

FlowHunt 2.4.1 bringer Claude, Grok, Llama og mer
FlowHunt 2.4.1 introduserer store nye AI-modeller inkludert Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, og utvider dine muligheter for eksperime...
2 min lesing
AI
LLM
+7

AI-drevet datauttrekk automatiserer databehandling, reduserer feil og håndterer store datasett effektivt. Lær om de beste verktøyene, metodene og fremtidige trender.
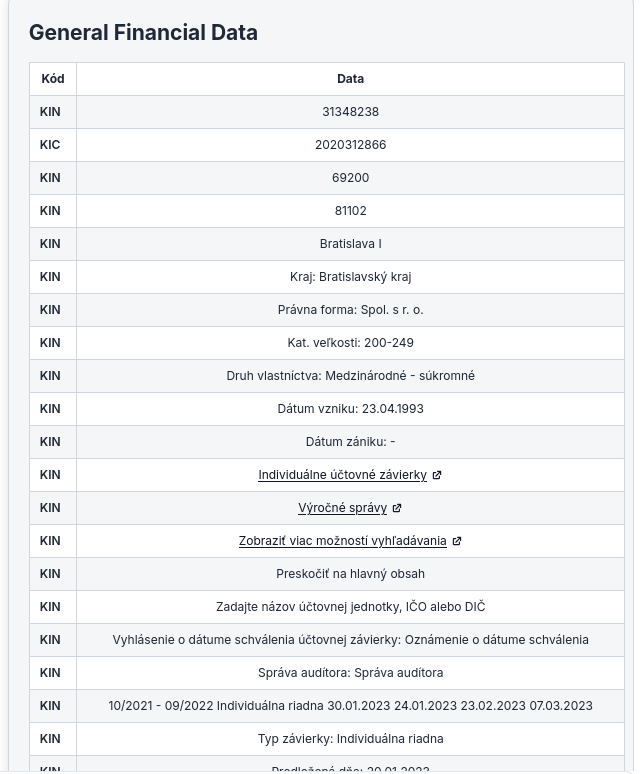
Dette er modellene vi har prøvd for å hente ut data fra en nettside i HTML. Nedenfor utforsker vi ytelsen til flere modeller vi har testet for å hente ut spesifikke data i strukturerte formater som markdown-tabeller fra HTML-sider.
Dette er prompten vi brukte for å evaluere ulike modeller, og vi hentet ustrukturert data fra HTML og viste det som Markdown-tabell.
Denne modellen, selv om den er innovativ i sin arkitektur, viste begrensninger når det gjaldt å følge promptene strengt for datauttrekk. I vår oppgave hentet modellen ut all data, og ikke bare de spesifiserte dataene i prompten.
Haiku-modellen fra Anthropic AI utmerket seg i vår evaluering. Den viste en robust evne til ikke bare å forstå prompten, men også å utføre uttrekksoppgaven med høy presisjon. Den var svært dyktig til å tolke HTML-innhold og formatere de uttrukne dataene i velstrukturerte markdown-tabeller. Modellens evne til å opprettholde kontekst og følge detaljerte instrukser gjorde den særlig effektiv for dette bruksområdet.
Selv om Haiku-modellen er den minste modellen til Anthropic, gjorde den en bedre jobb enn noen annen modell i testen.
Selv om OpenAI-modeller er kjent for sin allsidighet og språkforståelse, utmerket de seg ikke like mye i vår spesifikke oppgave med å konvertere HTML til markdown-tabeller. Hovedproblemet vi støtte på var formateringen av markdown-tabellen. Modellen produserte tidvis tabeller med feiljusterte kolonner eller inkonsekvent markdown-syntaks, noe som krevde manuell justering etter uttrekket. Det var mange plassholdere i det genererte OpenAI-innholdet.
Metoder for datauttrekk er avgjørende for virksomheter som ønsker å utnytte sine data best mulig. Disse metodene varierer i kompleksitet og er tilpasset ulike datatyper og forretningsbehov.
Webskraping er en populær måte å samle inn data direkte fra nettsider. Det innebærer bruk av automatiserte verktøy eller skript for å samle store mengder data fra nettsider. Denne metoden er spesielt nyttig for å samle offentlig informasjon som priser, produktdetaljer eller kundeanmeldelser. Verktøy som BeautifulSoup og Cheerio er godt kjent for å skrape innhold fra statiske nettsider. I tillegg kan AI-drevne skrapeverktøy automatisere og forbedre prosessen, og spare tid og innsats.
Tekstuttrekk handler om å hente ut spesifikk informasjon fra kilder som hovedsakelig består av tekst. Denne metoden er viktig for å jobbe med dokumenter, e-poster og andre teksttunge formater. Avanserte tekstuttrekksteknikker kan finne og hente ut mønstre eller enheter, som navn, datoer og finansielle tall fra ustrukturert tekst. Ofte støttes denne prosessen av maskinlæringsmodeller som blir mer nøyaktige og effektive over tid.
API-verktøy gjør datauttrekk enklere ved å tilby en strukturert måte å få tilgang til data fra eksterne kilder. Gjennom API-er kan virksomheter hente data fra ulike tjenester som sosiale medieplattformer, databaser og skyløsninger på en sikker og effektiv måte. Denne tilnærmingen er ideell for å integrere sanntidsdata i forretningsapplikasjoner, og sikrer en jevn dataflyt og oppdatert informasjon.
Datamining handler om å analysere store datasett for å avdekke mønstre, korrelasjoner og innsikter som ikke er umiddelbart åpenbare. Denne metoden er uvurderlig for virksomheter som ønsker å optimalisere prosesser, forutsi trender eller forstå kundeadferd bedre. Datamining-teknikker kan brukes på både strukturerte og ustrukturerte data, noe som gjør dem til allsidige verktøy for strategisk beslutningstaking.
OCR-teknologi konverterer skrevet tekst, som håndskrevne notater eller trykte dokumenter, til digitale data som kan redigeres og søkes i. Denne metoden er spesielt nyttig for å gjøre papirbasert informasjon digital, og hjelper virksomheter med å effektivisere dokumenthåndtering og forbedre datatilgang. OCR-motorer har blitt mer avanserte og tilbyr høy nøyaktighet og hastighet ved konvertering av fysiske dokumenter til digitale formater.
Å legge til disse metodene for datauttrekk i en virksomhetsplan kan betydelig øke databehandlingskapasiteten, noe som gir bedre beslutningstaking og forbedret operasjonell effektivitet. Ved å velge riktig metode eller kombinasjon av metoder, kan virksomheter sikre at de utnytter dataene sine best mulig.
Docsumo er et dokumentbehandlings- og datauttrekksverktøy utviklet for å automatisere dataregistreringsprosessen ved å hente ut informasjon fra ulike typer dokumenter. Ved å bruke intelligent OCR-teknologi reduserer det vesentlig tiden og innsatsen som kreves for manuell dataregistrering, noe som gjør det til et verdifullt verktøy på tvers av bransjer som finans, helse og forsikring.
Fordeler:
Ulemper:
Målgruppe: Ideelle brukere for Docsumo inkluderer:
Anbefalinger:
Vi anbefaler Docsumo til virksomheter som håndterer store mengder dokumenter og har behov for pålitelige datauttrekksmuligheter. Automatiseringsfunksjonene øker effektiviteten og nøyaktigheten, og gjør det til et uunnværlig verktøy for flere sektorer.
Hevo Data er en omfattende dataintegrasjonsplattform som gjør det mulig for virksomheter å samle og integrere data fra flere kilder i én samlet visning. Plattformen er utviklet med et brukervennlig grensesnitt, slik at brukere kan sette opp datapipelines uten behov for programmeringskunnskaper. Denne tilgjengeligheten gjør det til en ideell løsning for bedrifter som ønsker å utnytte dataene sine til analyse og rapportering. Hevo Data støtter ulike datakilder, inkludert databaser, skylagring og SaaS-applikasjoner, og gjør det mulig for organisasjoner å effektivisere dataarbeidsflyten og forbedre beslutningsprosessene.
Hevo Data har fått positive tilbakemeldinger fra brukere for brukervennlighet, sanntidsmuligheter og solide integrasjonsfunksjoner. Mange setter pris på plattformens kodefrie tilnærming, som gjør at team raskt kan sette opp pipelines uten omfattende teknisk kompetanse. Sanntidsdatareplikering har også blitt trukket frem som et betydelig fortrinn for virksomheter som er avhengige av oppdatert informasjon for beslutningstaking. Noen brukere nevner likevel en viss læringskurve når det gjelder mer avanserte funksjoner.
Hevo Data anbefales spesielt for små og mellomstore bedrifter som ønsker å effektivisere dataintegrasjonsprosessene uten store tekniske ressurser. Den passer særlig for team som trenger sanntidsdataanalyse og rapporteringsmuligheter. Virksomheter innen e-handel, finans og markedsføring kan ha stor nytte av å bruke Hevo Data til å konsolidere data for bedre beslutningstaking. Alt i alt er Hevo Data et utmerket valg for organisasjoner som ønsker en pålitelig og brukervennlig dataintegrasjonsløsning.
Airbyte er en åpen kildekode dataintegrasjonsplattform utviklet for å hjelpe virksomheter med å synkronisere data på tvers av ulike systemer effektivt. Den legger til rette for bygging av ELT (Extract, Load, Transform)-datapipelines som kobler forskjellige kilder og destinasjoner, og muliggjør sømløs dataoverføring og rapportering. Grunnlagt i januar 2020 har Airbyte som mål å forenkle dataintegrasjon ved å tilby et kodefritt verktøy som lar brukere koble sammen ulike systemer uten store tekniske ressurser. Med over 400 tilgjengelige connectorer har Airbyte raskt fått fotfeste i markedet og hentet inn betydelig finansiering siden oppstarten.
Positive tilbakemeldinger:
Brukere setter pris på brukervennlighet, omfattende integrasjoner, åpen kildekode og kundestøtte. Mange synes plattformen er enkel å bruke, og muliggjør rask oppsett av datapipelines.
Kritikk:
Noen brukere rapporterer om ytelsesproblemer med store datamengder og ønsker bedre dokumentasjon. Andre mener at mens plattformen er effektiv for enkel integrasjon, mangler den avanserte funksjoner.
Airbyte passer spesielt for:
Oppsummert er Airbyte en robust løsning for et bredt spekter av brukere som ønsker å styrke sine dataintegrasjonsprosesser. Dens åpen kildekode-modell, omfattende funksjoner og sterke brukermiljø gjør den til et attraktivt valg for virksomheter som vil utnytte data effektivt.
Import.io er en webdataintegrasjonsplattform som gjør det mulig for brukere å hente ut, transformere og laste data fra nettet til brukbare formater. Produktet er utviklet for å hjelpe virksomheter med å samle inn data fra ulike nettbaserte kilder for analyse og beslutningsstøtte. Import.io leverer en SaaS-løsning som konverterer komplekse webdata til strukturerte formater som JSON, CSV eller Google Sheets. Denne funksjonaliteten er avgjørende for virksomheter som er avhengige av data til konkurranseanalyse, markedsanalyse og strategisk planlegging. Plattformen er bygget for å håndtere utfordringer knyttet til webdatauttrekk, inkludert håndtering av CAPTCHA, innlogginger og varierende nettside-strukturer.
Positive omtaler:
Negative omtaler:
Import.io er et utmerket valg for markedsføringsteam, e-handelsbedrifter, dataanalytikere og forskere som ønsker å effektivisere datainnsamlingen uten omfattende teknisk kompetanse. Det brukervennlige grensesnittet og de solide funksjonene gjør det egnet til en rekke bruksområder, fra konkurranseanalyse til markedsundersøkelser og overvåking av sosiale medier. Import.io utmerker seg ved å tilby tilgjengelige og nyttige webdata, samtidig som det sparer tid og reduserer driftskostnader.
Denne omfattende rapporten gir potensielle brukere all nødvendig informasjon for å vurdere Import.io som løsning for deres behov innen webbasert datauttrekk.
Fremover vil datauttrekk endres mye på grunn av nye trender. Modeller som bruker AI leder an, og forbedrer nøyaktighet og effektivitet gjennom maskinlæring. Det kommer også noe som kalles edge-analyse, som lar data behandles der de skapes, og reduserer forsinkelser og mengden data som må overføres. En annen stor trend er å gjøre data mer tilgjengelige, hvor AI bidrar til å bryte ned barrierer slik at flere i en organisasjon får tilgang til viktige innsikter. I tillegg er det økende fokus på etiske datapraksiser, slik at datauttrekk skjer på en åpen måte og med respekt for personvern. Etter hvert som disse trendene utvikler seg, blir det viktig å holde seg oppdatert og fleksibel for å bruke datauttrekk som et strategisk fortrinn.
AI-drevet datauttrekk øker effektiviteten ved å automatisere databehandling, reduserer manuelle feil og kan håndtere store datasett, slik at bedrifter kan bruke ressursene på mer strategiske oppgaver.
Ledende modeller inkluderer Anthropic AI sin Haiku, som utmerker seg i strukturert uttrekk fra HTML, samt modeller fra OpenAI og Llama 3.2, selv om Anthropics modell viste best etterlevelse av strukturerte uttrekksinstruksjoner.
Vanlige metoder inkluderer webskraping, tekstuttrekk, API-integrasjon, datamining og OCR (Optical Character Recognition), hver tilpasset spesifikke datatyper og behov.
Toppverktøy inkluderer Docsumo for dokumentbehandling med OCR, Hevo Data og Airbyte for kodefri dataintegrasjon, og Import.io for webdatauttrekk og transformasjon.
Viktige trender inkluderer økt bruk av AI og maskinlæring for bedre presisjon, edge-analyse for raskere prosessering, større datatilgjengelighet på tvers av organisasjoner, og økt fokus på etiske og personvernvennlige datapraksiser.
Smarte chatboter og AI-verktøy under ett tak. Koble sammen intuitive blokker for å gjøre ideene dine om til automatiserte Flows.
FlowHunt 2.4.1 introduserer store nye AI-modeller inkludert Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, og utvider dine muligheter for eksperime...
Utforsk de avanserte egenskapene til Llama 3.2 1B AI-agenten. Dette dypdykket viser hvordan den går utover tekstgenerering, og fremhever dens resonnering, probl...
Utforsk de beste store språkmodellene (LLM-er) for koding i juni 2025. Denne komplette, pedagogiske guiden gir innsikt, sammenligninger og praktiske tips for st...

