MLflow
MLflow is een open-source platform dat is ontworpen om de levenscyclus van machine learning (ML) te stroomlijnen en te beheren. Het biedt tools voor experimentt...
6 min lezen
MLflow
Machine Learning
+3
Kubeflow is een open-source ML-platform gebouwd op Kubernetes dat het uitrollen, beheren en opschalen van machine learning-workflows over diverse infrastructuren stroomlijnt.
De missie van Kubeflow is om het opschalen van ML-modellen en hun uitrol naar productie zo eenvoudig mogelijk te maken door gebruik te maken van de mogelijkheden van Kubernetes. Dit omvat eenvoudige, herhaalbare en draagbare deployments over diverse infrastructuren. Het platform begon als een methode om TensorFlow-taken op Kubernetes uit te voeren en is sindsdien geëvolueerd tot een veelzijdig framework dat een breed scala aan ML-frameworks en -tools ondersteunt.
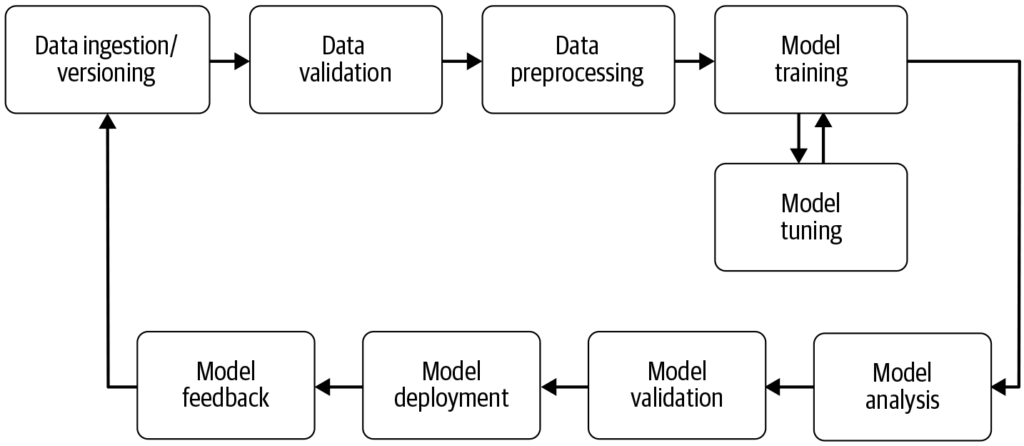
Kubeflow Pipelines is een kerncomponent waarmee gebruikers ML-workflows kunnen definiëren en uitvoeren als Directed Acyclic Graphs (DAGs). Het biedt een platform voor het bouwen van draagbare en schaalbare machine learning-workflows met Kubernetes. De Pipelines-component bestaat uit:
Deze functionaliteiten stellen data scientists in staat om het volledige proces van datapreprocessing, modeltraining, evaluatie en uitrol te automatiseren, waardoor reproduceerbaarheid en samenwerking in ML-projecten worden bevorderd. Het platform ondersteunt het hergebruiken van componenten en pipelines en stroomlijnt zo het creëren van ML-oplossingen.
Het Kubeflow Central Dashboard fungeert als de hoofdinterface voor toegang tot Kubeflow en zijn ecosysteem. Het bundelt de gebruikersinterfaces van verschillende tools en services binnen het cluster, en biedt een centrale toegang tot het beheer van machine learning-activiteiten. Het dashboard biedt functionaliteiten zoals gebruikersauthenticatie, multi-user isolatie en resourcebeheer.
Kubeflow integreert met Jupyter Notebooks en biedt zo een interactieve omgeving voor data-exploratie, experimentatie en modelontwikkeling. Notebooks ondersteunen verschillende programmeertalen en stellen gebruikers in staat om samen ML-workflows te creëren en uit te voeren.
Kubeflow Metadata is een gecentraliseerde opslagplaats voor het bijhouden en beheren van metadata die horen bij ML-experimenten, runs en artefacten. Het waarborgt reproduceerbaarheid, samenwerking en governance in ML-projecten door een consistent overzicht van ML-metadata te bieden.
Katib is een component voor geautomatiseerde machine learning (AutoML) binnen Kubeflow. Het ondersteunt hyperparameteroptimalisatie, early stopping en neural architecture search, en optimaliseert zo de prestaties van ML-modellen door het zoeken naar optimale hyperparameters te automatiseren.
Kubeflow wordt door organisaties in uiteenlopende sectoren gebruikt om hun ML-operaties te stroomlijnen. Veelvoorkomende use-cases zijn onder andere:
Spotify gebruikt Kubeflow om zijn data scientists en engineers te ondersteunen bij het ontwikkelen en uitrollen van machine learning-modellen op schaal. Door Kubeflow te integreren met hun bestaande infrastructuur, heeft Spotify zijn ML-workflows gestroomlijnd, de time-to-market van nieuwe features verkort en de efficiëntie van zijn aanbevelingssystemen verbeterd.
Kubeflow stelt organisaties in staat hun ML-workflows op of af te schalen en deze uit te rollen over verschillende infrastructuren, waaronder on-premises, cloud en hybride omgevingen. Deze flexibiliteit voorkomt vendor lock-in en maakt soepele overgangen tussen verschillende computingsomgevingen mogelijk.
De componentgebaseerde architectuur van Kubeflow maakt het eenvoudig om experimenten en modellen te reproduceren. Het biedt tools voor versiebeheer en het bijhouden van datasets, code en modelparameters, waardoor consistentie en samenwerking tussen data scientists wordt gegarandeerd.
Kubeflow is ontworpen om uitbreidbaar te zijn, zodat integratie met diverse andere tools en diensten mogelijk is, inclusief cloudgebaseerde ML-platforms. Organisaties kunnen Kubeflow aanpassen met extra componenten en bestaande tools en workflows benutten om hun ML-ecosysteem te versterken.
Door veel taken rond het uitrollen en beheren van ML-workflows te automatiseren, kunnen data scientists en engineers zich met Kubeflow richten op taken met meer toegevoegde waarde, zoals modelontwikkeling en optimalisatie, wat leidt tot productiviteits- en efficiëntiewinst.
De integratie van Kubeflow met Kubernetes zorgt voor efficiënter gebruik van resources, optimaliseert de toewijzing van hardware en verlaagt de kosten voor het uitvoeren van ML-workloads.
Om aan de slag te gaan met Kubeflow, kun je het uitrollen op een Kubernetes-cluster, zowel on-premises als in de cloud. Er zijn verschillende installatiehandleidingen beschikbaar, passend bij uiteenlopende ervaringsniveaus en infrastructuurbehoeften. Voor wie nieuw is met Kubernetes, bieden beheerde diensten zoals Vertex AI Pipelines een toegankelijke instap, waarbij het infrastructuurbeheer wordt overgenomen en gebruikers zich kunnen richten op het bouwen en uitvoeren van ML-workflows.
Deze uitgebreide verkenning van Kubeflow biedt inzicht in de functionaliteiten, voordelen en toepassingen ervan, en geeft organisaties een volledig beeld van de mogelijkheden om hun machine learning-capaciteiten te versterken.
Kubeflow is een open-source project dat is ontworpen om het uitrollen, orkestreren en beheren van machine learning-modellen op Kubernetes te vereenvoudigen. Het biedt een volledige end-to-end stack voor machine learning-workflows, waardoor het eenvoudiger wordt voor data scientists en engineers om schaalbare machine learning-modellen te bouwen, uit te rollen en te beheren.
Deployment of ML Models using Kubeflow on Different Cloud Providers
Auteurs: Aditya Pandey et al. (2022)
Dit paper onderzoekt het uitrollen van machine learning-modellen met Kubeflow op verschillende cloudplatforms. De studie geeft inzicht in het installatieproces, uitrolmodellen en prestatie-indicatoren van Kubeflow, en dient als nuttige gids voor beginners. De auteurs belichten de functies en beperkingen van de tool en demonstreren het gebruik bij het opzetten van end-to-end machine learning-pipelines. Het paper is bedoeld om gebruikers met minimale Kubernetes-ervaring te helpen Kubeflow te benutten voor modeluitrol.
Lees meer
CLAIMED, a visual and scalable component library for Trusted AI
Auteurs: Romeo Kienzler en Ivan Nesic (2021)
Dit werk richt zich op de integratie van vertrouwde AI-componenten met Kubeflow. Het behandelt onderwerpen als uitlegbaarheid, robuustheid en eerlijkheid van AI-modellen. Het paper introduceert CLAIMED, een herbruikbaar componentenframework dat tools zoals AI Explainability360 en AI Fairness360 integreert in Kubeflow-pipelines. Deze integratie vergemakkelijkt de ontwikkeling van productieklare machine learning-applicaties met visuele editors zoals ElyraAI.
Lees meer
Jet energy calibration with deep learning as a Kubeflow pipeline
Auteurs: Daniel Holmberg et al. (2023)
Kubeflow wordt gebruikt om een machine learning-pipeline op te zetten voor het kalibreren van jetenergiewaarnemingen bij het CMS-experiment. De auteurs gebruiken deep learning-modellen om de kalibratie van jetenergie te verbeteren en laten zien hoe Kubeflow’s mogelijkheden kunnen worden ingezet voor toepassingen in de deeltjesfysica. Het paper bespreekt de effectiviteit van de pipeline bij het opschalen van hyperparameteroptimalisatie en het efficiënt uitrollen van modellen op cloudresources.
Lees meer
Kubeflow is een open-source platform gebouwd op Kubernetes, ontworpen om het uitrollen, beheren en opschalen van machine learning-workflows te stroomlijnen. Het biedt een uitgebreide reeks tools voor de volledige ML-levenscyclus.
Belangrijke componenten zijn onder andere Kubeflow Pipelines voor workfloworkestratie, een centraal dashboard, integratie met Jupyter Notebooks, gedistribueerde modeltraining en -uitrol, metadata management en Katib voor hyperparameteroptimalisatie.
Door gebruik te maken van Kubernetes maakt Kubeflow schaalbare ML-workloads mogelijk in verschillende omgevingen en biedt het tools voor het bijhouden van experimenten en het hergebruiken van componenten, wat reproduceerbaarheid en efficiënte samenwerking garandeert.
Organisaties uit diverse sectoren gebruiken Kubeflow om hun ML-operaties te beheren en op te schalen. Bekende gebruikers zoals Spotify hebben Kubeflow geïntegreerd om modelontwikkeling en -uitrol te stroomlijnen.
Om te beginnen, installeer je Kubeflow op een Kubernetes-cluster, on-premises of in de cloud. Installatiehandleidingen en beheerde diensten zijn beschikbaar om gebruikers van elk ervaringsniveau te ondersteunen.
Ontdek hoe Kubeflow je machine learning-workflows op Kubernetes kan vereenvoudigen, van schaalbare training tot geautomatiseerde uitrol.
MLflow is een open-source platform dat is ontworpen om de levenscyclus van machine learning (ML) te stroomlijnen en te beheren. Het biedt tools voor experimentt...
Een machine learning-pijplijn is een geautomatiseerde workflow die het ontwikkelen, trainen, evalueren en uitrollen van machine learning-modellen stroomlijnt en...
Integreer FlowHunt met KubeSphere MCP Server om Kubernetes-resourcebeheer te automatiseren, clusteroperaties te stroomlijnen en DevOps-workflows te versterken m...