문서
챗봇이 문서, HTML 페이지, 심지어 YouTube 동영상까지 즉시 접근하고 활용하여 맞춤형 컨텍스트를 제공합니다. 공개적으로 게시하고 싶지 않지만 챗봇이 접근하길 원하는 정보를 추가할 때 완벽한 기능입니다....
2 분 읽기
AI Chatbot
Knowledge Management
+3
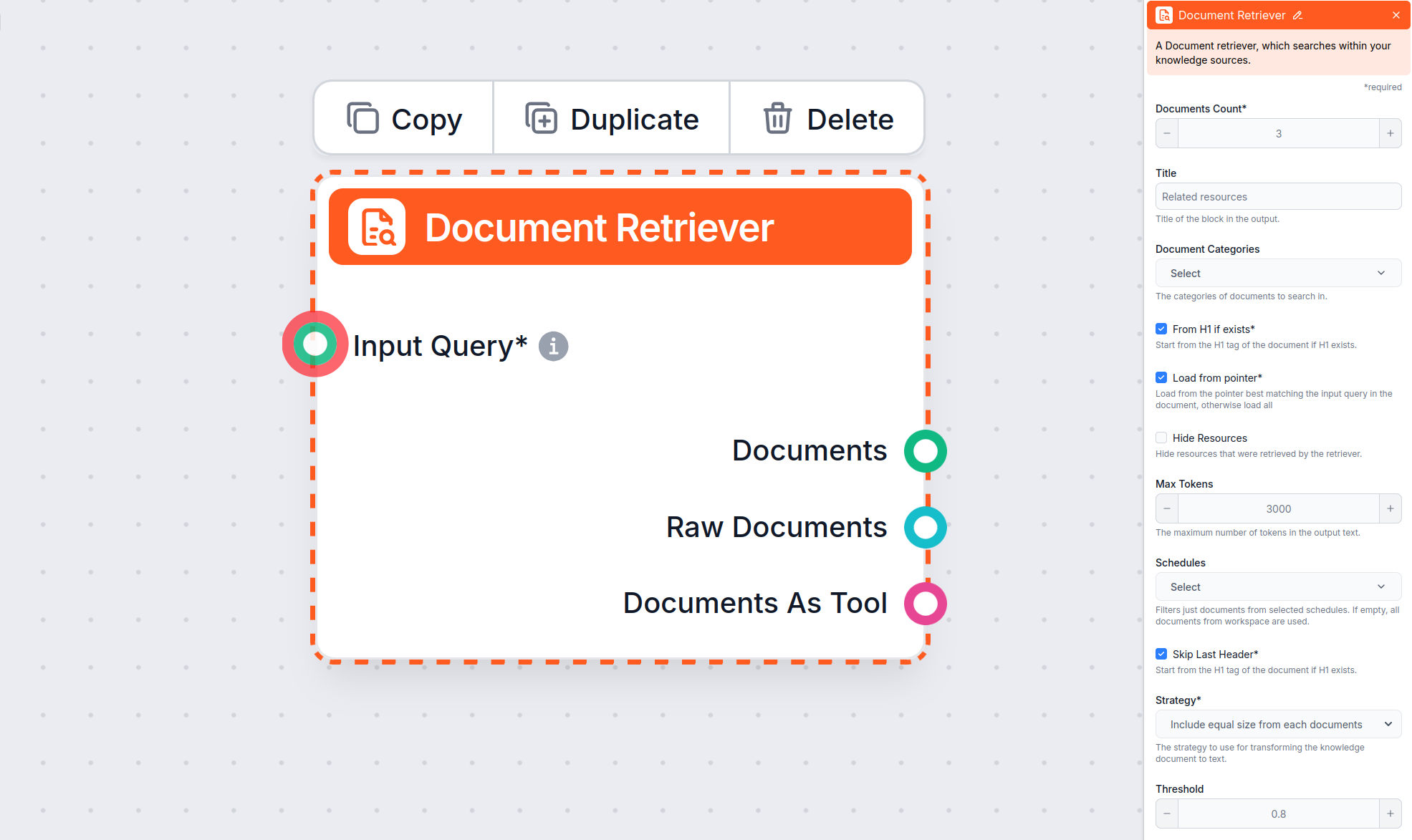
‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’ 매개변수 설정 방법을 알아보세요.
Document Retriever 컴포넌트 는 챗봇이 Documents와 Schedules에서 지정한 소스에서 지식을 검색할 수 있도록 해줍니다. 이 컴포넌트의 역할은 검색을 제어하는 것이며, 여러 매개변수가 해당 문서에서 정보를 어떻게 검색할지에 영향을 줍니다.
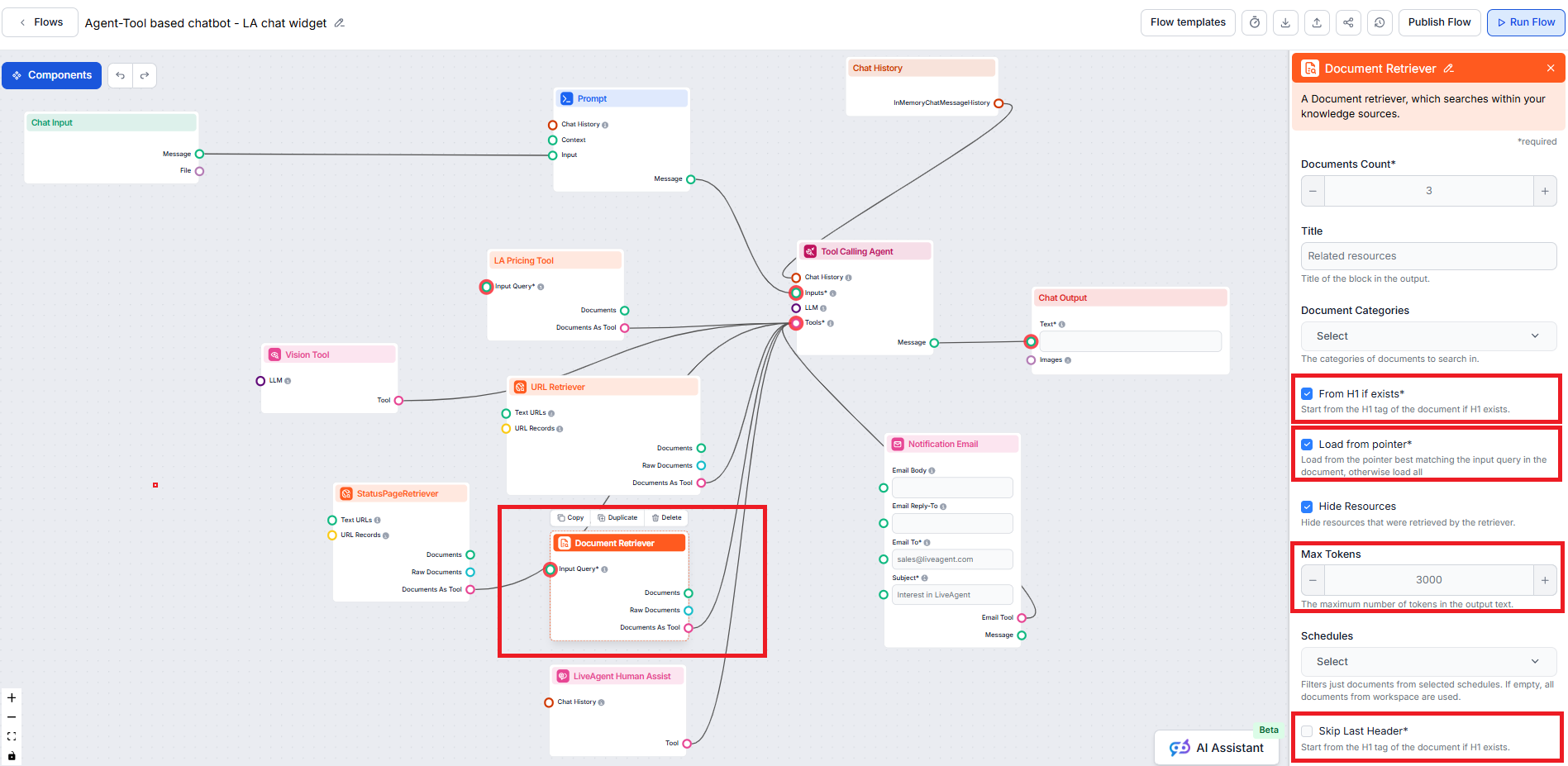
From H1 if exists 옵션은 리트리버가 발견한 H1 헤더(일반적으로 글의 메인 제목)부터 콘텐츠 추출을 시작하도록 지시합니다.
어떻게 동작하나요?
사용 예시:
사이트의 네비게이션이나 페이지 헤더 등 불필요한 부분 없이 실제 가이드 본문만 가져오고 싶을 때 사용합니다.
참고:
From H1 if exists 옵션은 기본적으로 Document Retriever 컴포넌트에서 활성화되어 있습니다.
Load from pointer 옵션은 긴 글에서 포인터가 지정된 위치부터 데이터 로드를 허용하여 더 정밀하게 제어할 수 있습니다.
어떻게 동작하나요?
“포인터"란 무엇인가요?
포인터는 문서 내에 있는 고유 문자열이나 헤딩(예: H2, 특정 문구, 섹션 제목 등)입니다.
사용 예시:
서론 등 불필요한 부분은 건너뛰고, 긴 문서에서 특정 섹션(예: “4단계: 라이브 채팅 버튼 추가”)부터 정보를 추출하고 싶을 때 사용합니다.
Skip Last Header 옵션은 문서의 마지막 헤더(자주 반복되거나 네비게이션, 푸터 용도로 사용)를 무시할 수 있게 해줍니다.
어떻게 동작하나요?
사용 예시:
Document Retriever가 도움말 페이지 끝의 “다른 글” 등 푸터 네비게이션 헤더를 불러오지 않게 하여, 주요 본문만 처리하도록 하고 싶을 때 사용합니다.
참고:
Skip Last Header는 자동 생성 푸터나 반복 네비게이션 요소가 있는 문서에 유용합니다. 하지만 이런 섹션이 없다면, 이 옵션 사용 시 유효한 정보가 누락될 수 있으니 필요할 때만 활성화하는 것이 좋습니다.
Max tokens 매개변수는 Document Retriever가 추출한 텍스트에서 출력할 최대 토큰(단어 및 구두점 등, AI 모델 기준)을 제어할 수 있게 해줍니다.
어떻게 동작하나요?
기본값:
기본값은 일반적으로 3000 토큰이며, 필요에 따라 조정할 수 있습니다.
사용 예시:
긴 문서를 처리할 때, Max tokens 값을 낮게 설정하면 응답이 간결해집니다. 하지만, 최적의 결과를 위해 “Load from pointer” 옵션을 함께 사용하는 것이 좋습니다. 이렇게 하면 원하는 섹션부터 텍스트 추출을 시작할 수 있어, 지정한 토큰 한도 내에서 집중적이고 관리 가능한 정보만 얻을 수 있습니다. 특히 대용량 소스에서 간결하고 맥락에 맞는 출력이 필요할 때 유용합니다.
참고:
정보가 잘려서 누락된다면 Max tokens 값을 늘려보세요. 반대로 더 짧고 집중된 결과가 필요하다면 값을 줄이세요.
최신 팁, 트렌드 및 특가 정보를 무료로 받아보세요.
Document Retriever가 여러 관련 문서를 찾았을 때, Strategy 매개변수는 “Max tokens” 한도를 고려해 챗봇을 위한 단일 텍스트로 어떻게 병합할지 결정합니다.
두 가지 전략 옵션:
각 문서에서 동일한 크기만큼 포함:
토큰 한도가 고르게 나뉩니다. 예를 들어, 3개의 문서와 3,000 토큰 한도라면 각 문서에서 최대 1,000토큰씩 추출됩니다. 모든 소스가 고르게 반영되어 균형 잡힌 답변이 필요한 경우 유용합니다.
문서를 이어붙이되, 첫 문서부터 토큰 한도까지 채움:
관련도 순으로 문서를 추가하여 토큰 한도까지 채웁니다. 가장 관련도가 높은 문서가 우선적으로 채워지며, 공간이 남을 경우 그다음 문서가 추가됩니다. 첫 문서가 길면 전체 한도를 다 사용할 수 있습니다.
선택 기준:
참고:
이 전략들은 검색된 문서를 다음 단계(AI 생성 등)로 넘기기 전 텍스트 구성 방식만 다를 뿐, 어떤 문서를 검색할지는 변경하지 않습니다. 즉, 검색된 문서의 내용을 병합하고 자르는 방식만 달라집니다.
이 글에서는 ‘From H1 if exists’, ‘Load from pointer’, ‘Skip Last Header’, ‘Max tokens’ 매개변수 설정에 중점을 두었지만, Document Retriever는 문서 선택과 검색 방식을 제어하는 추가 매개변수도 제공합니다:
검색할 문서 개수를 제한하여, 결과의 관련성을 높이고 응답 속도를 빠르게 할 수 있습니다.
지식 소스의 Documents 섹션에서 생성한 하나 이상의 카테고리로 검색을 제한할 수 있는 선택적 설정입니다.
챗봇 답변 전 별도의 섹션(리트리버가 가져온 리소스 목록 포함) 표시 여부를 설정할 수 있습니다. LiveAgent와 연동 시에는 반드시 체크해야 하며, 이 섹션은 지원되지 않아 LiveAgent 챗봇 위젯에서 제대로 표시되지 않습니다.
지식 소스에서 크롤링 또는 업데이트 대상으로 지정한 하나 이상의 스케줄로 검색을 제한할 수 있습니다.
검색된 문서가 입력 쿼리와 얼마나 밀접하게 일치해야 하는지(01의 관련성 점수)를 제어합니다. 예를 들어, 0.70.8의 임계값이 높은 관련성의 답변에 권장됩니다. 값이 높을수록 더 정확한 일치, 값이 낮을수록 덜 관련된 문서도 포함될 수 있습니다.
예시:
임계값을 0.6으로 설정하고, 관련성 점수가 0.8, 0.65, 0.5, 0.9인 네 개의 글이 있다면 0.6을 넘는 0.8, 0.65, 0.9만 추출에 사용됩니다.
챗봇의 답변에 분명히 내 문서나 스케줄에 있는 정보가 포함되어 있지 않다면, “Verbose” 옵션으로 대화 기록을 확인하여 Document Retriever 사용 여부 및 어떤 문서가 검색되었는지 상세 로그를 확인하세요. 필요하다면 이 로그를 참고해 설정이나 프롬프트를 조정하세요.
챗봇이 문서, HTML 페이지, 심지어 YouTube 동영상까지 즉시 접근하고 활용하여 맞춤형 컨텍스트를 제공합니다. 공개적으로 게시하고 싶지 않지만 챗봇이 접근하길 원하는 정보를 추가할 때 완벽한 기능입니다....