

FlowHunt 2.4.1 bringer Claude, Grok, Llama og mer
FlowHunt 2.4.1 introduserer store nye AI-modeller inkludert Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, og utvider dine muligheter for eksperime...
2 min lesing
AI
LLM
+7

FlowHunts nye åpen kildekode CLI-verktøykasse muliggjør omfattende flytvurdering med LLM som dommer, og gir detaljert rapportering og automatisert kvalitetsvurdering for AI-arbeidsflyter.
Vi er glade for å kunngjøre lanseringen av FlowHunt CLI-verktøykassen – vårt nye åpen kildekode kommandolinjeverktøy designet for å revolusjonere hvordan utviklere vurderer og tester AI-flyter. Dette kraftige verktøyet gir vurderingsmuligheter på bedriftsnivå til åpen kildekode-samfunnet, komplett med avansert rapportering og vår innovative “LLM som dommer”-implementering.
FlowHunt CLI-verktøykassen representerer et betydelig steg videre innen testing og vurdering av AI-arbeidsflyter. Tilgjengelig nå på GitHub, gir denne åpen kildekode-verktøykassen utviklere omfattende verktøy for:
Verktøykassen gjenspeiler vårt engasjement for åpenhet og fellesskapsdrevet utvikling, og gjør avanserte AI-vurderingsteknikker tilgjengelige for utviklere over hele verden.
En av de mest innovative funksjonene i vår CLI-verktøykasse er implementeringen av “LLM som dommer”. Denne tilnærmingen bruker kunstig intelligens til å vurdere kvaliteten og riktigheten i AI-genererte svar – i praksis lar vi AI vurdere AI-ytelse med sofistikerte resonneringsmuligheter.
Det som gjør vår implementering unik er at vi brukte FlowHunt selv til å lage vurderingsflyten. Denne meta-tilnærmingen demonstrerer kraften og fleksibiliteten i plattformen vår, samtidig som det gir et robust vurderingssystem. LLM som dommer-flyten består av flere sammenkoblede komponenter:
1. Promptmal: Utformer vurderingsprompten med spesifikke kriterier
2. Strukturert utgangsgenerator: Behandler vurderingen ved hjelp av en LLM
3. Dataparsing: Formaterer den strukturerte utgangen for rapportering
4. Chat-utgang: Presenterer de endelige vurderingsresultatene
Kjernen i vårt LLM som dommer-system er en nøye utformet prompt som sikrer konsistente og pålitelige vurderinger. Her er den sentrale promptmalen vi bruker:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
Denne prompten sikrer at vår LLM-dommer gir:
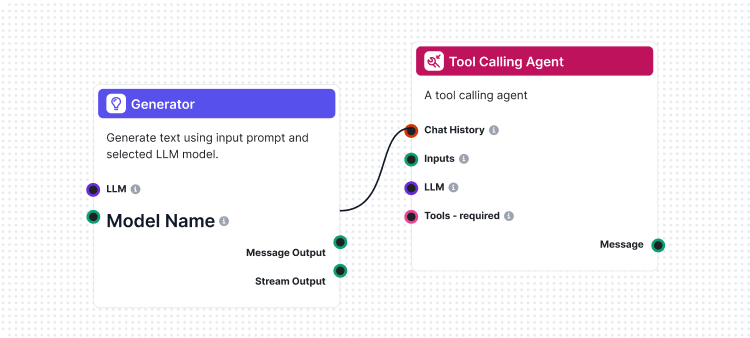
Vår LLM som dommer-flyt viser sofistikert AI-arbeidsflytdesign ved bruk av FlowHunts visuelle flytbygger. Slik fungerer komponentene sammen:
Flyten starter med en Chat Input-komponent som mottar vurderingsforespørselen med både faktisk svar og referansesvar.
Prompt Template-komponenten konstruerer vurderingsprompten dynamisk ved å:
{target_response}-plassholderen{actual_response}-plassholderenStructured Output Generator behandler prompten ved hjelp av en valgt LLM og genererer strukturert utgang som inneholder:
total_rating: Numerisk poeng fra 1-4correctness: Binær riktig/feil-klassifiseringreasoning: Detaljert forklaring av vurderingenParse Data-komponenten formaterer den strukturerte utgangen til lesbart format, og Chat Output-komponenten presenterer det endelige vurderingsresultatet.
LLM som dommer-systemet gir flere avanserte muligheter som gjør det spesielt effektivt for AI-flytvurdering:
I motsetning til enkel strengsammenligning forstår vår LLM-dommer:
Den fireskala vurderingen gir granulær evaluering:
Hver vurdering inkluderer detaljert begrunnelse, som gjør det mulig å:
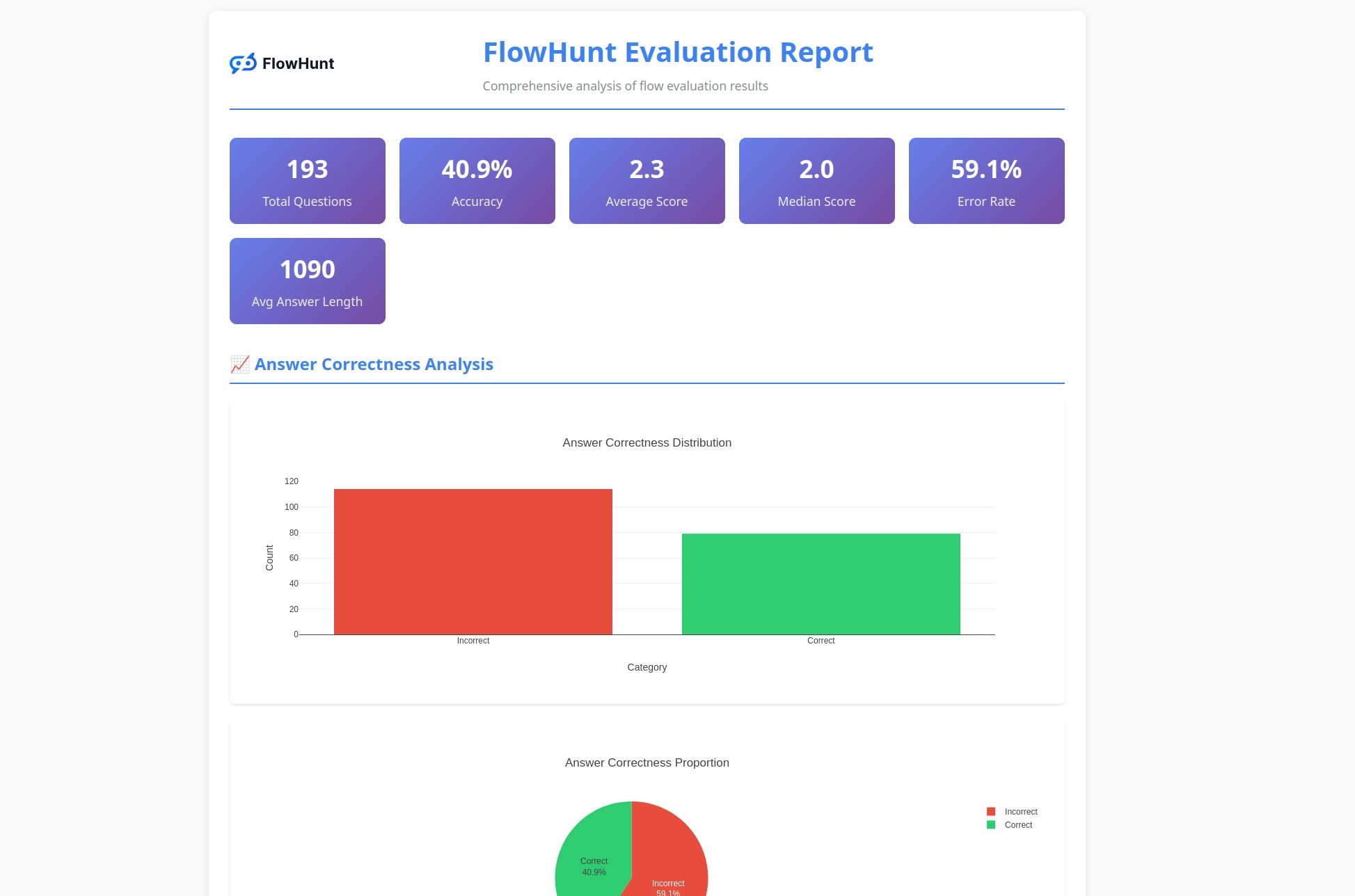
CLI-verktøykassen genererer detaljerte rapporter som gir handlingsrettet innsikt i flytens ytelse:
Klar til å begynne å evaluere AI-flytene dine med profesjonelle verktøy? Slik kommer du i gang:
Én-linjers installasjon (anbefalt) for macOS og Linux:
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
Dette vil automatisk:
flowhunt-kommandoen i din PATHManuell installasjon:
# Klone depotet
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# Installer med pip
pip install -e .
Verifiser installasjonen:
flowhunt --help
flowhunt --version
1. Autentisering
Autentiser deg først med din FlowHunt API:
flowhunt auth
2. List dine flyter
flowhunt flows list
3. Vurder en flyt Lag en CSV-fil med dine testdata:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
Kjør evaluering med LLM som dommer:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. Batch-kjør flyter
flowhunt batch-run your-flow-id input.csv --output-dir results/
Evalueringssystemet gir omfattende analyse:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
Funksjoner inkluderer:
CLI-verktøykassen integreres sømløst med FlowHunt-plattformen, slik at du kan:
Lanseringen av vår CLI-verktøykasse representerer mer enn bare et nytt verktøy – det er en visjon for fremtiden innen AI-utvikling hvor:
Kvalitet er målbar: Avanserte vurderingsteknikker gjør AI-ytelse kvantifiserbar og sammenlignbar.
Testing er automatisert: Omfattende testrammeverk reduserer manuelt arbeid og øker pålitelighet.
Åpenhet er standard: Detaljert begrunnelse og rapportering gjør AI-adferd forståelig og feilsøkbar.
Fellesskapet driver innovasjon: Åpen kildekode-verktøy muliggjør samarbeid og kunnskapsdeling.
Ved å gjøre FlowHunt CLI-verktøykassen åpen kildekode viser vi vårt engasjement for:
FlowHunt CLI-verktøykassen med LLM som dommer representerer et betydelig fremskritt innen AI-flytvurdering. Ved å kombinere sofistikert vurderingslogikk med omfattende rapportering og åpen kildekode-tilgjengelighet gir vi utviklere mulighet til å bygge bedre og mer pålitelige AI-systemer.
Meta-tilnærmingen med å bruke FlowHunt til å vurdere FlowHunt-flyter viser modenheten og fleksibiliteten til plattformen vår, samtidig som det gir et kraftig verktøy for det bredere AI-utviklingsmiljøet.
Enten du bygger enkle chatbots eller komplekse multiagent-systemer, gir FlowHunt CLI-verktøykassen den vurderingsinfrastrukturen du trenger for å sikre kvalitet, pålitelighet og kontinuerlig forbedring.
Klar til å løfte din AI-flytvurdering? Besøk vårt GitHub-repositorium for å komme i gang med FlowHunt CLI-verktøykassen i dag, og opplev kraften av LLM som dommer selv.
Fremtiden for AI-utvikling er her – og den er åpen kildekode.
FlowHunt CLI-verktøykassen er et åpen kildekode kommandolinjeverktøy for vurdering av AI-flyter med omfattende rapporteringsmuligheter. Den inkluderer funksjoner som LLM som dommer-vurdering, analyse av riktige/feilaktige resultater og detaljerte ytelsesmetrikker.
LLM som dommer bruker en sofistikert AI-flyt bygget i FlowHunt for å evaluere andre flyter. Den sammenligner faktiske svar mot referansesvar, gir vurderinger, riktighetsvurderinger og detaljert begrunnelse for hver evaluering.
FlowHunt CLI-verktøykassen er åpen kildekode og tilgjengelig på GitHub på https://github.com/yasha-dev1/flowhunt-toolkit. Du kan klone, bidra og bruke den fritt for dine AI-flytvurderingsbehov.
Verktøykassen genererer omfattende rapporter inkludert oversikt over riktige/feilaktige resultater, LLM som dommer-evalueringer med vurderinger og begrunnelser, ytelsesmetrikker og detaljert analyse av flytadferd på tvers av ulike testtilfeller.
Ja! LLM som dommer-flyten er bygget med FlowHunts plattform og kan tilpasses ulike vurderingsscenarier. Du kan endre promptmalen og vurderingskriteriene for å passe dine spesifikke bruksområder.
Yasha er en dyktig programvareutvikler som spesialiserer seg på Python, Java og maskinlæring. Yasha skriver tekniske artikler om AI, prompt engineering og utvikling av chatboter.
Bygg og vurder sofistikerte AI-arbeidsflyter med FlowHunts plattform. Begynn å lage flyter som kan vurdere andre flyter i dag.
FlowHunt 2.4.1 introduserer store nye AI-modeller inkludert Claude, Grok, Llama, Mistral, DALL-E 3 og Stable Diffusion, og utvider dine muligheter for eksperime...
Flyter er hjernen bak alt i FlowHunt. Lær hvordan du bygger dem med en visuell no-code-bygger, fra å plassere den første komponenten til nettsideintegrasjon, ut...
Integrer FlowHunt med MCP Discovery for å automatisere introspeksjon av MCP Server, generere dokumentasjon i flere formater, og effektivisere CI/CD-arbeidsflyte...