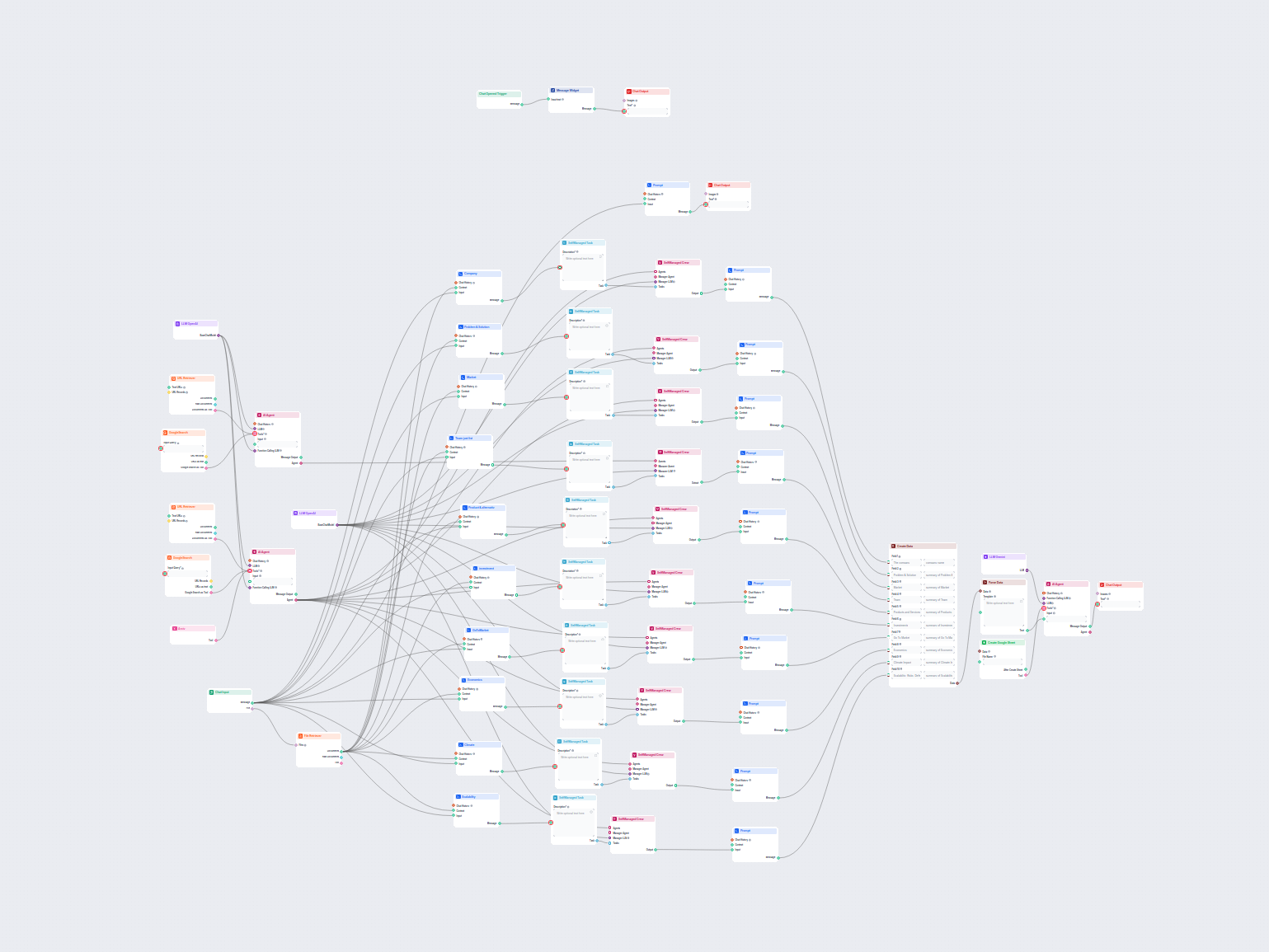
AI-aangedreven Bedrijfsanalyse & Google Sheets Export
Deze AI-workflow analyseert elk bedrijf grondig door openbare gegevens en documenten te onderzoeken, waaronder markt, team, producten, investeringen en meer. He...
4 min lezen
Ontgrendel de kracht van Google’s Gemini-modellen in FlowHunt—wissel tussen AI-modellen, beheer instellingen en bouw eenvoudig slimmere AI-chatbots.
Componentbeschrijving
The LLM Gemini component connects the Gemini models from Google to your flow. While the Generators and Agents are where the actual magic happens, LLM components allow you to control the model used. All components come with ChatGPT-4 by default. You can connect this component if you wish to change the model or gain more control over it.
Remember that connecting an LLM Component is optional. All components that use an LLM come with ChatGPT-4o as the default. The LLM components allow you to change the model and control model settings.
Tokens represent the individual units of text the model processes and generates. Token usage varies with models, and a single token can be anything from words or subwords to a single character. Models are usually priced in millions of tokens.
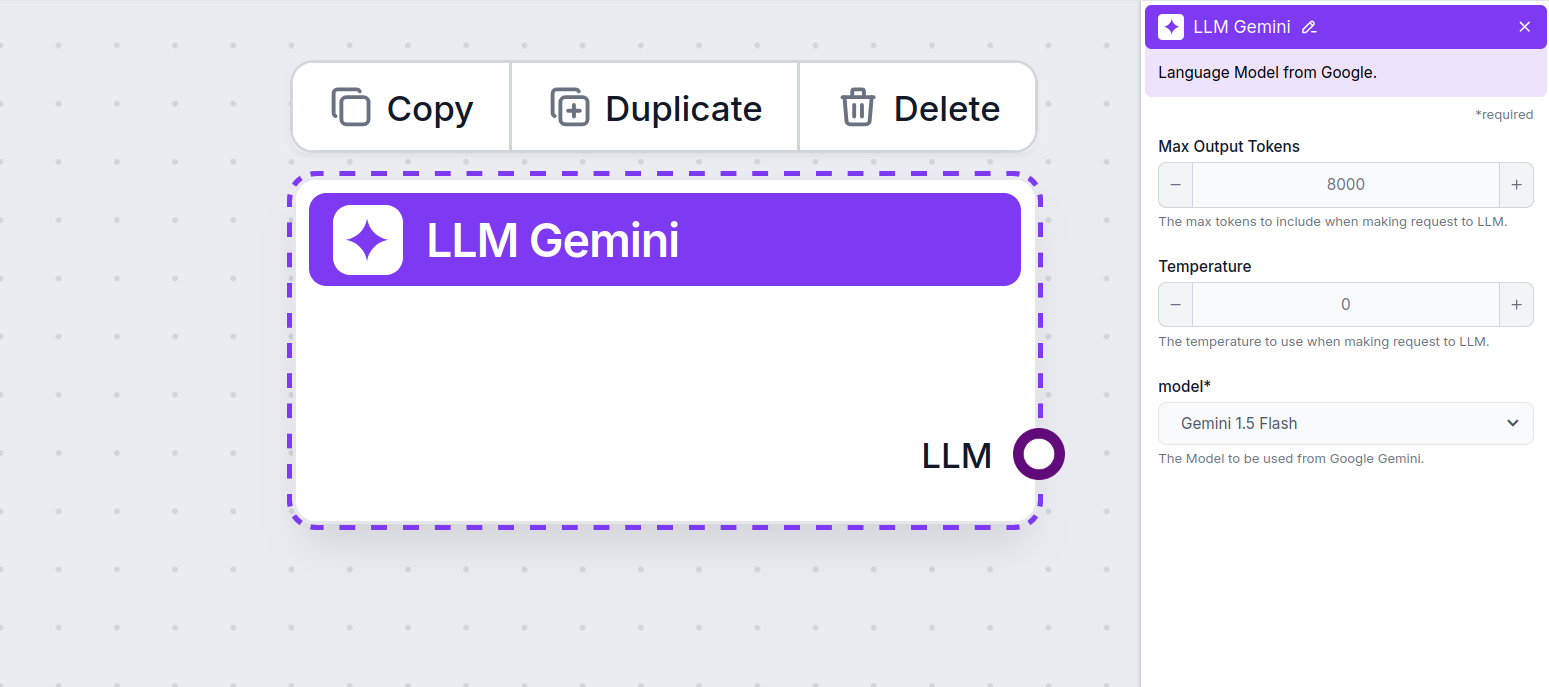
The max tokens setting limits the total number of tokens that can be processed in a single interaction or request, ensuring the responses are generated within reasonable bounds. The default limit is 4,000 tokens, the optimal size for summarizing documents and several sources to generate an answer.
Temperature controls the variability of answers, ranging from 0 to 1.
A temperature of 0.1 will make the responses very to the point but potentially repetitive and deficient.
A high temperature of 1 allows for maximum creativity in answers but creates the risk of irrelevant or even hallucinatory responses.
For example, the recommended temperature for a customer service bot is between 0.2 and 0.5. This level should keep the answers relevant and to the script while allowing for a natural response variation.
This is the model picker. Here, you’ll find all the supported Gemini models from Google. We support all the latest Gemini models:
You’ll notice that all LLM components only have an output handle. Input doesn’t pass through the component, as it only represents the model, while the actual generation happens in AI Agents and Generators.
The LLM handle is always purple. The LLM input handle is found on any component that uses AI to generate text or process data. You can see the options by clicking the handle:
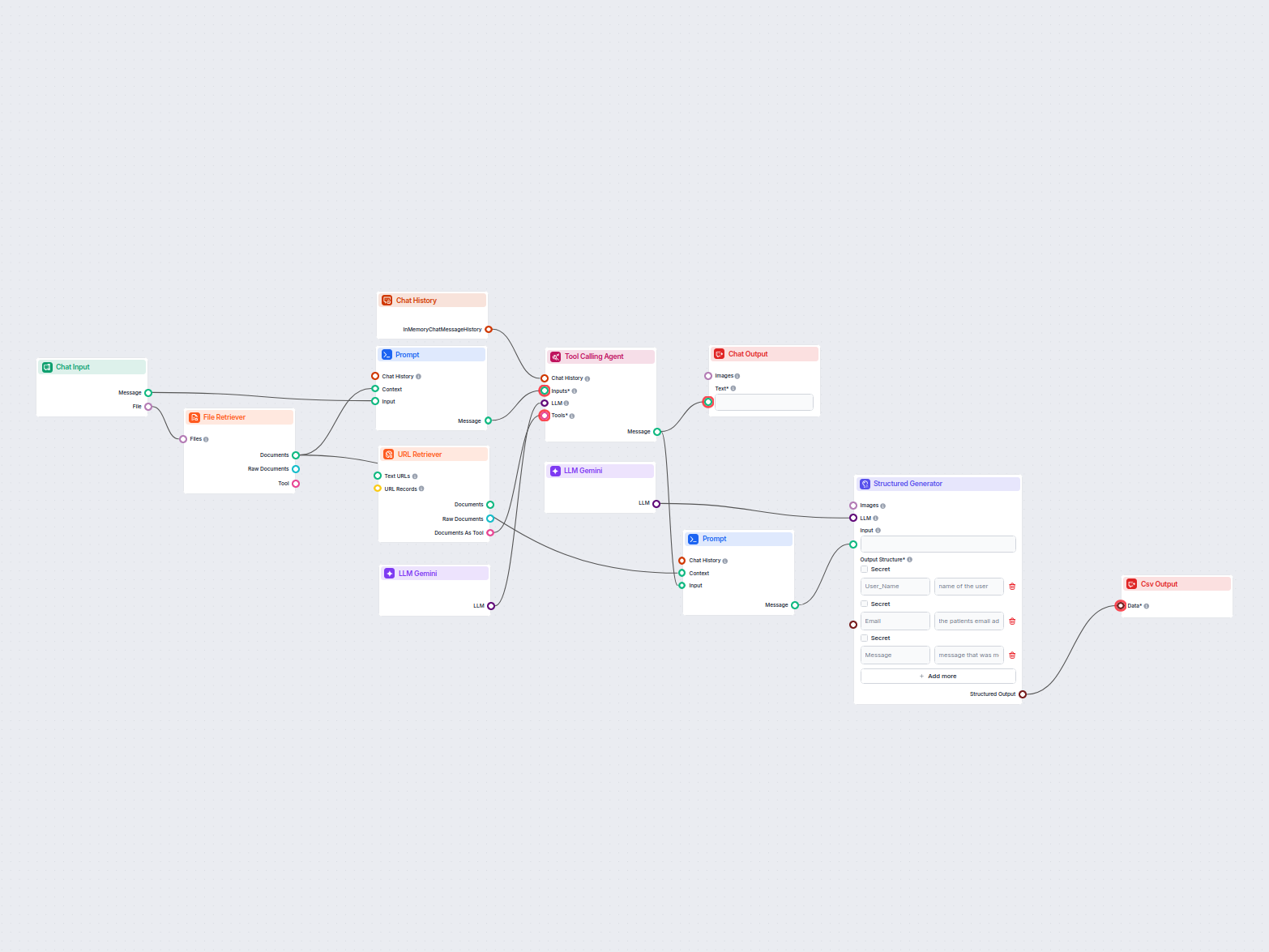
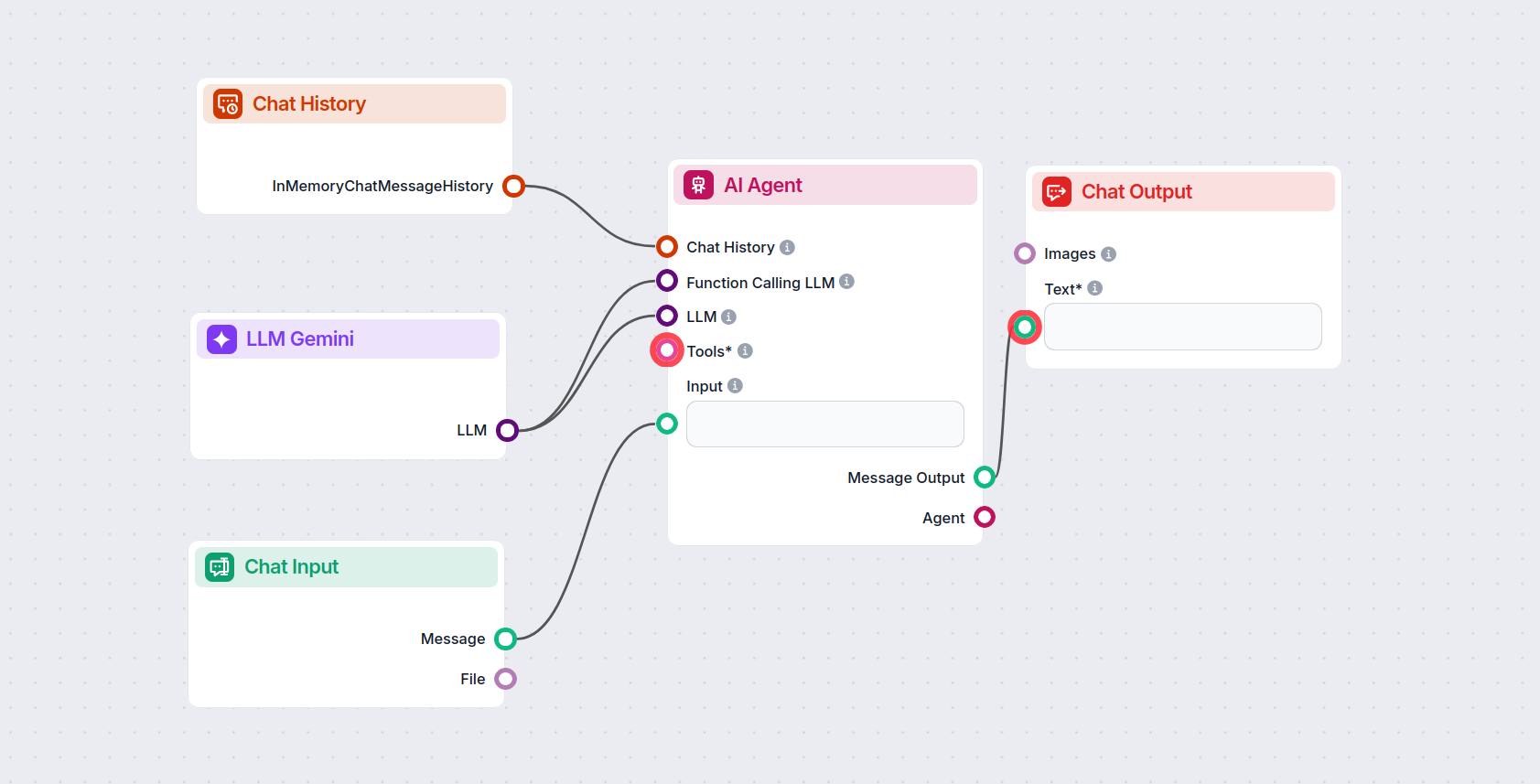
This allows you to create all sorts of tools. Let’s see the component in action. Here’s a simple AI Agent chatbot Flow that’s using Gemini 2.0 Flash Experimental to generate responses. You can think of it as a basic Gemini chatbot.
This simple Chatbot Flow includes:
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de LLM Gemini-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.
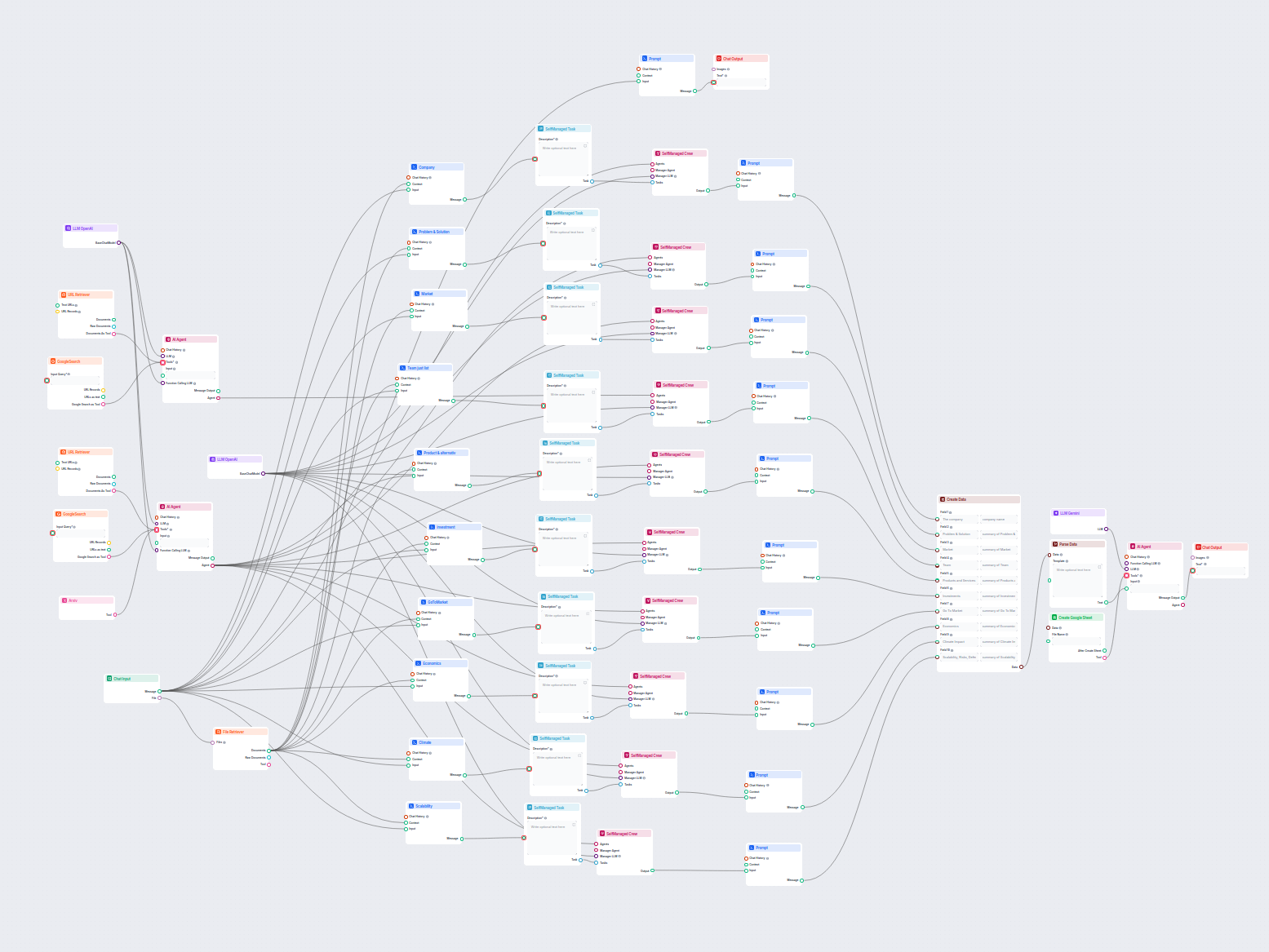
Deze AI-workflow analyseert elk bedrijf grondig door openbare gegevens en documenten te onderzoeken, waaronder markt, team, producten, investeringen en meer. He...
Deze AI-gestuurde workflow levert een uitgebreide, data-gedreven bedrijfsanalyse. Het verzamelt informatie over de achtergrond van het bedrijf, marktlandschap, ...
Deze workflow extraheert en ordent kerninformatie uit e-mails en bijgevoegde bestanden, gebruikt AI om de gegevens te verwerken en te structureren, en levert de...
Deze workflow automatiseert het SEO-review- en auditproces voor webpagina's. Het analyseert paginacontent op SEO best practices, voert controles uit via Google ...
LLM Gemini verbindt Google's Gemini-modellen met je FlowHunt AI-flows, zodat je kunt kiezen uit de nieuwste Gemini-varianten voor tekstgeneratie en hun gedrag kunt aanpassen.
FlowHunt ondersteunt Gemini 2.0 Flash Experimental, Gemini 1.5 Flash, Gemini 1.5 Flash-8B en Gemini 1.5 Pro—elk met unieke mogelijkheden voor tekst-, beeld-, audio- en video-invoer.
Max Tokens beperkt de lengte van het antwoord, terwijl Temperatuur de creativiteit bepaalt—lagere waarden geven gerichte antwoorden, hogere waarden zorgen voor meer variatie. Beide kunnen per model in FlowHunt worden ingesteld.
Nee, het gebruik van LLM-componenten is optioneel. Alle AI-flows worden standaard geleverd met ChatGPT-4o, maar door LLM Gemini toe te voegen kun je overschakelen naar Google-modellen en hun instellingen verfijnen.
Begin met het bouwen van geavanceerde AI-chatbots en tools met Gemini en andere topmodellen—alles in één dashboard. Wissel van model, pas instellingen aan en stroomlijn je workflows.
FlowHunt ondersteunt tientallen AI-modellen, waaronder de revolutionaire DeepSeek-modellen. Hier lees je hoe je DeepSeek gebruikt in je AI-tools en chatbots.
FlowHunt ondersteunt tientallen AI-tekstmodellen, waaronder modellen van Mistral. Hier lees je hoe je Mistral in jouw AI-tools en chatbots kunt gebruiken.
FlowHunt ondersteunt tientallen tekstgeneratiemodellen, waaronder de Llama-modellen van Meta. Leer hoe je Llama integreert in je AI-tools en chatbots, pas inste...