AI can analyze large quantities of data in seconds, but only some of the data will be relevant or suitable for output. The Document to Text component gives you control over how the data from retrievers is processed and transformed into text.
The Document to Text component is designed to transform input knowledge documents into plain text format. This is particularly useful in AI and data processing workflows where textual data is required for further processing, analysis, or as input to language models.
What the Component Does
This component takes one or more structured documents (such as HTML, Markdown, PDFs, or other supported formats) and extracts the textual content. It allows you to specify precisely which parts of the documents to export, whether to include metadata, and how to handle document sections or headers. The output is a unified message object containing the extracted text, ready for downstream tasks like summarization, classification, or question answering.
Inputs
The component accepts several configurable inputs:
| Input Name | Type | Required | Description | Default Value |
|---|---|---|---|---|
| Documents | List[Document] | Yes | The knowledge documents to transform into text. | N/A (user provided) |
| From H1 if exists | Boolean | Yes | Start extraction from the first H1 header if present. | true |
| Load from pointer | Boolean | Yes | Start extraction from the pointer best matching the input query, or load all if not matched. | true |
| Max Tokens | Integer | No | Maximum number of tokens in the output text. | 3000 |
| Skip Last Header | Boolean | Yes | Skip the last header (often a footer) to optimize output. | false |
| Strategy | String | Yes | Text extraction strategy: concatenate documents or include equal size from each. | “Include equal size from each documents” |
| Export Content | Multi-select | No | Which content types to include (e.g., H1, H2, Paragraph). | All types selected |
| Include Metadata | Multi-select | No | Metadata fields to include in the output if available. | Product |
Content Types available: H1, H2, H3, H4, H5, H6, Paragraph
Metadata options: Author, Product, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Outputs
The component produces the following output:
- Message: A message object containing the transformed text and any included metadata.
Key Features & Usefulness
- Flexible Content Extraction: Precisely control which parts of your documents are extracted (e.g., only main headers and paragraphs, or all content).
- Metadata Inclusion: Optionally include rich metadata (e.g., author, product, or structured data) in the output, useful for downstream contextualization.
- Token Limit Management: Constrain the output size to fit downstream model requirements by setting a maximum token count.
- Custom Extraction Strategy:
- Concat documents, fill from first up to tokens limit: Prioritizes sequentially filling the output from the first document.
- Include equal size from each document: Balances content from multiple documents within the token limit.
- Smart Section Handling: Options to skip document footers or start from the most relevant section for your query, increasing the relevance of the extracted text.
Typical Use Cases
- Preprocessing knowledge bases for AI models (e.g., before embedding or indexing).
- Summarizing or condensing large documents by extracting only relevant sections.
- Feeding structured content into chatbots, search engines, or other natural language processing pipelines.
- Building hybrid retrieval systems that combine text with metadata for richer context.
Summary Table
| Capability | Description |
|---|---|
| Input Types | List of Documents |
| Output Type | Message (Text + Metadata) |
| Content Granularity | Select headers/paragraphs to include |
| Metadata Options | Select multiple metadata fields to export |
| Output Size Control | Set max tokens |
| Extraction Strategies | Concatenate or balance across documents |
| Section Selection | Start from H1, from pointer, or skip last header |
Strategy
The bot may crawl many documents to create the text output. The Strategy setting lets you control how it utilizes these documents smartly while staying within the token limit.
Currently, there are two possible strategies:
- Include equal size from each document: Utilizes all found documents equally.
- Concat documents, fill from first up to token limit: Links the documents together while prioritizing them by relevance to the query.
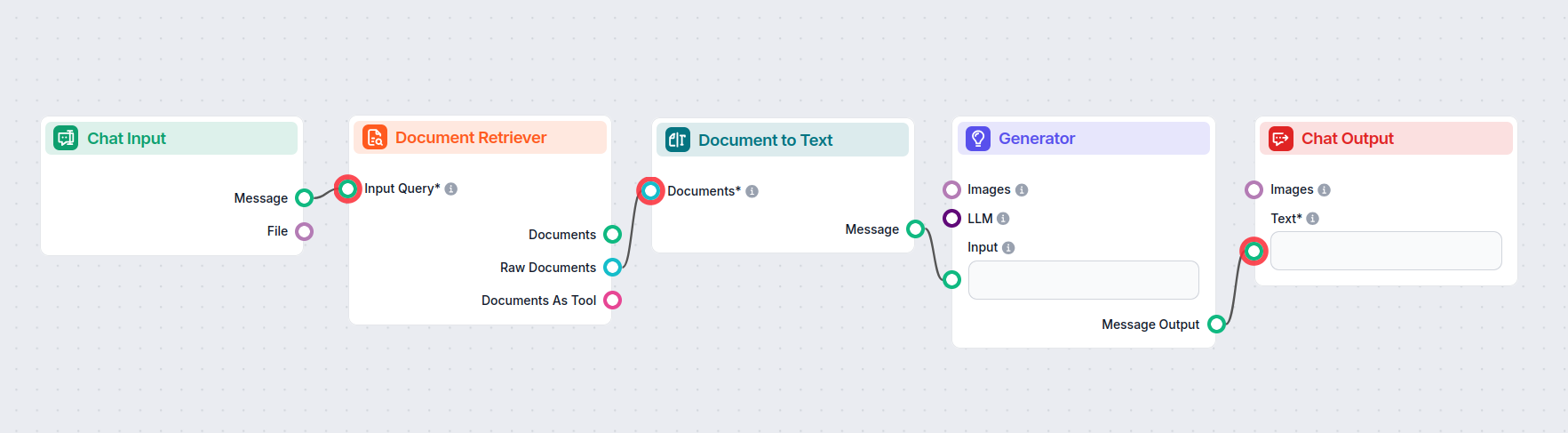
How to connect the Document to Text component to your flow
This is a transformer component, meaning it bridges the gap between two outputs. Document to Text takes Documents outputted by the Retriever components:
- Document Retriever – gets knowledge from connected knowledge sources (pages, documents, etc.).
- URL Retriever – Allows you to specify a URL from which the bot should get knowledge.
- GoogleSearch – Gives the bot the ability to search the web for knowledge.
The knowledge is converted into readable Markdown text as it passes through the transformer. This text can then be connected to components requiring text input, such as splitters, widgets, or outputs.
Here is an example flow using the Document to Text component to bridge the gap between the Document Retrievers and the AI Generator: