텍스트 분류
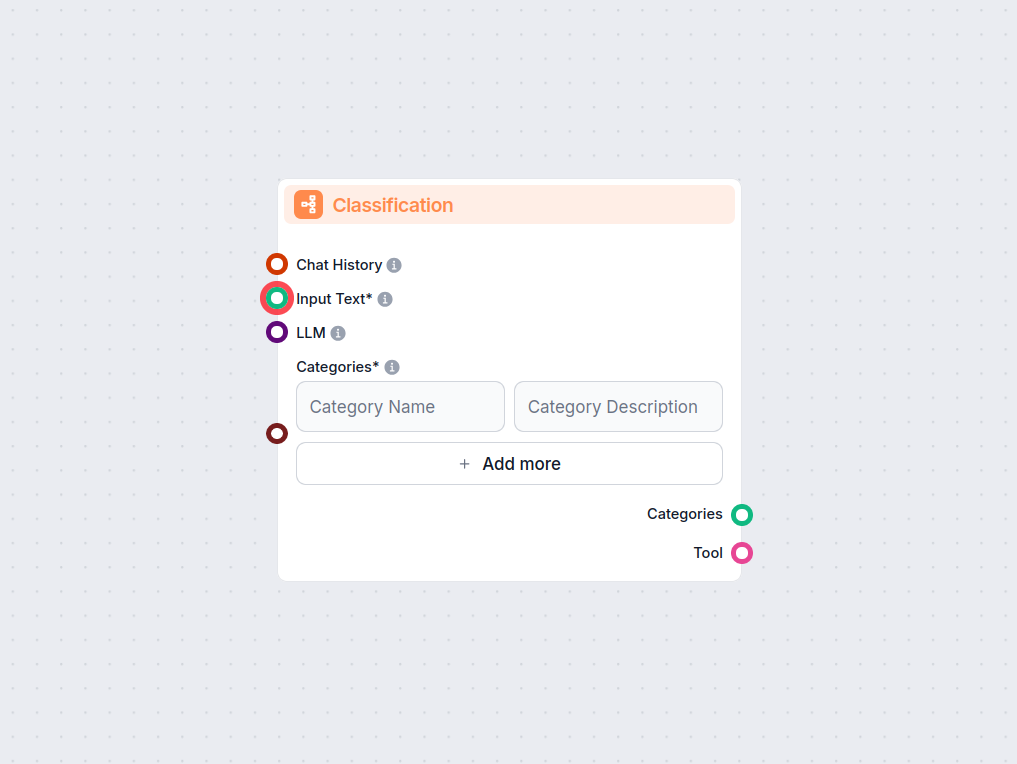
FlowHunt의 텍스트 분류 컴포넌트를 활용하여 워크플로우에서 자동 텍스트 분류를 시작해보세요. AI 모델을 사용해 입력된 텍스트를 사용자가 정의한 카테고리로 손쉽게 분류할 수 있습니다. 챗 기록과 커스텀 설정 지원으로 맥락에 맞는 정확한 분류가 가능해, 라우팅, 태깅, 콘텐츠 모더레...
2 분 읽기
AI
Classification
+3
FlowHunt의 텍스트 분류 컴포넌트를 활용하여 워크플로우에서 자동 텍스트 분류를 시작해보세요. AI 모델을 사용해 입력된 텍스트를 사용자가 정의한 카테고리로 손쉽게 분류할 수 있습니다. 챗 기록과 커스텀 설정 지원으로 맥락에 맞는 정확한 분류가 가능해, 라우팅, 태깅, 콘텐츠 모더레...
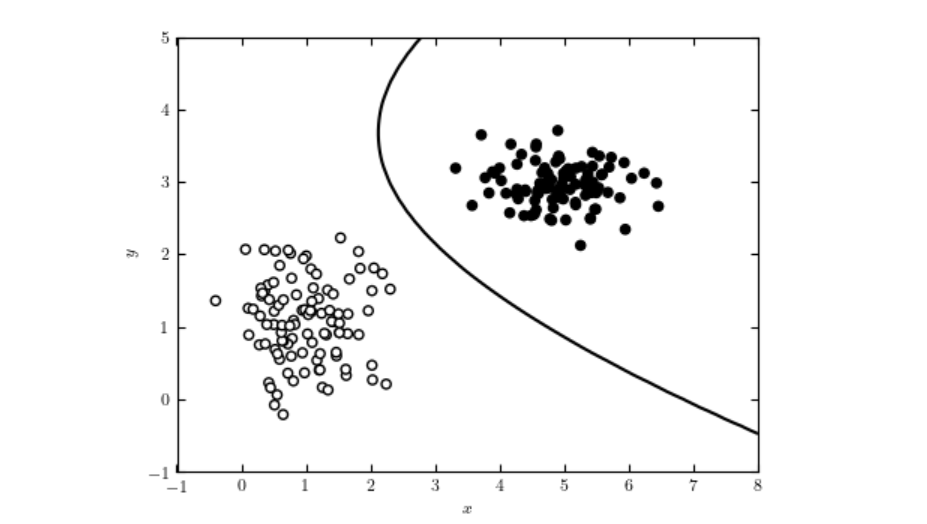
k-최근접 이웃(KNN) 알고리즘은 분류 및 회귀 작업에 사용되는 비모수적, 지도 학습 알고리즘입니다. 'k'개의 가장 가까운 데이터 포인트를 찾아 거리 측정 및 다수결 투표를 활용하여 결과를 예측하며, 단순성과 다양한 적용 가능성으로 잘 알려져 있습니다....
LightGBM(라이트 그라디언트 부스팅 머신)은 마이크로소프트에서 개발한 고급 그라디언트 부스팅 프레임워크입니다. 분류, 순위 매김, 회귀와 같은 고성능 머신러닝 작업을 위해 설계되었으며, 대용량 데이터셋을 효율적으로 처리하면서도 최소한의 메모리로 높은 정확도를 제공합니다....
Top-k 정확도는 머신러닝 평가 지표로, 실제 정답 클래스가 예측된 상위 k개 클래스 내에 포함되어 있는지를 평가하여, 다중 클래스 분류 작업에서 포괄적이고 관대한 측정 기준을 제공합니다....
곡선 아래 면적(AUC)은 머신러닝에서 이진 분류 모델의 성능을 평가하는 데 사용되는 기본적인 지표입니다. 이는 수신자 조작 특성(ROC) 곡선 아래의 면적을 계산하여 모델이 양성 클래스와 음성 클래스를 구분하는 전체적인 능력을 정량화합니다....
그래디언트 부스팅은 회귀와 분류를 위한 강력한 머신러닝 앙상블 기법입니다. 이 방법은 일반적으로 의사결정나무를 사용하여 모델을 순차적으로 구축하며, 예측을 최적화하고 정확성을 높이며 과적합을 방지합니다. 데이터 사이언스 대회와 비즈니스 솔루션에서 널리 활용됩니다....
나이브 베이즈는 조건부 확률을 적용하는 베이즈 정리에 기반한 분류 알고리즘의 한 종류로, 각 특성들이 조건부로 독립적이라는 단순화된 가정을 사용합니다. 이러한 가정에도 불구하고 나이브 베이즈 분류기는 효과적이고 확장성이 뛰어나며, 스팸 탐지나 텍스트 분류와 같은 다양한 응용 분야에 사용...
로그 손실(로그라리즘/크로스 엔트로피 손실)은 머신러닝 모델의 성능을 평가하는 핵심 지표로, 특히 이진 분류에서 예측 확률과 실제 결과의 차이를 측정하여 잘못되거나 과도하게 확신하는 예측에 패널티를 부여합니다....
머신러닝에서의 리콜(Recall)에 대해 알아보세요. 분류 작업에서 모델 성능을 평가하는 데 중요한 이 지표는 양성 인스턴스를 올바르게 식별하는 것이 얼마나 중요한지 설명합니다. 정의, 계산 방법, 중요성, 활용 사례, 개선 전략까지 모두 확인해보세요....
AI 분류기는 기계 학습 알고리즘으로, 입력 데이터를 클래스 레이블에 할당하여 과거 데이터에서 학습한 패턴을 기반으로 정보를 미리 정의된 클래스에 분류합니다. 분류기는 AI 및 데이터 과학의 핵심 도구로, 다양한 산업에서 의사결정을 지원합니다....
식별 AI 모델에 대해 알아보세요—클래스 간의 결정 경계를 모델링함으로써 분류와 회귀에 집중하는 머신러닝 모델입니다. 동작 방식, 장점, 과제, 그리고 NLP, 컴퓨터 비전, AI 자동화에서의 적용 사례를 이해할 수 있습니다....
의사 결정 트리는 분류 및 회귀 작업 모두에 사용되는 강력하고 직관적인 의사 결정 및 예측 분석 도구입니다. 나무 모양의 구조로 해석이 용이하며, 머신러닝, 금융, 의료 등 다양한 분야에서 널리 활용됩니다....
지도 학습은 알고리즘이 레이블이 지정된 데이터를 기반으로 학습하여 새로운, 보지 못한 데이터에 대해 정확한 예측이나 분류를 할 수 있도록 하는 인공지능 및 머신러닝의 기본 개념입니다. 주요 구성 요소, 종류, 그리고 장점에 대해 알아보세요....
지도학습은 기계 학습 및 인공지능의 기본적인 접근 방식으로, 알고리즘이 라벨이 지정된 데이터셋을 통해 예측 또는 분류를 학습합니다. 그 과정, 유형, 주요 알고리즘, 응용 분야, 그리고 과제를 살펴보세요....
크로스 엔트로피는 정보 이론과 머신러닝 모두에서 핵심적인 개념으로, 두 확률 분포 간의 차이를 측정하는 지표입니다. 머신러닝에서는 예측 결과와 실제 레이블 간의 불일치를 정량화하는 손실 함수로 사용되며, 특히 분류 작업에서 모델 성능을 최적화하는 데 중요한 역할을 합니다....
혼동 행렬은 분류 모델의 성능을 평가하는 머신러닝 도구로, 참/거짓 양성 및 음성의 세부 정보를 제공하여 정확도를 넘어선 인사이트를 제공하며, 특히 불균형 데이터셋에서 유용합니다....