Vat elke URL samen tot een metabeschrijving
Maakt automatisch een boeiende, SEO-vriendelijke metabeschrijving voor elke webpagina, PDF, YouTube-video of documentlink door de inhoud te analyseren en een be...
3 min lezen
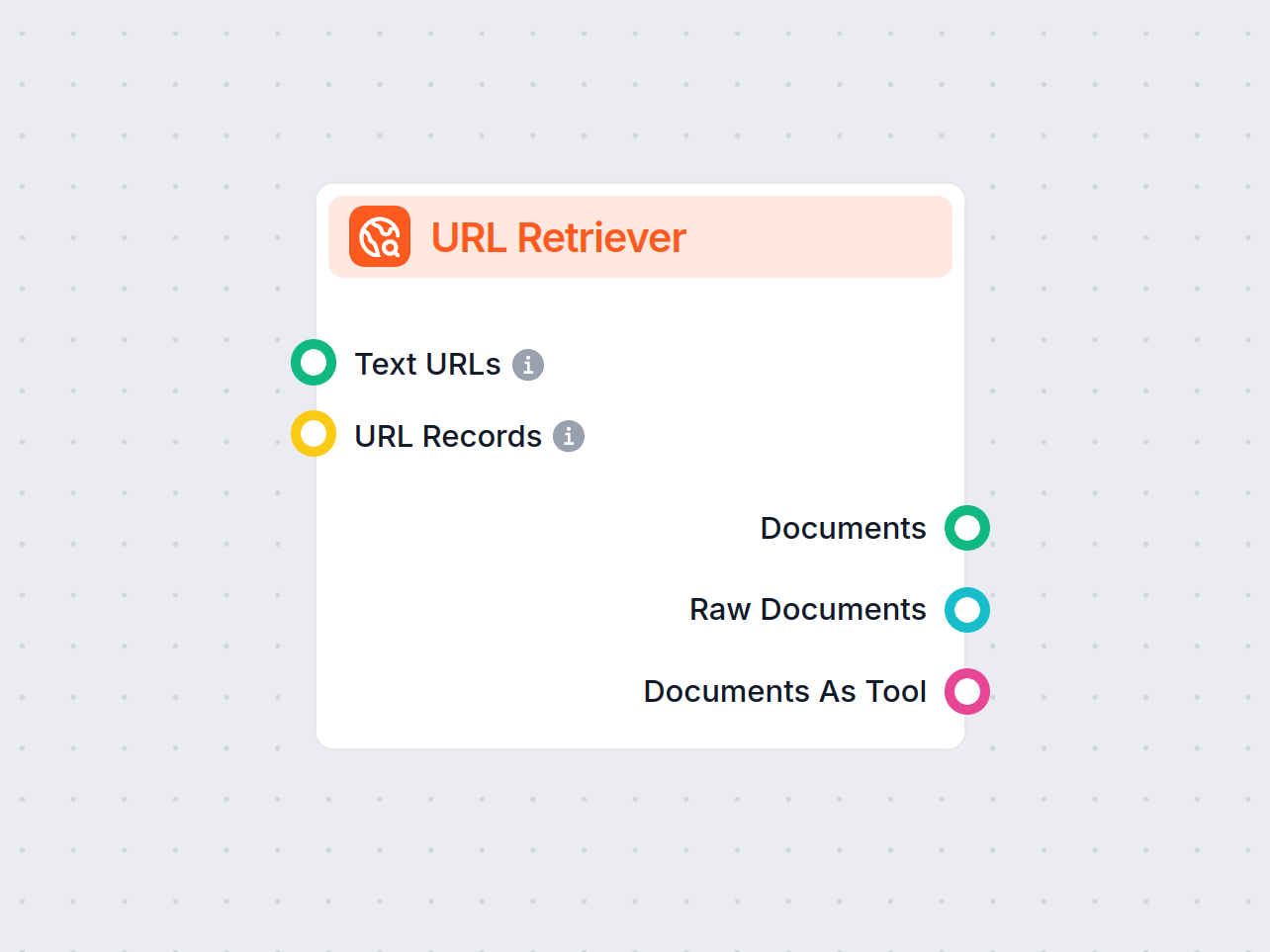
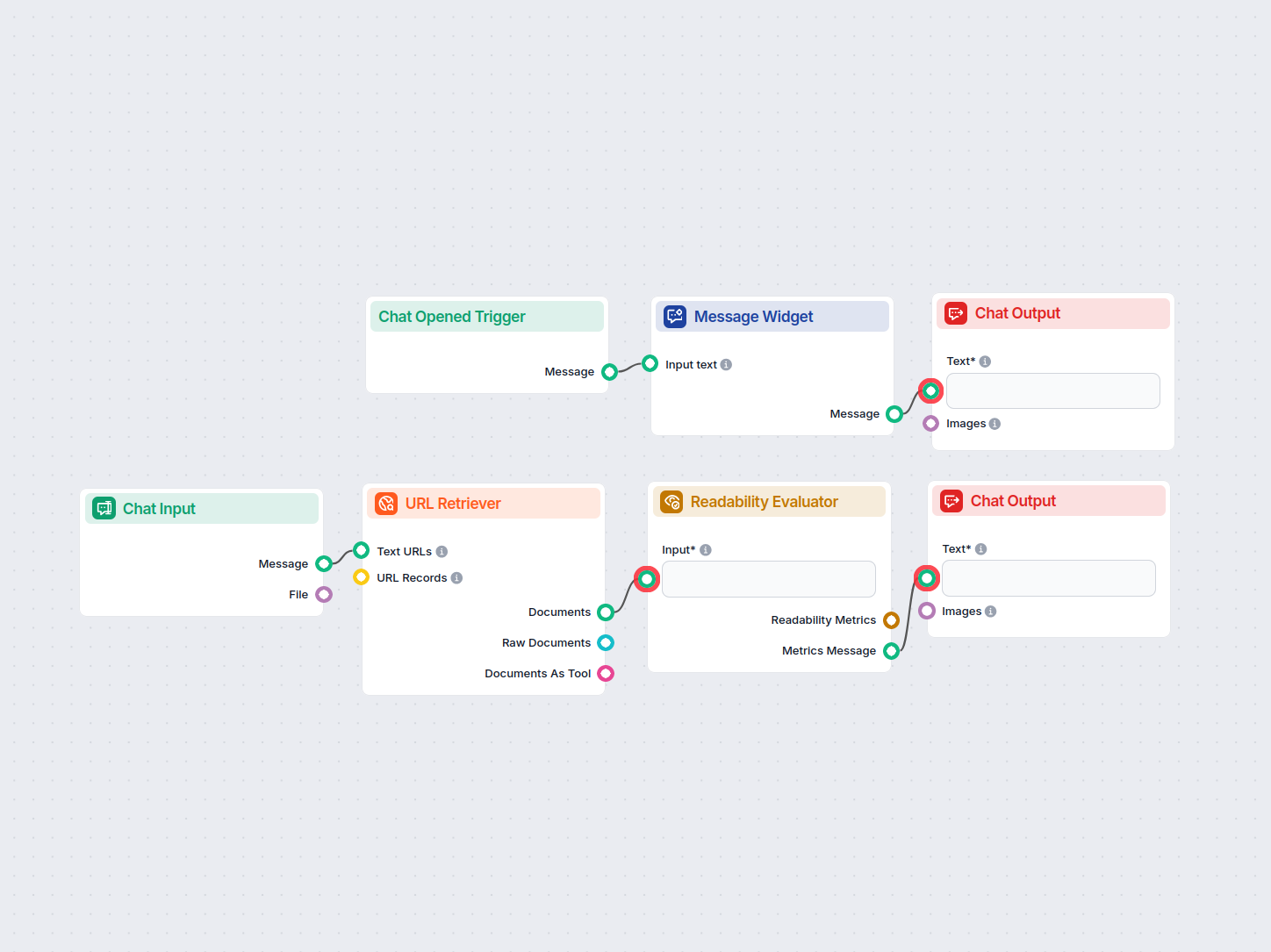
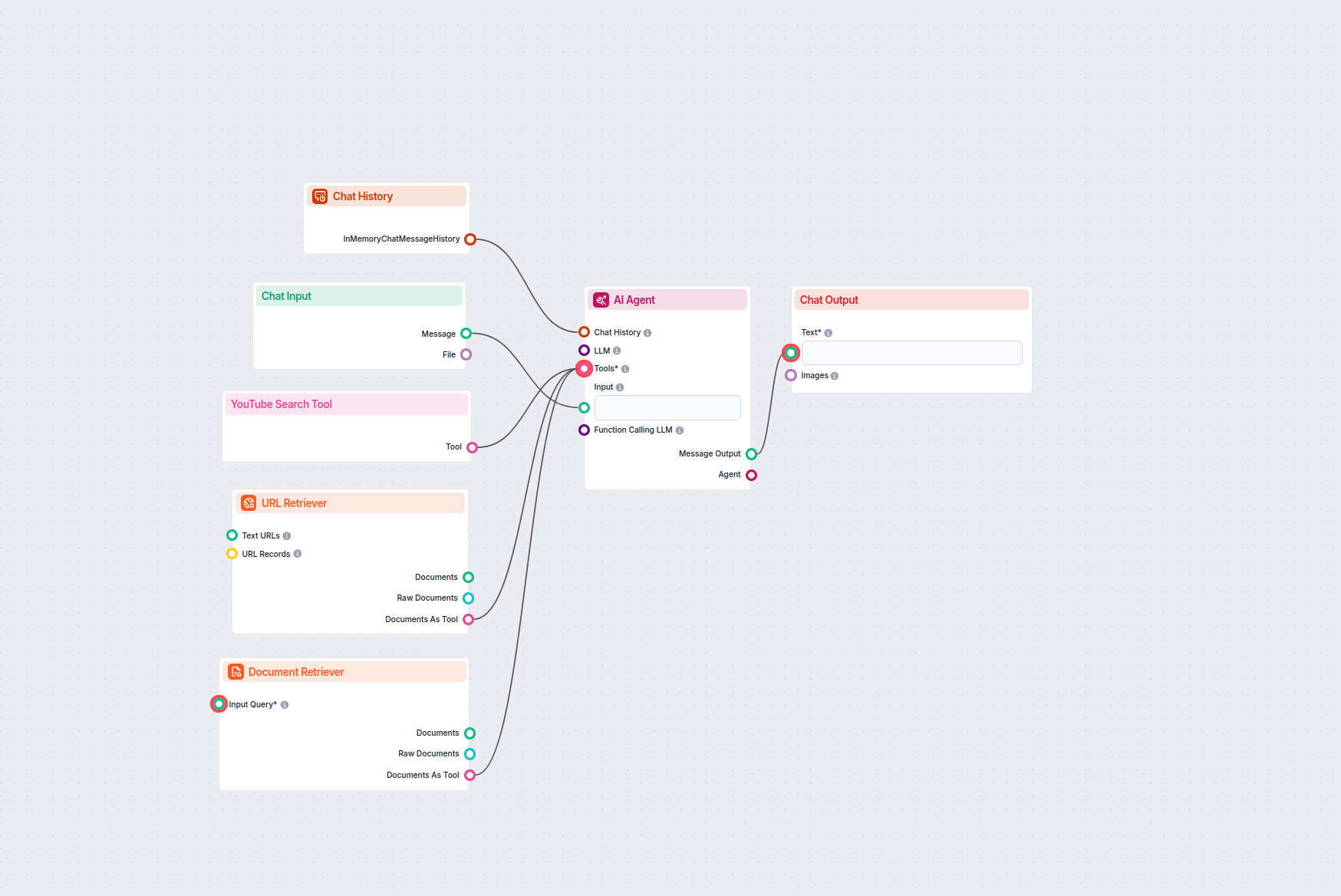
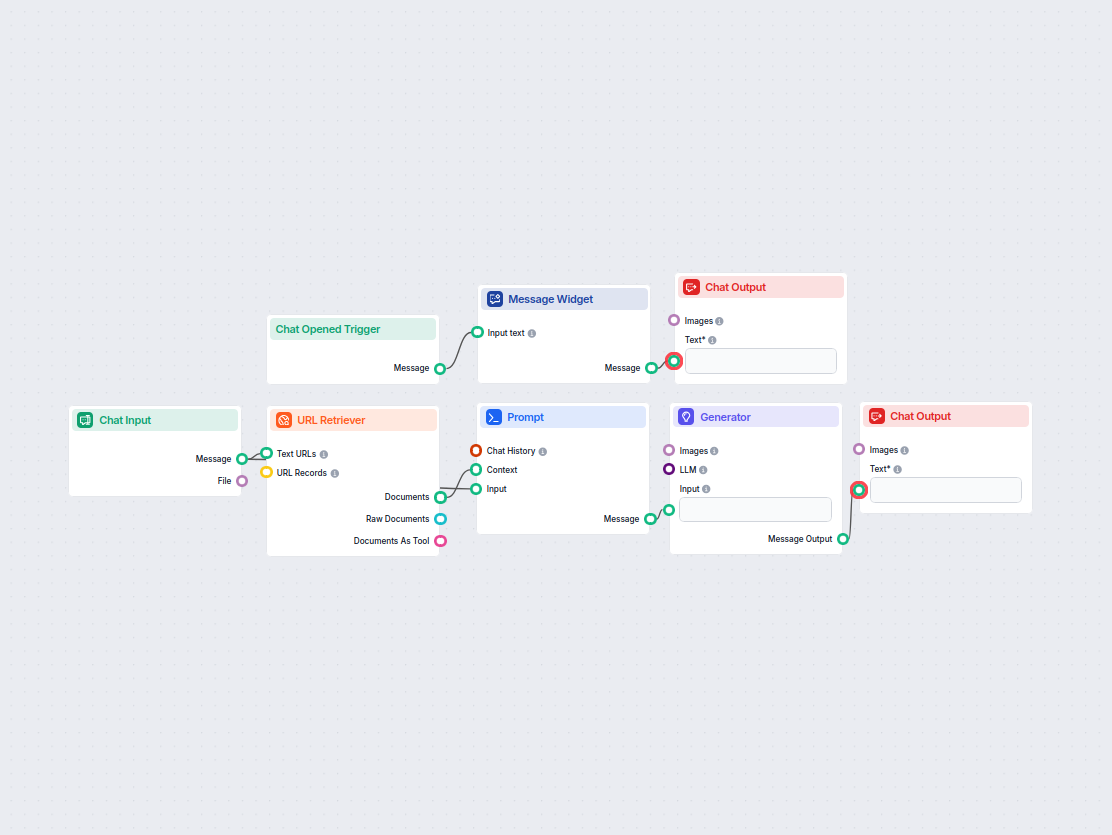
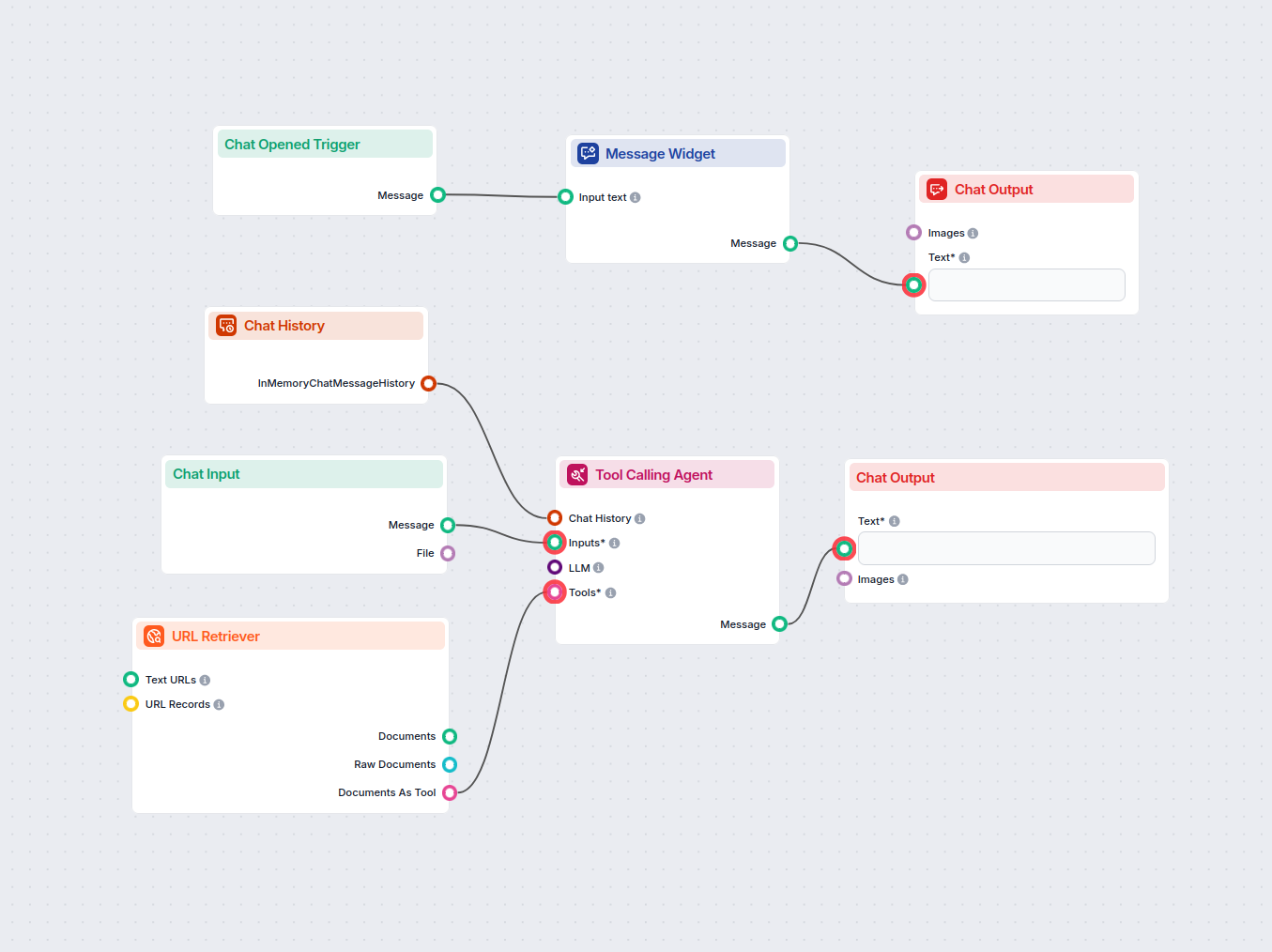
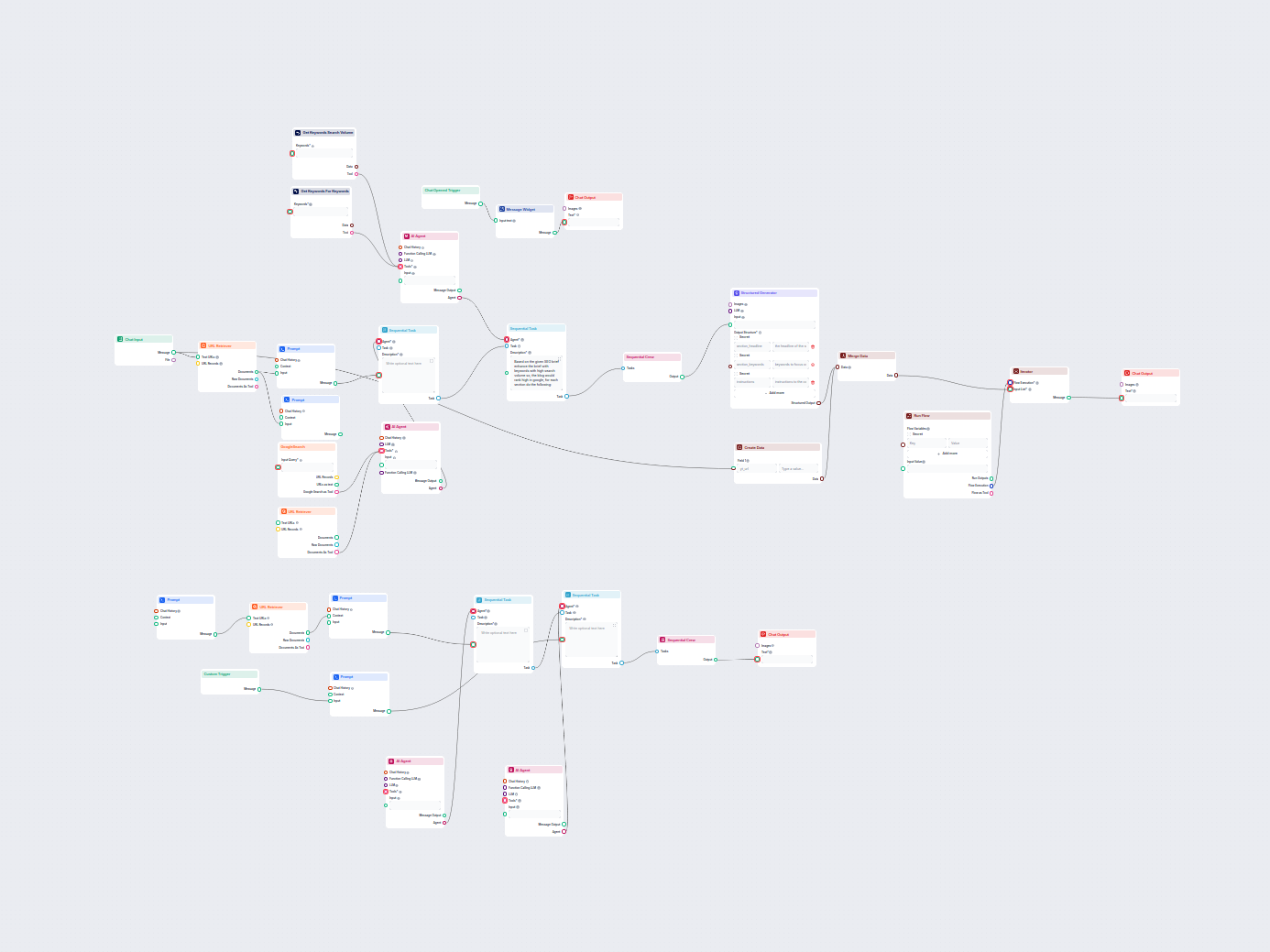
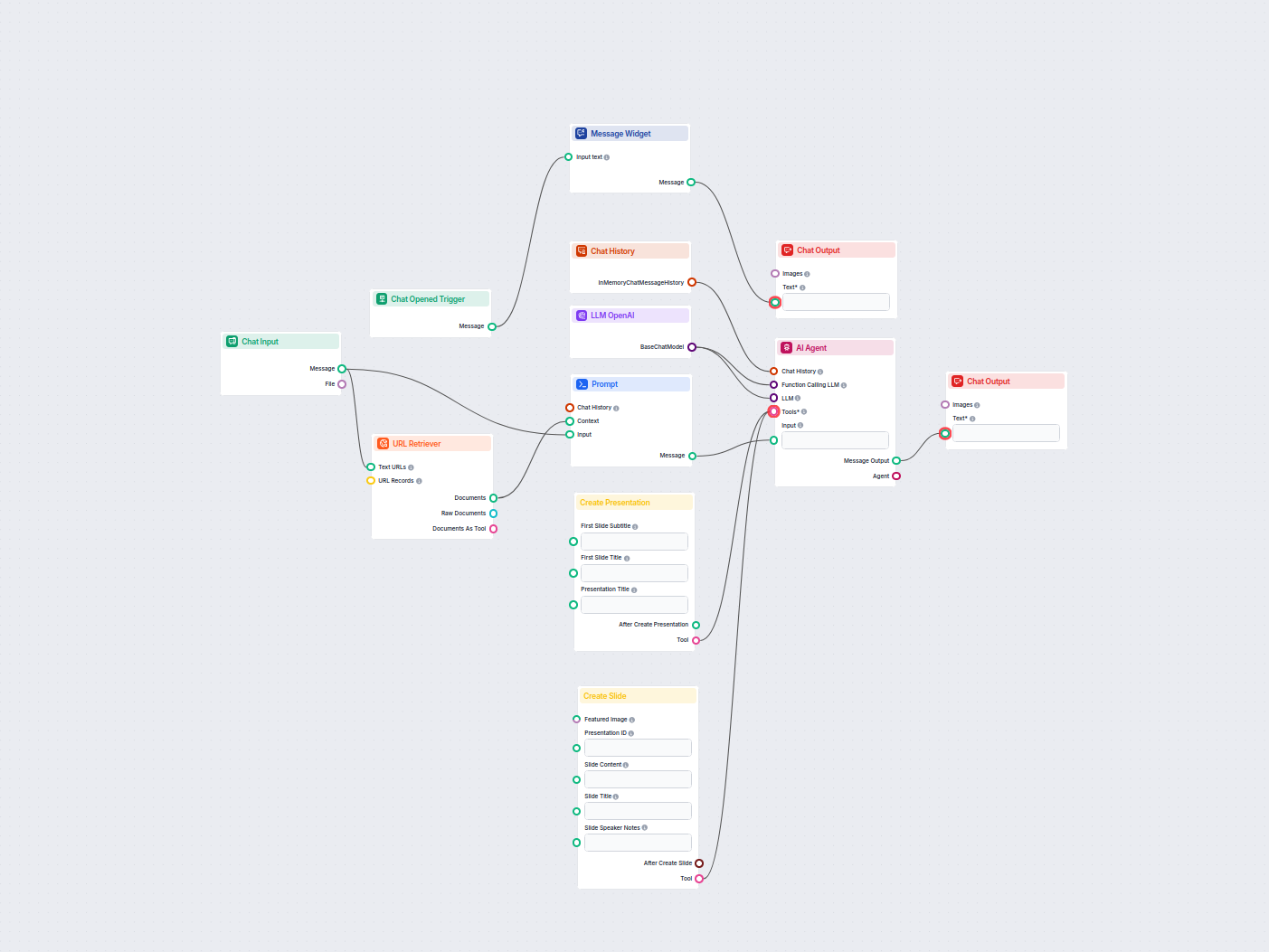
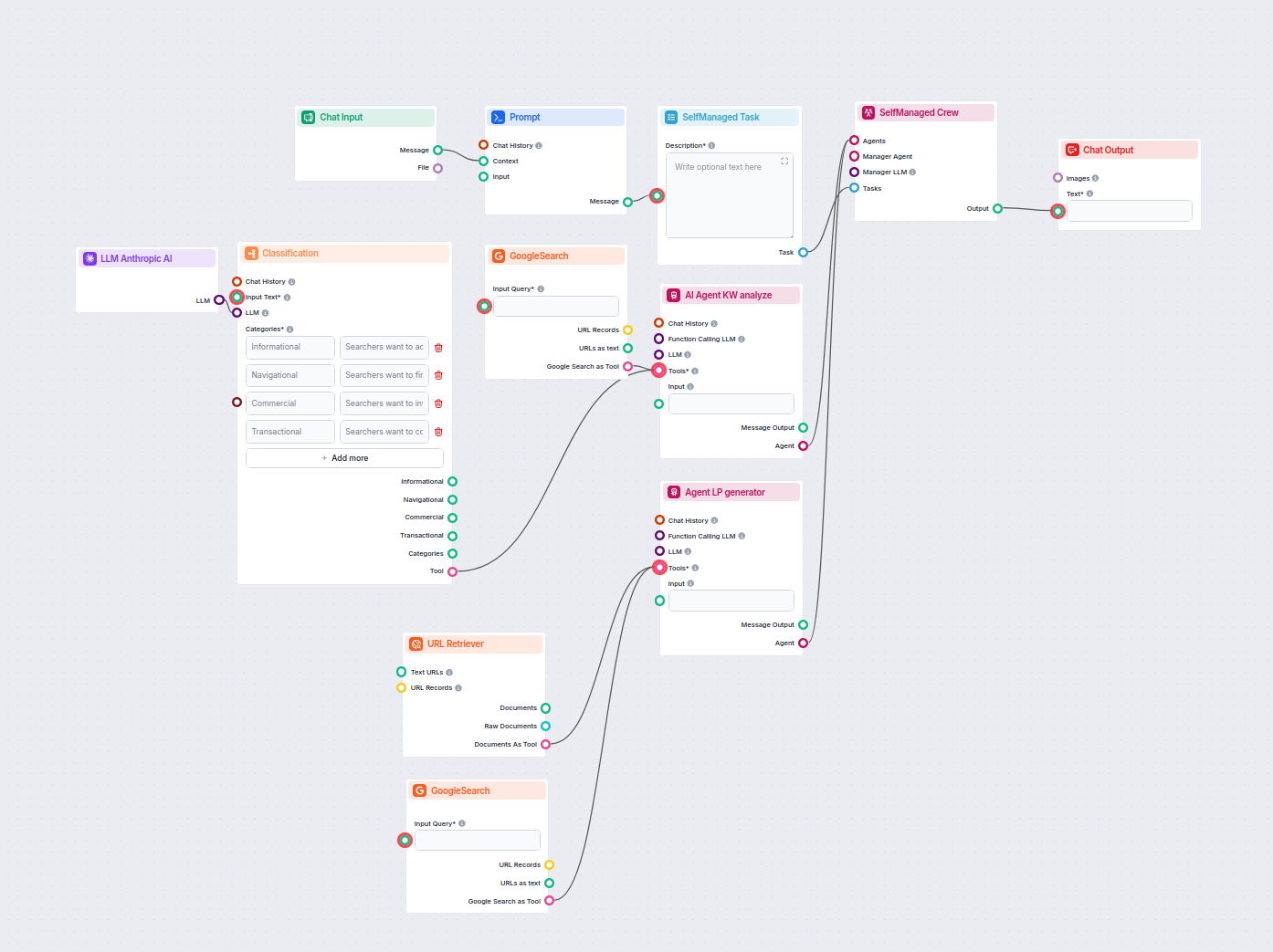
Met de URL Retriever kun je inhoud van weblinks ophalen en verwerken, met ondersteuning voor OCR, metadata-extractie en flexibele output voor AI-workflows.
Componentbeschrijving
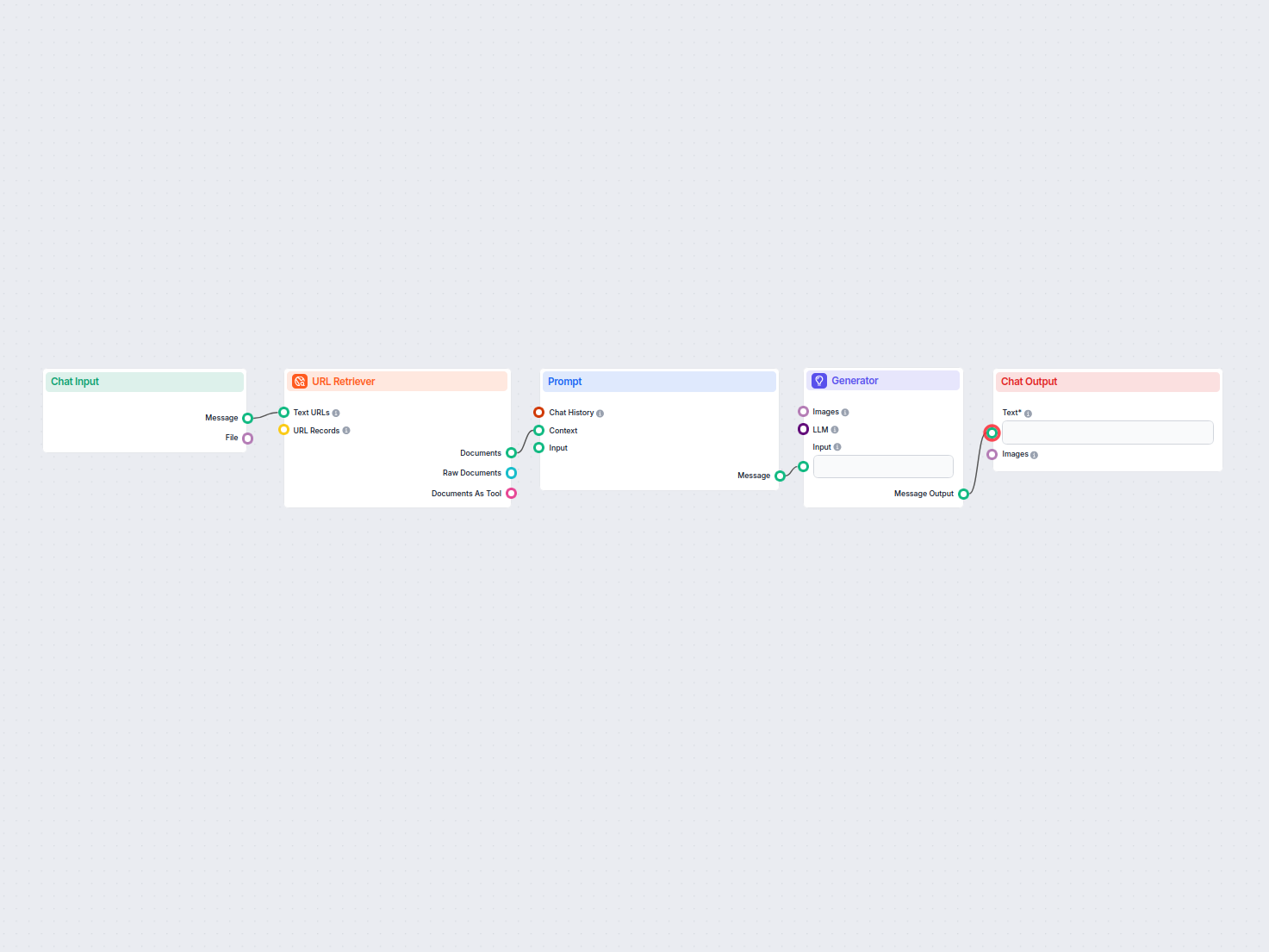
The URL Retriever is a versatile flow component designed to fetch and process web content from specified URLs, returning the information as structured documents. It serves as a bridge between external online content and your AI workflow, enabling you to integrate, analyze, or process web-based information efficiently.
This component retrieves the content of one or multiple URLs provided as input. It can extract the main text, metadata, and even process content from images using Optical Character Recognition (OCR). The retrieved data is then made available in various structured formats suitable for downstream AI tasks such as summarization, question answering, or knowledge extraction.
You can supply URLs to the component in two ways:
Text URLs:
MessageURL Records:
UrlRecord| Parameter | Type | Default | Description |
|---|---|---|---|
| Apply OCR | Boolean | false | If enabled, applies OCR to extract text from images in the document. |
| Cache TTL | Dropdown | 2 weeks | How long the content should be cached, with options from no cache up to 1 year. |
| From H1 if exists | Boolean | true | Begins extraction from the H1 tag if present, focusing on main content. |
| Load from pointer | Boolean | true | Loads content starting from the most relevant section based on your query. |
| Hide Resources | Boolean | false | Hides the retrieved resources from being output or displayed. |
| Max Tokens | Integer | 3000 | Sets the maximum number of tokens for the output text. |
| Skip Last Header | Boolean | true | Skips the last header during extraction for streamlined content. |
| Strategy | Dropdown | Include equal size from each documents | Determines how content is combined: concatenate fully or include equal parts from each document. |
| Export Content | Multi-select | All | Choose which HTML elements to export (H1-H6, Paragraph). |
| Include Metadata | Multi-select | Product | Specify which metadata fields to include (e.g., Product, Author, Website, etc.). |
| Verbose | Boolean | false | Enables detailed output for debugging or information purposes. |
| Tool Name | String | (empty) | Optionally assign a custom name to the tool for agent reference. |
| Tool Description | Multiline | (empty) | Provide a description to help agents understand the tool’s purpose. |
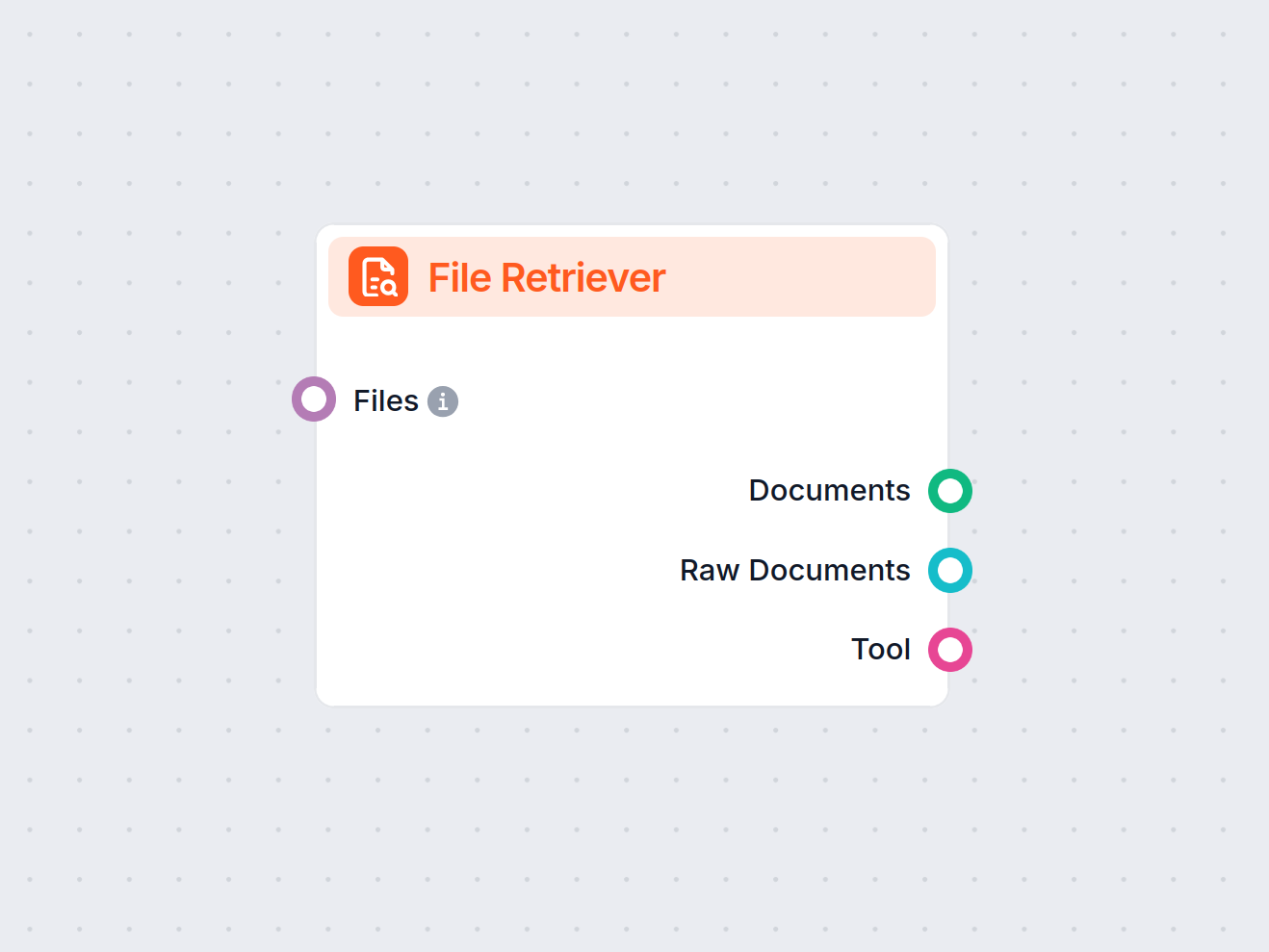
The URL Retriever provides its outputs in several formats, allowing flexible integration with various AI processes:
| Output Name | Type | Description |
|---|---|---|
| Documents | Message | The processed content from the URLs, ready for use in messaging-oriented workflows. |
| Raw Documents | Document | The raw, unprocessed document objects for advanced downstream processing. |
| Documents As Tool | Tool | The content packaged as a tool, enabling agent-based workflows to utilize the documents. |
| Feature | Description |
|---|---|
| Fetches URLs | Retrieves and processes web content from provided URLs. |
| OCR Support | Extracts text from images in documents if enabled. |
| Metadata Extraction | Optionally includes metadata such as author, product, or schema.org types. |
| Customizable Output | Select which HTML elements or metadata to export. |
| Caching | Configurable cache lifetimes for efficiency. |
| Multiple Output Types | Supports message, raw document, and tool outputs for workflow flexibility. |
The URL Retriever is a powerful and flexible bridge between web content and your AI workflows, offering granular control over content extraction and integration.
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de URL Retriever-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.
Maakt automatisch een boeiende, SEO-vriendelijke metabeschrijving voor elke webpagina, PDF, YouTube-video of documentlink door de inhoud te analyseren en een be...
Analyseer de leesbaarheid van elke website door de URL in te voeren. Deze workflow haalt de inhoud op van de opgegeven URL en beoordeelt de leesbaarheid met beh...
Genereer beknopte conclusies van websites, geüploade documenten of YouTube-video's met behulp van AI. Perfect om snel de belangrijkste punten samen te vatten en...
Genereer automatisch SEO-geoptimaliseerde YouTube videotitels, beschrijvingen en hashtags van elke webpagina-URL. Perfect voor marketeers, contentmakers en bedr...
Chat met elke YouTube-video door met het transcript te praten. Haal direct de inhoud van de video op en stel vragen om beknopte, door AI aangedreven antwoorden ...
Genereer automatisch hoog scorende SEO-blogposts van YouTube-video's. Deze workflow extraheert videotranscripten, analyseert top SEO-zoekwoorden, maakt een gede...
Zet elke YouTube-video in enkele minuten om in een professionele Google Slides-presentatie. Deze AI-aangedreven workflow extraheert content van een opgegeven Yo...
Deze door AI aangedreven workflow classificeert zoekopdrachten op intentie, onderzoekt de best scorende URL's en genereert een sterk geoptimaliseerde landingspa...
Tonen 61 tot 68 van 68 resultaten
De URL Retriever haalt inhoud op van opgegeven weblinks en verwerkt deze, waardoor tekst en metadata van online documenten beschikbaar worden voor je workflow of AI-agent.
Ja, door de OCR-optie in te schakelen, kan de component tekst uit afbeeldingsgebaseerde documenten of gescande PDF's halen.
Het levert verwerkte documenten als tekstberichten, ruwe documentobjecten of als tool voor agent-workflows, afhankelijk van je instellingen.
Je kunt instellen hoelang opgehaalde inhoud wordt gecached, waardoor herhaalde downloads worden verminderd en je flows worden versneld.
Ja, je kunt specificeren welke koppen, paragrafen of metadata-velden moeten worden opgenomen in de output, voor gerichte extractie.
Absoluut. De URL Retriever is essentieel voor elke automatisering of chatbot die live webinhoud moet lezen, verwerken of samenvatten.
Versnel je workflows door live webinhoud te integreren. Extraheer, verwerk en gebruik data van URL's met gemak.
Integreer uw workflows met Google Docs via de Google Docs Retriever-component—haal naadloos documentinhoud op voor gebruik in automatiseringen, chatbots of kenn...
De Bestandsophaler-component in FlowHunt stelt je in staat om bestanden in je workflow te brengen en deze om te zetten in documenten voor verdere verwerking. He...
Leg direct website-snapshots vast met de Screenshot Tool-component. Automatiseer eenvoudig het maken van screenshots van elke URL binnen je workflow—perfect voo...