arxiv-latex MCP Server
The arxiv-latex MCP Server enables AI tools to directly access and process arXiv papers via their LaTeX source files, allowing for precise mathematical interpre...
4 min read
AI
MCP Server
+5

Connect your AI workflows to arXiv with the arXiv MCP Server. Search, retrieve, and load scholarly articles directly into your LLM-powered research assistants.
FlowHunt provides an additional security layer between your internal systems and AI tools, giving you granular control over which tools are accessible from your MCP servers. MCP servers hosted in our infrastructure can be seamlessly integrated with FlowHunt's chatbot as well as popular AI platforms like ChatGPT, Claude, and various AI editors.
The arXiv MCP Server is a Model Context Protocol (MCP) server designed to enable seamless interaction with the arXiv API using natural language. It acts as a bridge between AI assistants and the arXiv scholarly article repository, allowing developers and AI agents to retrieve article metadata, perform advanced searches, download PDFs, and load article content directly into a large language model’s context. This enhances research workflows by automating information retrieval, document management, and contextual data enrichment for LLMs, making scholarly research more accessible and efficient.
No prompt templates are mentioned in the repository.
Start your free trial today and see results within days.
No explicit MCP resources are listed in the repository.
get_article_url
Retrieves the URL of an article hosted on arXiv.org based on its title.
Parameters: title (String)
download_article
Downloads the article from arXiv.org as a PDF file to the local machine.
Parameters: title (String)
load_article_to_context
Loads the article content into the context of a large language model for further processing.
Parameters: title (String)
get_details
Retrieves metadata of an article from arXiv.org based on its title.
Parameters: title (String)
search_arxiv
Performs a comprehensive search query on the arXiv API and returns matching article metadata.
Parameters:
all_fields (String): General keyword searchtitle (String): Search within titlesauthor (String): Filter by author nameabstract (String): Search within abstractsstart (int): Index of the first result to returnGet latest tips, trends, and deals for free.
mcpServers object:{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
Securing API Keys:
If the server or tools require API keys, store them as environment variables and reference them in your configuration:
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"],
"env": {
"ARXIV_API_KEY": "<your-api-key>"
},
"inputs": {
"api_key": "${env.ARXIV_API_KEY}"
}
}
}
mcpServers:{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
{
"arxiv-mcp": {
"command": "python",
"args": ["-m", "arxiv_server"]
}
}
Note:
Always secure sensitive information like API keys using environment variables as shown in the example above.
Using MCP in FlowHunt
To integrate MCP servers into your FlowHunt workflow, start by adding the MCP component to your flow and connecting it to your AI agent:

Click on the MCP component to open the configuration panel. In the system MCP configuration section, insert your MCP server details using this JSON format:
{
"arxiv-mcp": {
"transport": "streamable_http",
"url": "https://yourmcpserver.example/pathtothemcp/url"
}
}
Once configured, the AI agent is now able to use this MCP as a tool with access to all its functions and capabilities. Remember to change “arxiv-mcp” to your server’s name and replace the URL with your own MCP server URL.
| Section | Availability | Details/Notes |
|---|---|---|
| Overview | ✅ | |
| List of Prompts | ⛔ | None found |
| List of Resources | ⛔ | None found |
| List of Tools | ✅ | |
| Securing API Keys | ✅ | Instructed |
| Sampling Support (less important in evaluation) | ⛔ | Not mentioned |
The arXiv MCP Server offers a focused set of tools for scholarly article retrieval and integration with LLM workflows. Its documentation is clear about features and setup, and it is open source under MIT. However, it does not provide prompt templates or explicit resources, and there is no mention of sampling or roots support. For users needing arXiv integration, it is a solid, reliable option, but it lacks some advanced MCP features.
| Has a LICENSE | ✅ (MIT) |
|---|---|
| Has at least one tool | ✅ |
| Number of Forks | 1 |
| Number of Stars | 4 |
The arXiv MCP Server is a Model Context Protocol server that allows AI assistants and developers to interact with the arXiv scholarly article database using natural language. It supports searching, retrieving metadata, downloading PDFs, and loading article content into large language models.
It provides tools for article URL retrieval, PDF downloading, loading article content into LLMs, metadata extraction, and advanced search queries using various filters like title, author, and abstract.
API keys (if required) should be stored as environment variables and referenced in your MCP server configuration. Example:
{
\"arxiv-mcp\": {
\"command\": \"python\",
\"args\": [\"-m\", \"arxiv_server\"],
\"env\": {
\"ARXIV_API_KEY\": \"
Yes, the 'load_article_to_context' tool allows you to load the full content of an arXiv article directly into your LLM's context for summarization, question answering, or further analysis.
Yes, it is open source under the MIT license.
Supercharge your research flows by connecting arXiv to your AI agents using the arXiv MCP Server. Automate literature reviews, metadata extraction, and more.
The arxiv-latex MCP Server enables AI tools to directly access and process arXiv papers via their LaTeX source files, allowing for precise mathematical interpre...
Integrate FlowHunt with the arXiv MCP Server to automate scholarly article retrieval, PDF downloads, metadata access, and seamless integration with LLMs for adv...
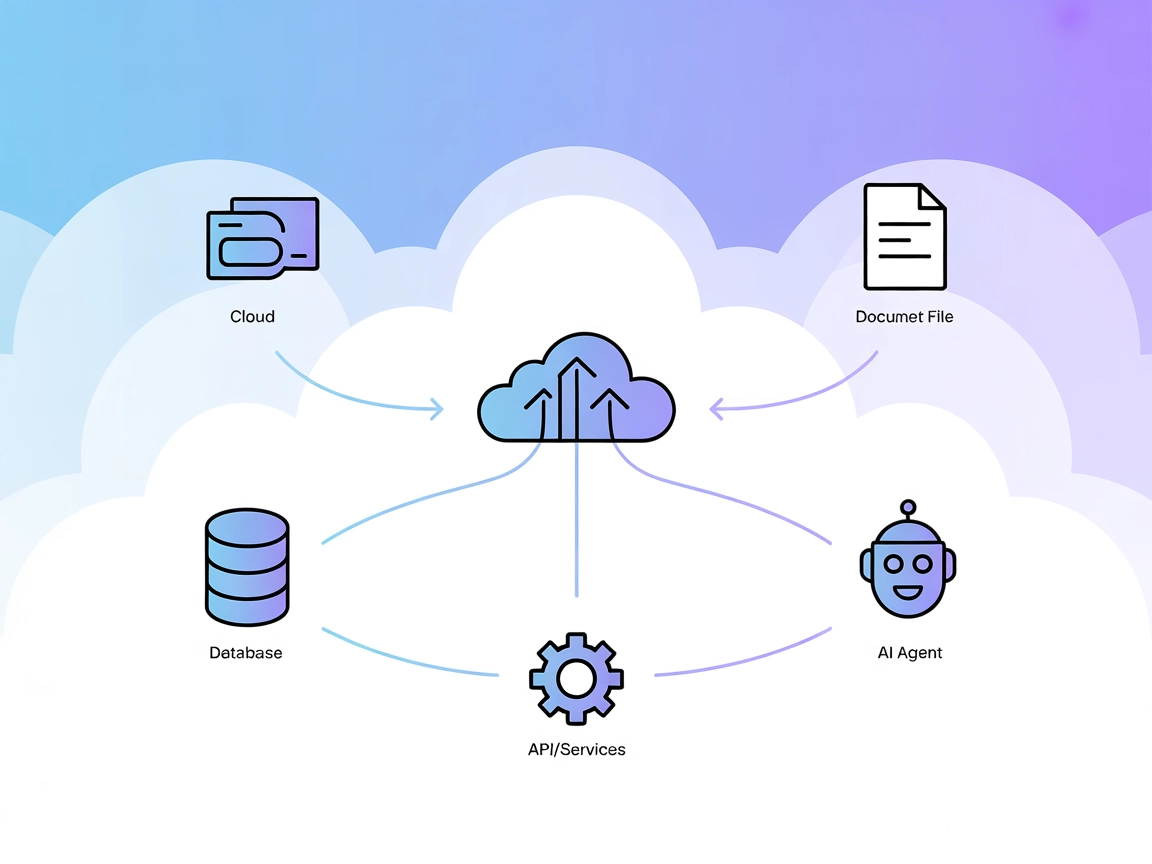
The Model Context Protocol (MCP) Server bridges AI assistants with external data sources, APIs, and services, enabling streamlined integration of complex workfl...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.