
Tekst vertalen met AI voor beginners
Een praktische gids voor het vertalen van content tussen talen terwijl stijl, toon en structuur behouden blijven — en hoe je vertalingen kunt reverse-engineeren...
3 min lezen
ChatGPT
Beginner
+1
Gebruik de indexering overslaan functie van FlowHunt om herhalende of ongeschikte inhoud uit de kennisbank van je AI-chatbot te weren, zodat je zorgt voor relevante en veilige interacties.
Hoe krachtig ook, AI blijft een machine die de informatie doorgeeft die het leert. Het begrijpt geen grappen, hypothetische situaties of sarcasme, wat vaak leidt tot de meest hilarisch foute (en soms erg schadelijke) antwoorden. Om ervoor te zorgen dat je chatbot geen nieuwe AI-rel opstelt en om hem je inhoud beter te laten begrijpen, kun je aangeven welke content hij moet overslaan.
De manier om de betrouwbaarheid van AI te waarborgen is door de informatie die het leert te controleren. Niet alle inhoud is geschikt voor gebruik door de chatbot. De flowhunt-skip class stelt je in staat content te markeren die FlowHunt niet mag indexeren. Elk HTML-element met deze class wordt genegeerd tijdens de verwerking van de content.
Er zijn twee hoofdredenen om deze class te gebruiken, maar voel je vrij om deze toe te passen op alle inhoud die je onnodig of ongeschikt vindt voor de bot.
Herhalende inhoud overslaan: Als vergelijkbare inhoud steeds opnieuw wordt geïndexeerd, wordt het voor AI lastig om te onderscheiden en te categoriseren waar de inhoud over gaat. Door dubbele informatie over te slaan, bespaar je bovendien op de lange termijn op tekstverwerkingskosten.
Risicovolle of ongepaste informatie overslaan: Je moet alle informatie overslaan die ervoor kan zorgen dat de AI verkeerde, schadelijke of uit-de-context antwoorden geeft. Wees extra voorzichtig als je merktoon vaak gebruikmaakt van grappen of sterke taal. Hoewel dat voor andere content prima is, zullen gebruikers een bijdehante bot wellicht niet waarderen.
FlowHunt crawlt en indexeert je website om de chatbot context te geven. Alles wat FlowHunt indexeert, kan je chatbot op een gegeven moment gebruiken.
Door de flowhunt-skip class toe te voegen aan HTML-elementen kun je aangeven welke content je niet wilt laten indexeren. Elk element met deze class wordt genegeerd en bereikt de chatbot nooit.
Hier is een voorbeeld van het gebruik van de class:
<div class="flowhunt-skip">
<h2>Dubbele inhoud</h2>
<p>Deze content is dubbel. Ik wil niet dat FlowHunt dit opnieuw indexeert.</p>
</div>
Je kunt ook slechts één alinea of een deel van een element overslaan:
<div>
<h2>Mijn inhoud</h2>
<p>Deze alinea moet worden geïndexeerd.</p>
<p class="flowhunt-skip">Ik wil niet dat de chatbot deze informatie gebruikt.</p>
<p>Deze alinea moet worden geïndexeerd.</p>
</div>
Het crawlingproces draait op de achtergrond en is gebaseerd op de door jou ingestelde schema’s. Alleen de HTML-pagina wordt gedownload. Afbeeldingen of media worden enkel als links opgeslagen. Eventuele redirects worden gevolgd en canonieke URL’s worden geëvalueerd.
Na het crawlen wordt de HTML-inhoud omgezet naar gewone markdown-tekst. Sommige informatie kan tijdens dit proces worden verwijderd. De uiteindelijke markdown-tekst wordt aan de chatbot aangeboden als context. De bot kan deze informatie vervolgens ophalen wanneer dat nodig is.
De markdown-tekst wordt in stukken gesplitst, gevectoriseerd en opgeslagen in een vector database. Dit type database kent betekeniswaarden toe aan woorden. Daardoor kan AI gerelateerde woorden begrijpen zonder een exacte woordovereenkomst nodig te hebben.
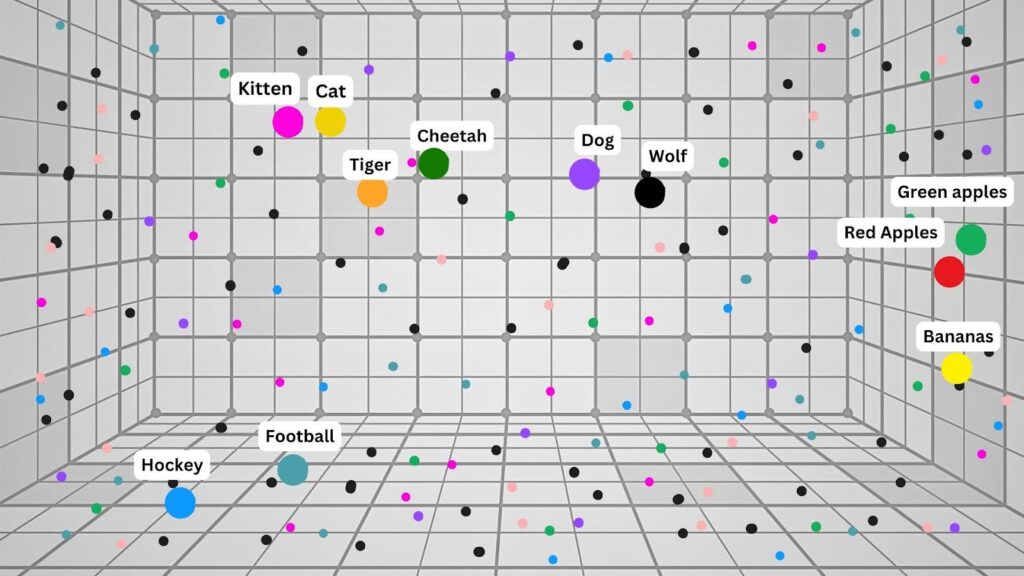
De woorden worden op een rooster geplaatst op basis van hun toegekende waarden. Hierdoor kan de computer begrijpen welke woorden qua betekenis dicht bij elkaar liggen:

Let op: dit is een sterk vereenvoudigd model. In de praktijk doet AI dit met duizenden woorden, zinnen en hele passages.
Het ophalen van informatie uit vector databases heet semantisch zoeken. Dat is het vermogen van AI om de betekenis van woorden in de vector database te zoeken en te beoordelen, en die te gebruiken om antwoorden te geven.
Wanneer een gebruiker een vraag stelt, zet de bot de woorden om in vectoren. Vervolgens doorzoekt hij de database op overeenkomsten uit je content. Wanneer er overeenkomsten of soortgelijke content wordt gevonden, gebruikt hij deze informatie om een antwoord te formuleren.
Stel je hebt een online dierenwinkel. Een klant stelt de volgende vraag:
“Verkopen jullie voer voor kittens?”
Dat doe je, maar de productnaam bevat het woord “junior” in plaats van “kitten”. De bot zal begrijpen dat “junior kattenvoer” hetzelfde (of heel vergelijkbaar) is als “voer voor kittens” en de klant succesvol naar het juiste product leiden.
Zonder semantisch zoeken in de vector database zou de chatbot simpelweg antwoorden dat je geen “voer voor kittens” hebt, waardoor je een toekomstige klant misloopt. Je hoeft je over dit soort situaties geen zorgen te maken als je FlowHunt gebruikt.
De indexering overslaan functie laat je specifieke inhoud uitsluiten van gebruik door je AI-chatbot. Door de flowhunt-skip class toe te voegen aan HTML-elementen, zorg je ervoor dat ongeschikte of herhalende inhoud niet wordt geïndexeerd of gebruikt in chatbot-antwoorden.
Door herhalende, ongepaste of mogelijk misleidende inhoud over te slaan, kan je AI-chatbot meer relevante, veilige en nauwkeurige antwoorden geven. Het verbetert ook de prestaties en vermindert onnodige verwerkingskosten.
Voeg de flowhunt-skip class toe aan elk HTML-element dat je niet wilt laten indexeren. FlowHunt negeert deze elementen tijdens het crawlen, waardoor ze niet in de kennisbank van je chatbot terechtkomen.
FlowHunt crawlt je site, zet HTML om naar markdown, splitst tekst in stukken en slaat deze op in een vector database. Dit maakt semantisch zoeken mogelijk, zodat de AI gerelateerde woorden begrijpt en relevante antwoorden kan geven op gebruikersvragen.
Semantisch zoeken gebruikt vector databases om woordbetekenissen en -relaties te begrijpen, niet alleen exacte overeenkomsten. Hierdoor kan je chatbot slimmere, contextuele antwoorden geven, zelfs als gebruikers andere bewoordingen gebruiken.
Slimme chatbots en AI-tools onder één dak. Verbind intuïtieve blokken om je ideeën om te zetten in geautomatiseerde Flows.
Een praktische gids voor het vertalen van content tussen talen terwijl stijl, toon en structuur behouden blijven — en hoe je vertalingen kunt reverse-engineeren...
Wat zijn hallucinaties in AI, waarom gebeuren ze en hoe kun je ze vermijden? Leer hoe je AI-chatbot-antwoorden accuraat houdt met praktische, mensgerichte strat...
Geef je HubSpot-chatbot meer kracht met FlowHunt. Krijg betere controle over antwoorden, databronnen en gespreksstromen.

