
MLflow
MLflow is een open-source platform dat is ontworpen om de levenscyclus van machine learning (ML) te stroomlijnen en te beheren. Het biedt tools voor experimentt...
6 min lezen
MLflow
Machine Learning
+3
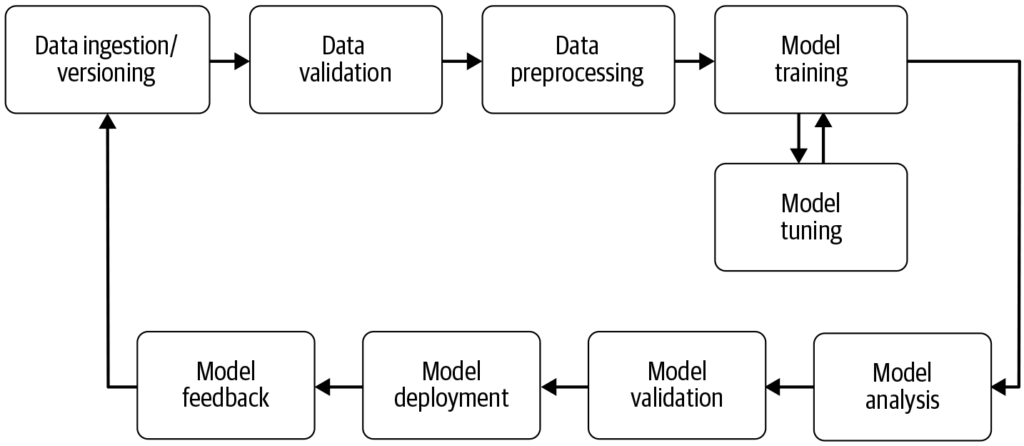
Een machine learning-pijplijn automatiseert de stappen van dataverzameling tot modeluitrol, waardoor efficiëntie, reproduceerbaarheid en schaalbaarheid in machine learning-projecten worden vergroot.
Een machine learning-pijplijn is een geautomatiseerde workflow die het ontwikkelen, trainen, evalueren en uitrollen van modellen stroomlijnt. Het verhoogt de efficiëntie, reproduceerbaarheid en schaalbaarheid en ondersteunt taken van dataverzameling tot modeluitrol en -onderhoud.
Een machine learning-pijplijn is een geautomatiseerde workflow die bestaat uit een reeks stappen die betrokken zijn bij het ontwikkelen, trainen, evalueren en uitrollen van machine learning-modellen. Het is ontworpen om de processen die nodig zijn om ruwe data via machine learning-algoritmen om te zetten in bruikbare inzichten, te stroomlijnen en standaardiseren. Het pijplijn-concept maakt efficiënte verwerking van data, modeltraining en uitrol mogelijk, waardoor het eenvoudiger wordt om machine learning-operaties te beheren en op te schalen.
Bron: Building Machine Learning
Dataverzameling: De eerste fase waarin data wordt verzameld uit verschillende bronnen zoals databases, API’s of bestanden. Dataverzameling is een systematische praktijk die gericht is op het verkrijgen van betekenisvolle informatie om een consistent en compleet dataset samen te stellen voor een specifiek zakelijk doel. Deze ruwe data is essentieel voor het bouwen van machine learning-modellen, maar vereist vaak preprocessing om bruikbaar te zijn. Zoals benadrukt door AltexSoft, omvat dataverzameling de systematische accumulatie van informatie ter ondersteuning van analyses en besluitvorming. Dit proces is van cruciaal belang omdat het de basis legt voor alle volgende stappen in de pijplijn en vaak continu is om ervoor te zorgen dat modellen getraind worden op relevante en actuele data.
Data Preprocessing: Ruwe data wordt opgeschoond en omgezet naar een geschikt formaat voor modeltraining. Veelvoorkomende preprocessing-stappen zijn het behandelen van ontbrekende waarden, het coderen van categorische variabelen, het schalen van numerieke kenmerken en het splitsen van de data in trainings- en testsets. Deze fase zorgt ervoor dat de data het juiste formaat heeft en vrij is van inconsistenties die de modelprestaties kunnen beïnvloeden.
Feature Engineering: Het creëren van nieuwe features of het selecteren van relevante features uit de data om het voorspellend vermogen van het model te verbeteren. Deze stap kan domeinspecifieke kennis en creativiteit vereisen. Feature engineering is een creatief proces waarbij ruwe data wordt omgezet in betekenisvolle kenmerken die het onderliggende probleem beter representeren en de prestaties van machine learning-modellen verhogen.
Modelselectie: Het juiste machine learning-algoritme wordt gekozen op basis van het probleemtype (bijvoorbeeld classificatie, regressie), data-eigenschappen en prestatie-eisen. Ook hyperparameter-tuning kan in deze stap plaatsvinden. Het kiezen van het juiste model is cruciaal, omdat het de nauwkeurigheid en efficiëntie van de voorspellingen bepaalt.
Modeltraining: Het gekozen model wordt getraind met behulp van de trainingsdataset. Dit omvat het leren van onderliggende patronen en relaties binnen de data. Ook kunnen voorgetrainde modellen gebruikt worden in plaats van een model vanaf nul te trainen. Training is een essentiële stap waarbij het model leert van de data om onderbouwde voorspellingen te doen.
Modelevaluatie: Na training wordt de prestatie van het model beoordeeld met behulp van een aparte testdataset of via cross-validatie. Evaluatiemaatstaven zijn afhankelijk van het specifieke probleem, maar kunnen onder andere nauwkeurigheid, precisie, recall, F1-score en mean squared error omvatten. Deze stap is essentieel om te waarborgen dat het model goed presteert op ongeziene data.
Modeluitrol: Zodra een bevredigend model is ontwikkeld en geëvalueerd, kan het in een productieomgeving worden uitgerold om voorspellingen te doen op nieuwe, ongeziene data. Uitrol kan het opzetten van API’s en integratie met andere systemen omvatten. Uitrol is de laatste fase waarin het model beschikbaar wordt gemaakt voor praktisch gebruik.
Monitoring en onderhoud: Na uitrol is het belangrijk om de prestaties van het model continu te monitoren en het indien nodig te hertrainen om in te spelen op veranderende dataprofielen. Zo blijft het model accuraat en betrouwbaar in de praktijk. Dit is een doorlopend proces om de relevantie en juistheid van het model te waarborgen.
Natural Language Processing vormt een brug tussen mens en computer. Ontdek vandaag de belangrijkste aspecten, werking en toepassingen! (NLP): NLP-taken bestaan vaak uit meerdere herhaalbare stappen zoals data-inname, tekstopschoning, tokenisatie en sentimentanalyse. Pijplijnen helpen deze stappen te modulariseren, zodat aanpassingen eenvoudig kunnen worden doorgevoerd zonder andere componenten te beïnvloeden.
Voorspellend onderhoud: In sectoren zoals de industrie kunnen pijplijnen worden ingezet om machine-uitval te voorspellen op basis van sensordata, waardoor proactief onderhoud mogelijk wordt en stilstand wordt verminderd.
Financiën: Pijplijnen kunnen het verwerken van financiële data automatiseren voor fraudedetectie, risicobeoordeling of het voorspellen van aandelenkoersen, wat de besluitvorming verbetert.
Zorg: In de gezondheidszorg kunnen pijplijnen medische beelden of patiëntendossiers verwerken om te ondersteunen bij diagnostiek of het voorspellen van behandelresultaten, wat leidt tot betere behandelstrategieën.
Machine learning-pijplijnen zijn onmisbaar voor AI en automatisering doordat ze een gestructureerd kader bieden om machine learning-taken te automatiseren. In het kader van AI-automatisering zorgen pijplijnen ervoor dat modellen efficiënt getraind en uitgerold worden, waardoor AI-systemen zoals [chatbots kunnen leren en zich aanpassen aan nieuwe data zonder handmatige tussenkomst. Deze automatisering is cruciaal om AI-toepassingen op te schalen en te zorgen voor consistente en betrouwbare prestaties over verschillende domeinen. Door het gebruik van pijplijnen kunnen organisaties hun AI-capaciteiten vergroten en ervoor zorgen dat hun machine learning-modellen relevant en effectief blijven in veranderende omgevingen.
Onderzoek naar machine learning-pijplijnen
“Deep Pipeline Embeddings for AutoML” van Sebastian Pineda Arango en Josif Grabocka (2023) richt zich op de uitdagingen bij het optimaliseren van machine learning-pijplijnen in Automated Machine Learning (AutoML). Dit artikel introduceert een nieuw neuraal architectuur die diepe interacties tussen pijplijncomponenten vastlegt. De auteurs stellen voor om pijplijnen in latente representaties te embedden via een unieke encoder per component. Deze embeddings worden gebruikt binnen een Bayesian Optimization-framework om optimale pijplijnen te vinden. Het artikel benadrukt het gebruik van meta-learning om de netwerkparameters voor pijplijnembedding te verfijnen en toont state-of-the-art resultaten in pijplijnoptimalisatie op meerdere datasets. Lees meer.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” van Tien-Dung Nguyen e.a. (2020) behandelt de tijdrovende evaluatie van machine learning-pijplijnen tijdens AutoML-processen. De studie bekritiseert traditionele methoden zoals Bayesian en genetische optimalisaties wegens hun inefficiëntie. Om dit te verhelpen, presenteren de auteurs AVATAR, een surrogate model dat pijplijnvaliditeit efficiënt beoordeelt zonder uitvoering. Deze aanpak versnelt de samenstelling en optimalisatie van complexe pijplijnen aanzienlijk door ongeldige pijplijnen vroegtijdig uit te filteren. Lees meer.
“Data Pricing in Machine Learning Pipelines” van Zicun Cong e.a. (2021) onderzoekt de cruciale rol van data in machine learning-pijplijnen en de noodzaak van dataprijsvorming om samenwerking tussen meerdere belanghebbenden te bevorderen. Het artikel biedt een overzicht van de nieuwste ontwikkelingen op het gebied van dataprijsvorming binnen machine learning, met nadruk op het belang ervan in verschillende fasen van de pijplijn. Het geeft inzicht in prijsstrategieën voor het verzamelen van trainingsdata, collaboratieve modeltraining en het leveren van machine learning-diensten, en belicht zo het ontstaan van een dynamisch ecosysteem. Lees meer.
Een machine learning-pijplijn is een geautomatiseerde reeks stappen – van dataverzameling en preprocessing tot modeltraining, evaluatie en uitrol – die het proces van het bouwen en onderhouden van machine learning-modellen stroomlijnt en standaardiseert.
Belangrijke componenten zijn dataverzameling, data preprocessing, feature engineering, modelselectie, modeltraining, modelevaluatie, modeluitrol en voortdurende monitoring en onderhoud.
Machine learning-pijplijnen bieden modularisatie, efficiëntie, reproduceerbaarheid, schaalbaarheid, verbeterde samenwerking en eenvoudiger uitrollen van modellen naar productieomgevingen.
Toepassingen zijn onder meer natuurlijke taalverwerking (NLP), voorspellend onderhoud in de industrie, financiële risicoanalyse en fraudedetectie, en medische diagnostiek.
Uitdagingen zijn onder andere het waarborgen van datakwaliteit, het beheersen van de complexiteit van de pijplijn, integratie met bestaande systemen en het beheersen van kosten gerelateerd aan rekencapaciteit en infrastructuur.
Plan een demo om te ontdekken hoe FlowHunt jou kan helpen je machine learning-workflows eenvoudig te automatiseren en op te schalen.
MLflow is een open-source platform dat is ontworpen om de levenscyclus van machine learning (ML) te stroomlijnen en te beheren. Het biedt tools voor experimentt...
Machine Learning (ML) is een subset van kunstmatige intelligentie (AI) die machines in staat stelt te leren van data, patronen te herkennen, voorspellingen te d...
Kubeflow is een open-source machine learning (ML) platform op Kubernetes, dat het uitrollen, beheren en opschalen van ML-workflows vereenvoudigt. Het biedt een ...
