Insight Engine
Ontdek wat een Insight Engine is—een geavanceerd, AI-gedreven platform dat het zoeken en analyseren van data verbetert door context en intentie te begrijpen. Le...
10 min lezen
AI
Insight Engine
+5

AI Zoeken maakt gebruik van machine learning en vector-embeddings om zoekintentie en context te begrijpen, en levert uiterst relevante resultaten buiten exacte trefwoordovereenkomsten.
AI Zoeken gebruikt machine learning om de context en intentie van zoekopdrachten te begrijpen en zet deze om in numerieke vectoren voor nauwkeurigere resultaten. In tegenstelling tot traditionele zoekopdrachten op trefwoord interpreteert AI Zoeken semantische relaties, waardoor het effectief is voor diverse datatypes en talen.
AI Zoeken, vaak aangeduid als semantisch of vector zoeken, is een zoekmethode die machine learning-modellen gebruikt om de intentie en contextuele betekenis achter zoekopdrachten te begrijpen. In tegenstelling tot traditioneel zoeken op trefwoord zet AI zoeken data en queries om in numerieke representaties, bekend als vectoren of embeddings. Hierdoor kan de zoekmachine de semantische relaties tussen verschillende gegevensstukken begrijpen en relevantere en nauwkeurigere resultaten leveren, zelfs wanneer exacte trefwoorden niet aanwezig zijn.
AI Zoeken vertegenwoordigt een aanzienlijke evolutie in zoektechnologieën. Traditionele zoekmachines vertrouwen sterk op trefwoordovereenkomsten, waarbij de aanwezigheid van specifieke termen in zowel de query als documenten de relevantie bepaalt. AI Zoeken daarentegen maakt gebruik van machine learning-modellen om de onderliggende context en betekenis van zoekopdrachten en data te begrijpen.
Door tekst, afbeeldingen, audio en andere ongestructureerde data om te zetten naar hoog-dimensionale vectoren, kan AI Zoeken de gelijkenis tussen verschillende contentstukken meten. Deze aanpak stelt de zoekmachine in staat resultaten te leveren die contextueel relevant zijn, zelfs als ze niet exact dezelfde trefwoorden bevatten als de zoekopdracht.
Belangrijkste onderdelen:
De kern van AI Zoeken is het concept van vector-embeddings. Vector-embeddings zijn numerieke representaties van data die de semantische betekenis van tekst, afbeeldingen of andere datatypes vastleggen. Deze embeddings plaatsen vergelijkbare gegevensstukken dicht bij elkaar in een multi-dimensionale vectorruimte.
Hoe werkt het:
Voorbeeld:
Traditionele zoekmachines op trefwoord werken door termen in de zoekopdracht te matchen met documenten die deze termen bevatten. Ze vertrouwen op technieken zoals inverted indexes en term frequentie om resultaten te rangschikken.
Beperkingen van zoeken op trefwoord:
Voordelen van AI Zoeken:
| Aspect | Zoeken op trefwoord | AI Zoeken (Semantisch/Vector) |
|---|---|---|
| Matching | Exacte trefwoordinvulling | Semantische gelijkenis |
| Contextbewustzijn | Beperkt | Hoog |
| Omgaan met synoniemen | Handmatige synoniemenlijsten vereist | Automatisch via embeddings |
| Spelfouten | Kan falen zonder fuzzy search | Toleranter door semantische context |
| Begrip van intentie | Minimaal | Significant |
Semantisch Zoeken is een kernapplicatie van AI Zoeken die zich richt op het begrijpen van de gebruikersintentie en de contextuele betekenis van zoekopdrachten.
Proces:
Belangrijkste technieken:
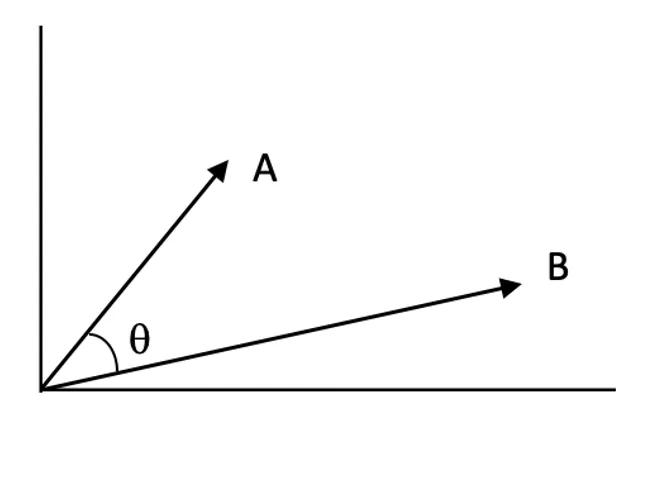
Gelijkenisscores:
Gelijkenisscores kwantificeren hoe nauw verwant twee vectoren zijn in de vectorruimte. Een hogere score betekent hogere relevantie tussen de zoekopdracht en een document.
Approximate Nearest Neighbor (ANN)-algoritmen:
Het vinden van exact de dichtstbijzijnde buren in hoog-dimensionale ruimtes is rekenintensief. ANN-algoritmen bieden efficiënte benaderingen.
AI Zoeken opent een breed scala aan toepassingen in verschillende sectoren door het vermogen om data te begrijpen en te interpreteren, verder dan simpele trefwoordinvulling.
Beschrijving: Semantisch Zoeken verbetert de gebruikerservaring door de intentie achter zoekopdrachten te interpreteren en contextueel relevante resultaten te bieden.
Voorbeelden:
Beschrijving: Door gebruikersvoorkeuren en gedrag te begrijpen kan AI Zoeken gepersonaliseerde content- of productaanbevelingen doen.
Voorbeelden:
Beschrijving: AI Zoeken stelt systemen in staat gebruikersvragen te begrijpen en met nauwkeurige informatie uit documenten te beantwoorden.
Voorbeelden:
Beschrijving: AI Zoeken kan ongestructureerde datatypes zoals afbeeldingen, audio en video indexeren en doorzoeken door ze om te zetten naar embeddings.
Voorbeelden:
Het integreren van AI Zoeken in AI-automatisering en chatbots verbetert hun mogelijkheden aanzienlijk.
Voordelen:
Stappen voor implementatie:
Voorbeeldtoepassing:
Hoewel AI Zoeken tal van voordelen biedt, zijn er ook uitdagingen:
Mitigatiestrategieën:
Semantisch en vector zoeken in AI zijn opkomende, krachtige alternatieven voor traditioneel zoeken op trefwoord en fuzzy zoeken, en verhogen de relevantie en nauwkeurigheid van zoekresultaten aanzienlijk door de context en betekenis achter zoekopdrachten te begrijpen.
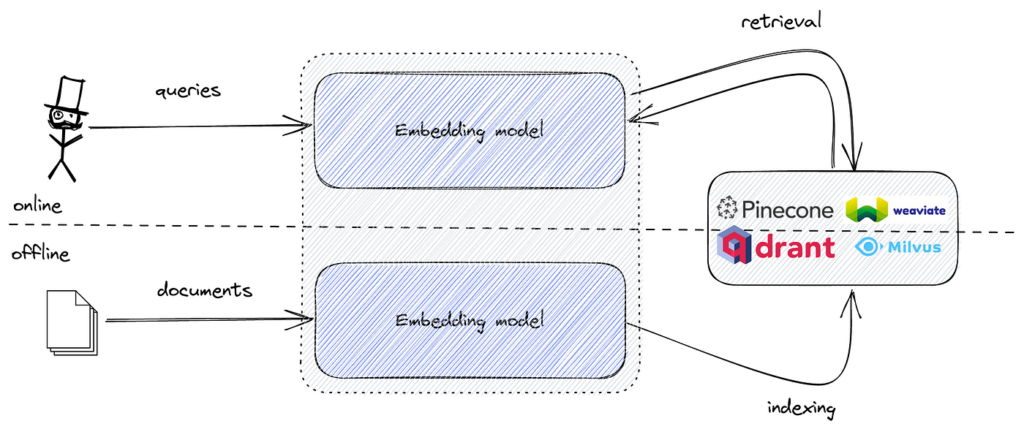
Bij het implementeren van semantisch zoeken wordt tekstuele data omgezet in vector-embeddings die de semantische betekenis van de tekst vastleggen. Deze embeddings zijn hoog-dimensionale numerieke representaties. Om efficiënt door deze embeddings te zoeken en de meest vergelijkbare aan een query-embedding te vinden, hebben we een tool nodig die is geoptimaliseerd voor similariteitszoektochten in hoog-dimensionale ruimtes.
FAISS biedt de benodigde algoritmen en datastructuren om deze taak efficiënt uit te voeren. Door semantische embeddings te combineren met FAISS kunnen we een krachtige semantische zoekmachine bouwen die grote datasets met lage latentie aankan.
Het implementeren van semantisch zoeken met FAISS in Python bestaat uit meerdere stappen:
Laten we elke stap in detail bekijken.
Bereid je dataset voor (bijvoorbeeld artikelen, supporttickets, productbeschrijvingen).
Voorbeeld:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Maak de tekstdata schoon en formatteer waar nodig.
Zet de tekstuele data om in vector-embeddings met behulp van voorgetrainde Transformer-modellen uit bijvoorbeeld Hugging Face (transformers of sentence-transformers).
Voorbeeld:
from sentence_transformers import SentenceTransformer
import numpy as np
# Laad een voorgetraind model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Genereer embeddings voor alle documenten
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32, vereist door FAISS.Maak een FAISS-index om de embeddings op te slaan en efficiënte similariteitszoektochten mogelijk te maken.
Voorbeeld:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 voert brute-force zoektochten uit met L2 (Euclidische) afstand.Zet de gebruikersquery om in een embedding en zoek de dichtstbijzijnde buren.
Voorbeeld:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Gebruik de indices om de meest relevante documenten te tonen.
Voorbeeld:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Verwachte output:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS biedt verschillende typen indexen:
Een Inverted File Index (IndexIVFFlat) gebruiken:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisatie en zoeken op inwendig product:
Het gebruik van cosinusgelijkenis kan effectiever zijn voor tekstdata
AI Zoeken is een moderne zoekmethode die gebruikmaakt van machine learning en vector-embeddings om de intentie en contextuele betekenis van zoekopdrachten te begrijpen, en levert nauwkeurigere en relevantere resultaten dan traditioneel zoeken op trefwoord.
In tegenstelling tot zoeken op trefwoord, dat vertrouwt op exacte overeenkomsten, interpreteert AI Zoeken de semantische relaties en intentie achter zoekopdrachten, waardoor het effectief is voor natuurlijke taal en vage invoer.
Vector-embeddings zijn numerieke representaties van tekst, afbeeldingen of andere datatypes die hun semantische betekenis vastleggen, zodat de zoekmachine gelijkenis en context tussen verschillende gegevensstukken kan meten.
AI Zoeken drijft semantisch zoeken in e-commerce, gepersonaliseerde aanbevelingen bij streaming, vraag- en antwoordsystemen in klantenondersteuning, browsen in ongestructureerde data en documentopzoeking in onderzoek en ondernemingen.
Populaire tools zijn onder andere FAISS voor efficiënte vectorsimilariteitszoektochten, en vectordatabases zoals Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch en Pgvector voor schaalbare opslag en opzoeking van embeddings.
Door AI Zoeken te integreren kunnen chatbots en automatiseringssystemen gebruikersvragen dieper begrijpen, contextueel relevante antwoorden ophalen en dynamische, gepersonaliseerde reacties geven.
Uitdagingen zijn onder andere hoge rekenbehoeften, complexiteit in modeluitlegbaarheid, behoefte aan hoogwaardige data en het waarborgen van privacy en beveiliging van gevoelige informatie.
FAISS is een open-source bibliotheek voor efficiënte similariteitszoektochten op hoog-dimensionale vector-embeddings, veelgebruikt om semantische zoekmachines te bouwen die grote datasets aankunnen.
Ontdek hoe door AI aangedreven semantisch zoeken jouw informatieopzoeking, chatbots en automatiseringsworkflows kan transformeren.
Ontdek wat een Insight Engine is—een geavanceerd, AI-gedreven platform dat het zoeken en analyseren van data verbetert door context en intentie te begrijpen. Le...
Gefacetteerd zoeken is een geavanceerde techniek waarmee gebruikers grote hoeveelheden data kunnen verfijnen en doorzoeken door meerdere filters toe te passen o...
Informatieopvraging maakt gebruik van AI, NLP en machine learning om gegevens efficiënt en nauwkeurig op te halen die voldoen aan de wensen van de gebruiker. Fu...