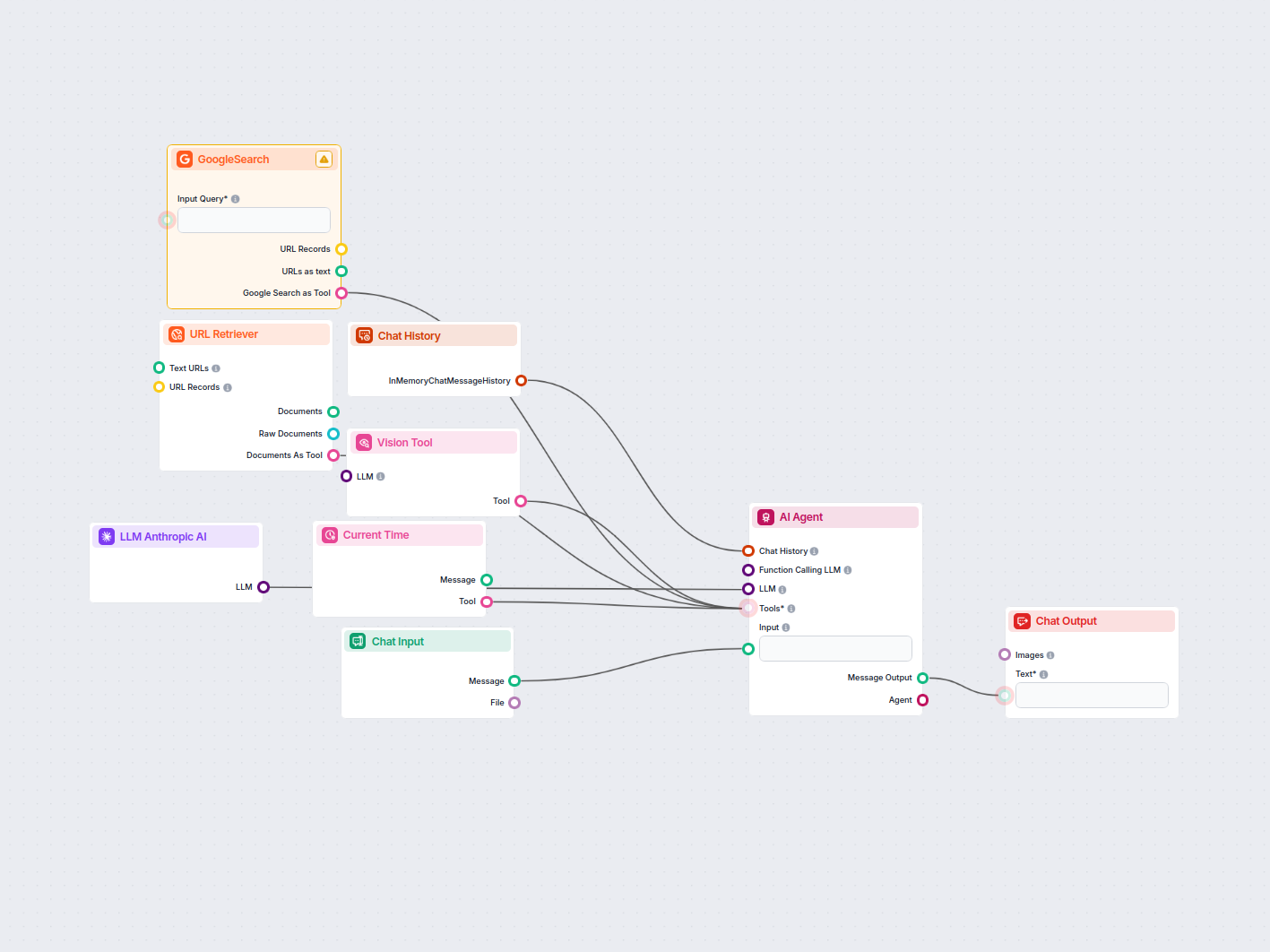
LinkedIn Ad Concurrentie-analyse
Deze workflow automatiseert LinkedIn advertentie-marktonderzoek door de belangrijkste concurrenten voor een zoekwoord te identificeren, hun advertentieteksten e...
4 min lezen
Met de Vision Tool-component kan AI afbeeldingen analyseren, waardevolle inzichten extraheren en vragen beantwoorden op basis van visuele inhoud binnen je workflows.
Componentbeschrijving
The Vision Tool is a component designed to enable AI workflows to process and analyze images provided as attachments. It empowers AI agents to “see” images, extract meaningful information, and answer questions about the visual content. This makes it especially valuable for scenarios where understanding or interpreting images is essential, such as document processing, visual QA, content moderation, or multimedia analysis.
| Input Name | Type | Description | Required | Advanced |
|---|---|---|---|---|
| LLM (model) | BaseChatModel | The language model used for generating text responses based on image analysis. | No | No |
| Tool Description | String (multi) | Description that helps the agent understand how to use this tool. | No | Yes |
| Tool Name | String | The reference name for this tool within agent workflows. | No | Yes |
| Verbose | Boolean | Option to enable detailed (verbose) output for debugging or transparency. | No | Yes |
| Output Name | Type | Description |
|---|---|---|
| Tool | Tool | The configured Vision Tool instance ready for integration |
The Vision Tool outputs a Tool instance that can be used by AI agents to process images and produce relevant responses.
Incorporating the Vision Tool into your AI processes unlocks the ability to work with visual data, not just text. It bridges the gap between language and image understanding, creating opportunities for richer, more interactive, and intelligent applications.
Summary of Benefits:
By using the Vision Tool, your AI workflows can become more capable and versatile, paving the way for next-generation applications that leverage both text and vision intelligence.
Om u snel op weg te helpen, hebben we verschillende voorbeeld-flowsjablonen voorbereid die laten zien hoe u de Vision Tool-component effectief kunt gebruiken. Deze sjablonen tonen verschillende gebruikscases en best practices, waardoor het voor u gemakkelijker wordt om de component te begrijpen en te implementeren in uw eigen projecten.
Deze workflow automatiseert LinkedIn advertentie-marktonderzoek door de belangrijkste concurrenten voor een zoekwoord te identificeren, hun advertentieteksten e...
De Vision Tool stelt je flow in staat om afbeeldingen te verwerken, betekenisvolle informatie te extraheren en vragen over de afbeeldingsinhoud te beantwoorden met behulp van AI.
Ja, de Vision Tool is ontworpen om afbeeldingen te interpreteren in de context van je workflow, zodat AI-agenten visuele en tekstuele informatie kunnen combineren voor intelligentere automatisering.
Typische toepassingen zijn documentverwerking, geautomatiseerde visuele inspectie, het extraheren van gegevens uit afbeeldingen en het verbeteren van chatbot-gesprekken met beeldbegrip.
Zeker. De Vision Tool is een plug-and-play component in FlowHunt die eenvoudig kan worden gekoppeld aan andere workflow-elementen die beeldanalyse vereisen.
Je kunt een AI-model selecteren of configureren, maar FlowHunt biedt verstandige standaardinstellingen voor snelle setup en experimentatie.
Verbeter je workflows met AI-gestuurd beeldbegrip—probeer de Vision Tool vandaag nog in FlowHunt.
Ontdek de Photomatic AI Beeldgenerator-component—zet tekstprompts om in hoogwaardige AI-gegenereerde afbeeldingen met geavanceerde modellen, aanpasbare effecten...
Genereer verbluffende afbeeldingen uit tekstprompts met de Flux Afbeelding Generator-component in FlowHunt. Pas de output aan met modelkeuze, afbeeldingsverhoud...
De Bestandsophaler-component in FlowHunt stelt je in staat om bestanden in je workflow te brengen en deze om te zetten in documenten voor verdere verwerking. He...