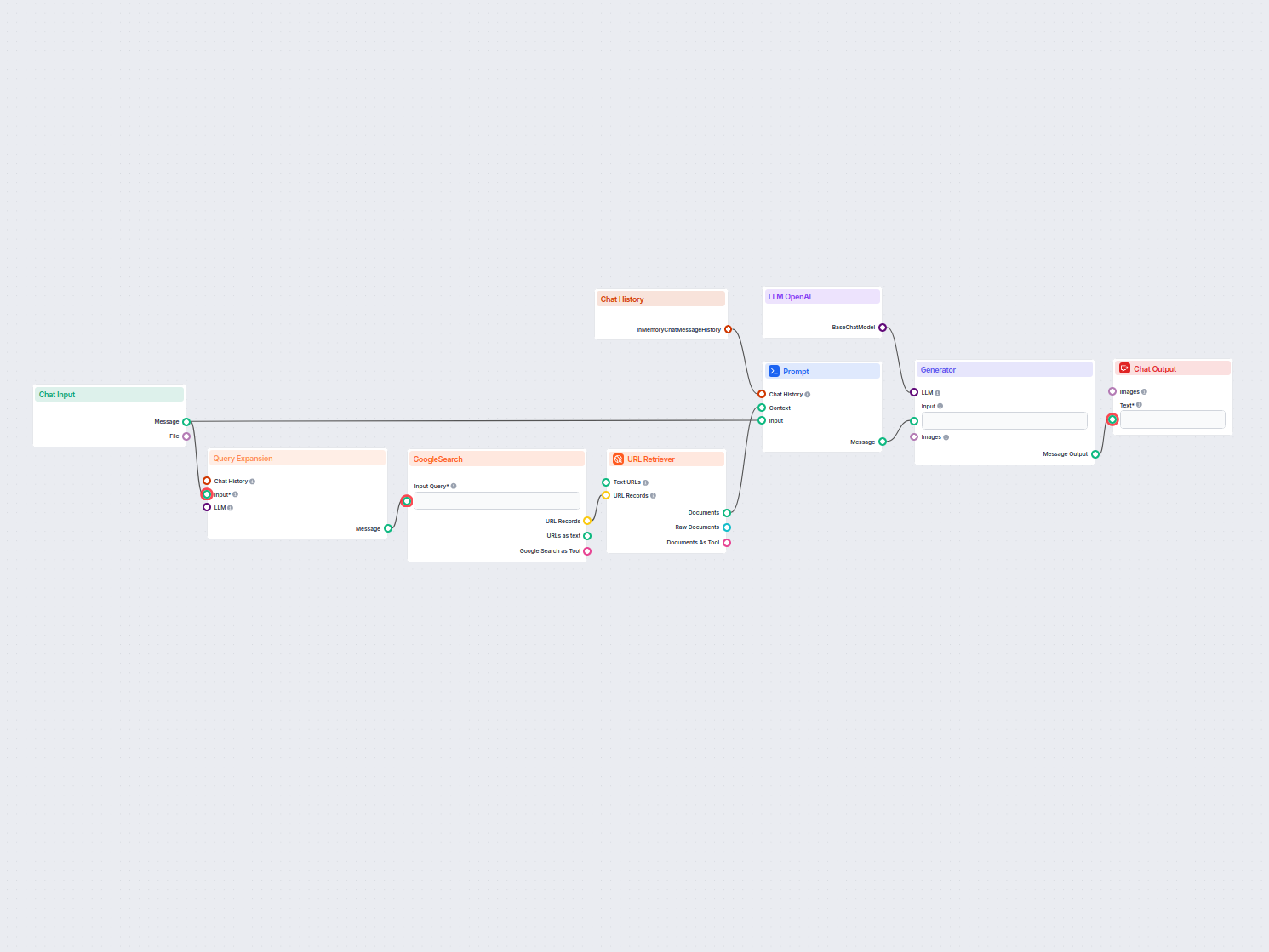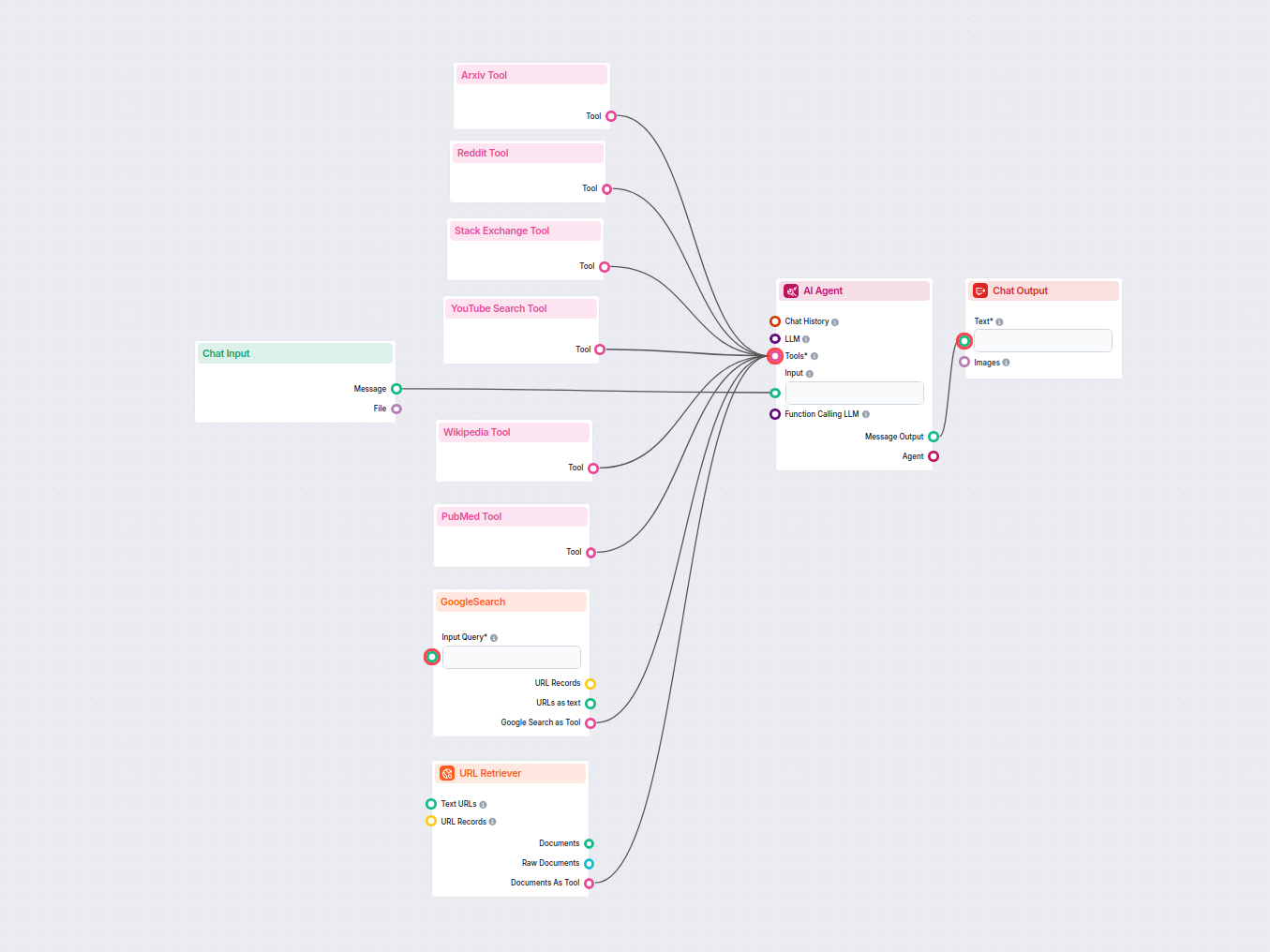
실시간 웹 및 지식 검색이 가능한 AI 챗봇
Google, Reddit, Wikipedia, Arxiv, Stack Exchange, YouTube, PubMed, 웹사이트 URL 등에서 정보를 검색·종합하여, 사용자 질문에 실시간으로 답변하고 출처를 명시하는 강력한 AI 챗봇입니다. 연구, 학습, 일반 질의응답에 출처 기반 답변...
3 분 읽기
챗봇의 검색 파이프라인은 사용자의 질문에 맞는 관련 정보를 가져오고 처리 및 검색할 수 있게 해주는 기술적 아키텍처와 프로세스를 의미합니다. 사전 학습된 언어 모델에만 의존하는 단순 질의응답 시스템과 달리, 검색 파이프라인은 외부 지식 베이스나 데이터 소스를 통합합니다. 이를 통해 챗봇은 언어 모델 자체에 내재되어 있지 않은 데이터까지도 정확하고, 맥락에 맞으며, 최신의 응답을 제공할 수 있습니다.
검색 파이프라인은 일반적으로 데이터 수집, 임베딩 생성, 벡터 저장, 맥락 검색, 응답 생성 등 여러 구성 요소로 이루어집니다. 구현 시에는 검색 기반 생성(RAG) 기법을 자주 활용하며, 이는 데이터 검색 시스템과 **대형 언어 모델(LLM)**의 강점을 결합하여 응답을 생성합니다.
검색 파이프라인은 챗봇의 역량을 다음과 같이 강화합니다.
문서 수집
PDF, 텍스트 파일, 데이터베이스, API 등 다양한 원시 데이터를 수집하고 전처리합니다. LangChain이나 LlamaIndex와 같은 도구가 원활한 데이터 수집에 자주 사용됩니다.
예시: 고객센터 FAQ나 제품 사양서를 시스템에 로딩하기.
문서 전처리
긴 문서를 의미 단위로 잘게 분할합니다. 이는 보통 토큰 한도(예: 512토큰)가 있는 임베딩 모델에 입력하기 위해 필요합니다.
예시 코드 스니펫:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
임베딩 생성
텍스트 데이터를 임베딩 모델을 통해 고차원 벡터로 변환합니다. 임베딩은 데이터의 의미를 수치적으로 표현합니다.
예시 임베딩 모델: OpenAI의 text-embedding-ada-002 또는 Hugging Face의 e5-large-v2.
벡터 저장
임베딩을 벡터 데이터베이스에 저장하여 유사도 검색에 최적화합니다. Milvus, Chroma, PGVector 등이 대표적인 도구입니다.
예시: 상품 설명과 임베딩을 저장하여 빠른 검색 지원.
쿼리 처리
사용자 질문을 동일한 임베딩 모델로 벡터화하여 저장된 임베딩과 의미적으로 유사한 것을 찾습니다.
예시 코드 스니펫:
query_vector = embedding_model.encode("Product X의 사양은 무엇인가요?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
데이터 검색
유사도 점수(예: 코사인 유사도)를 기반으로 가장 관련성 높은 데이터 조각을 검색합니다. SQL 데이터베이스, 지식 그래프, 벡터 검색을 결합한 멀티모달 검색도 가능합니다.
응답 생성
검색된 데이터와 사용자 질문을 결합하여 대형 언어 모델(LLM)에 입력, 최종 자연어 응답을 생성합니다. 이 단계를 증강 생성이라 부르기도 합니다.
예시 프롬프트 템플릿:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
사후 처리 및 검증
고급 파이프라인에서는 환각 탐지, 적합성 검사, 응답 평가 등을 통해 결과의 사실성과 적합성을 보장합니다.
고객 지원
챗봇이 제품 매뉴얼, 문제 해결 가이드, FAQ를 검색하여 고객 문의에 즉시 답변할 수 있습니다.
예시: 사용 설명서의 관련 부분을 찾아 라우터 초기화 방법 안내.
기업 지식 관리
사내 챗봇이 HR 정책, IT 지원 문서, 컴플라이언스 가이드 등 기업별 데이터를 검색합니다.
예시: 직원이 챗봇에 병가 정책 문의.
전자상거래
챗봇이 제품 상세, 리뷰, 재고 현황 등 정보를 검색하여 사용자에게 제공합니다.
예시: “Product Y의 주요 기능은 무엇인가요?”
헬스케어
챗봇이 의학 논문, 가이드라인, 환자 데이터를 검색해 전문가 및 환자의 의사결정을 지원합니다.
예시: 의약품 상호작용 경고를 제약사 데이터베이스에서 검색.
교육 및 연구
학술 챗봇이 RAG 파이프라인을 활용해 논문 검색, 질의응답, 연구 요약을 지원합니다.
예시: “2023년 기후변화 연구 결과 요약해줘.”
법률 및 컴플라이언스
챗봇이 법률 문서, 판례, 규정 요구사항을 검색해 법률 전문가를 지원합니다.
예시: “GDPR 최신 업데이트가 무엇인가요?”
기업 연간 재무보고서(PDF)에서 질문에 답하는 챗봇.
SQL, 벡터 검색, 지식 그래프를 조합하여 직원 질문에 답하는 챗봇.
검색 파이프라인을 활용하면 챗봇은 정적 학습 데이터의 한계를 뛰어넘어 역동적이고, 정밀하며, 맥락이 풍부한 상호작용을 제공합니다.
검색 파이프라인은 지능적이고 맥락 인지형 챗봇 시스템의 핵심 역할을 합니다.
Pengfei Zhu 외, “Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” (2018)
Lingke라는 챗봇은 정보 검색을 통합해 다중 대화 턴을 처리합니다. 세분화된 파이프라인 처리로 비정형 문서에서 응답을 도출하고, 주의 기반 맥락-응답 매칭으로 복잡한 질의에도 효과적으로 답변합니다.
논문 보기
Rama Akkiraju 외, “FACTS About Building Retrieval Augmented Generation-based Chatbots” (2024)
RAG 파이프라인과 LLM을 활용한 엔터프라이즈 챗봇 개발의 과제와 방법론을 탐구합니다. Freshness, Architectures, Cost, Testing, Security(FACTS) 프레임워크를 제안하며, LLM 확장 시 정확성과 지연 간 트레이드오프 등 실증적 분석을 제공합니다.
Subash Neupane 외, “From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” (2024)
대학 환경을 위한 BARKPLUG V.2 챗봇 시스템을 소개합니다. RAG 파이프라인을 활용해 캠퍼스 자원에 대한 도메인 특화 답변을 제공하며, RAG Assessment(RAGAS) 등 프레임워크로 그 성능을 평가합니다.
검색 파이프라인은 챗봇이 외부 소스에서 관련 정보를 가져오고 처리 및 검색할 수 있게 해주는 기술적 아키텍처입니다. 데이터 수집, 임베딩, 벡터 저장, LLM 응답 생성을 결합하여 동적이고 맥락을 인지한 답변을 제공합니다.
RAG는 데이터 검색 시스템과 대형 언어 모델(LLM)의 강점을 결합하여 챗봇이 최신 외부 데이터에 기반한 사실적인 응답을 제공하게 하여 환각을 줄이고 정확도를 높입니다.
주요 구성 요소에는 문서 수집, 전처리, 임베딩 생성, 벡터 저장, 쿼리 처리, 데이터 검색, 응답 생성, 사후 처리 및 검증이 포함됩니다.
활용 사례에는 고객 지원, 기업 지식 관리, 전자상거래 상품 정보, 헬스케어 안내, 교육 및 연구, 법률 및 컴플라이언스 지원 등이 있습니다.
실시간 검색으로 인한 지연, 운영 비용, 데이터 프라이버시 문제, 대용량 데이터 처리를 위한 확장성 요구 사항 등이 주요 과제입니다.
Google, Reddit, Wikipedia, Arxiv, Stack Exchange, YouTube, PubMed, 웹사이트 URL 등에서 정보를 검색·종합하여, 사용자 질문에 실시간으로 답변하고 출처를 명시하는 강력한 AI 챗봇입니다. 연구, 학습, 일반 질의응답에 출처 기반 답변...
Google 검색을 자신의 도메인으로 제한하여 관련 웹 콘텐츠를 실시간으로 가져오고, OpenAI LLM을 활용해 사용자 질문에 최신 정보를 바탕으로 답변하는 챗봇입니다. 고객 지원이나 정보 포털 등에서 정확하고 도메인 특화된 답변을 제공하는 데 이상적입니다....
챗봇은 AI와 자연어 처리를 활용해 인간과의 대화를 모방하는 디지털 도구로, 24시간 지원, 확장성, 비용 효율성을 제공합니다. 챗봇의 작동 방식, 유형, 이점, 그리고 FlowHunt와 함께하는 실제 적용 사례를 알아보세요....