Locally Weighted Naive Bayes
저자: Eibe Frank, Mark Hall, Bernhard Pfahringer
발행일: 2012년 10월 19일
이 논문은 나이브 베이즈의 주요 약점인 속성 독립성 가정 문제를 해결하고자, 예측 시점에 지역 모델을 학습하는 locally weighted 나이브 베이즈 방법을 제안합니다. 실험 결과, 이 방법은 정확도가 거의 저하되지 않으며 종종 크게 향상됨을 보여줍니다. 개념적·계산적으로도 단순한 방법으로 평가받고 있습니다. 논문 읽기
행성 로버의 함정 탐지를 위한 나이브 베이즈
저자: Dicong Qiu
발행일: 2018년 1월 31일
이 연구에서는 행성 로버의 함정(이동 불가) 상황을 탐지하기 위해 나이브 베이즈 분류기를 적용합니다. 로버 함정의 기준을 정의하고, 나이브 베이즈를 활용한 탐지 실험을 진행하였습니다. AutoKrawler 로버를 활용한 실험을 통해, 자율 구조 절차에 있어 나이브 베이즈의 효과를 확인할 수 있습니다. 논문 읽기
나이브 베이즈는 베이즈 정리에 기반한 분류 알고리즘의 한 종류로, 모든 특성이 클래스 레이블이 주어졌을 때 조건부로 독립적이라고 가정합니다. 텍스트 분류, 스팸 필터링, 감성 분석 등에 널리 사용됩니다.
주요 유형에는 연속형 특성에 사용하는 가우시안 나이브 베이즈, 단어 수와 같은 이산형 특성에 적합한 멀티노미얼 나이브 베이즈, 이진/불리언 특성에 사용하는 베르누이 나이브 베이즈가 있습니다.
나이브 베이즈는 구현이 간단하고 계산 효율성이 높으며 대용량 데이터셋에도 확장성이 뛰어나고, 고차원 데이터도 잘 처리합니다.
가장 큰 한계는 특성 간 독립성 가정이 실제 데이터에서는 잘 성립하지 않는다는 점입니다. 또한, 학습 데이터에서 관찰되지 않은 특성에 대해 0의 확률을 할당할 수 있는데, 이는 라플라스 스무딩과 같은 기법으로 완화할 수 있습니다.
나이브 베이즈는 AI 시스템과 챗봇에서 의도 감지, 텍스트 분류, 스팸 필터링, 감성 분석 등에 사용되어 자연어 처리 능력을 강화하고 실시간 의사결정을 가능하게 합니다.
베이즈 네트워크(BN)는 변수와 그들의 조건부 의존성을 방향성 비순환 그래프(DAG)를 통해 표현하는 확률 그래프 모델입니다. 베이즈 네트워크는 불확실성을 모델링하고 추론 및 학습을 지원하며, 의료, AI, 금융 등 다양한 분야에서 널리 사용됩니다....
부스팅은 여러 개의 약한 학습자의 예측을 결합하여 강한 학습자를 만드는 머신러닝 기법으로, 정확도를 향상시키고 복잡한 데이터를 처리합니다. 주요 알고리즘, 장점, 도전 과제, 실제 적용 사례를 알아보세요....
멀티홉 추론은 AI, 특히 자연어 처리(NLP)와 지식 그래프 분야에서 시스템이 복잡한 질문에 답하거나 결정을 내리기 위해 여러 정보를 연결하는 과정입니다. 이는 데이터 소스 간의 논리적 연결을 가능하게 하여, 고급 질문 응답, 지식 그래프 완성, 그리고 더욱 똑똑한 챗봇을 지원합니다....