GPT-4.1 Nano: Ytelsesanalyse på tvers av fem nøkkeloppgaver
En omfattende analyse av OpenAI’s GPT-4.1 Nano, hvor dens styrker, begrensninger og hastighet vurderes på fem nøkkeloppgaver, inkludert innholdsgenerering, beregninger, oppsummering, sammenligning og kreativ skriving.
GPT-4.1 Nano
AI Models
Performance Analysis
OpenAI
Artificial Intelligence
Da GPT-4.1 Nano ble bedt om å lage omfattende innhold om grunnleggende prosjektledelse, brukte den en imponerende iterativ forskningsmetodikk.
Forskningsmetode
Modellen demonstrerte en sofistikert informasjonsinnhentingsstrategi:
Flere søkeiterasjoner: Utførte flere Google-søk og raffinerte søkene for å finne autoritative kilder
Tydelig forskningshensikt: Utrykte gjentatte ganger målet om å finne “anerkjent”, “omfattende” og “høykvalitets” informasjon
Verktøybruk: Vekslet effektivt mellom google_serper for søk og url_crawl_tool for innholdsekstraksjon
Tilpasning til oppgaven
Da omfanget ble utvidet fra kun “definere målsettinger” til også å inkludere prosjektomfang og delegering, tilpasset modellen seg sømløst og hentet inn ytterligere informasjon for hver nye del uten å miste fokus.
Kvalitet på utdata
Den endelige artikkelen (815 ord) var godt strukturert med:
Klare seksjonsoverskrifter og logisk organisering
Detaljerte forklaringer av SMART-mål, steg for omfangsdefinisjon og beste praksis for delegering
Profesjonelt språk med Flesch-Kincaid-nivå 12, passende for forretningsinnhold
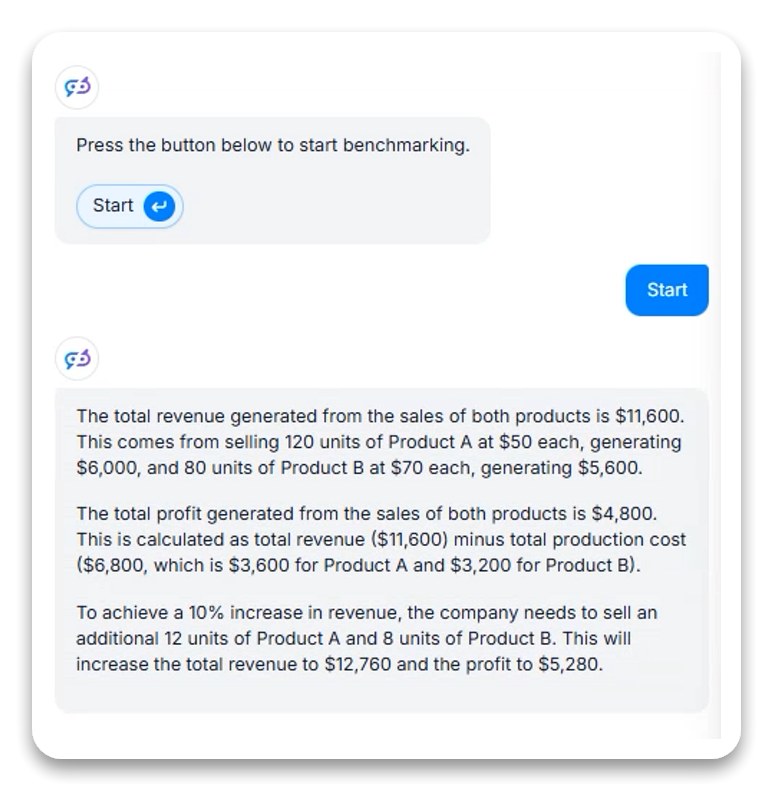
Oppgave 2: Beregning – Analyse av omsetning og fortjeneste i virksomhet
På denne kvantitative oppgaven demonstrerte GPT-4.1 Nano sterke matematiske ferdigheter uten behov for eksterne verktøy.
Problemløsningsprosess
Modellen:
Identifiserte korrekt alle beregningskrav (omsetning, fortjeneste, antall ekstra enheter nødvendig)
Utførte komplekse beregninger med perfekt nøyaktighet
Benyttet hensiktsmessige forutsetninger (opprettholdt salgstallforhold for ekstra enheter)
Klarhet i utdata
Responsen ble presentert i klare, lettfattelige avsnitt som:
Utrykte hvert beregningsresultat eksplisitt
Viste matematiske resonnement bak hvert tall
Opprettholdt logisk flyt fra nåsituasjon til prognose
Ytelsesmålinger
Fullføringstid: Omtrent 6 sekunder
Nøyaktighet: 100 % riktige beregninger
Forklaringskvalitet: Høy (tydelig resonnement)
Oppgave 3: Oppsummering – Kondensering av teknisk artikkel
Da GPT-4.1 Nano ble bedt om å oppsummere en kompleks teknisk artikkel om OpenAI sine o1-modeller, viste modellen eksepsjonelle ferdigheter i informasjonsekstraksjon.
Oppsummeringsmetode
Modellen:
Identifiserte og hentet ut sentrale tema fra originalinnholdet
Kondenserte informasjonen, samtidig som viktige begreper ble ivaretatt
Balanserte teknisk nøyaktighet med lesbarhet
Kvalitet på utdata
Oppsummeringen på 99 ord:
Overholdt nøyaktig begrensningen på 100 ord
Fanget utviklingen av AI-resonneringssystemer
Fremhevet nøkkelforskjeller mellom resonneringstyper
Inkluderte både applikasjoner (helsevesen) og utfordringer (etikk)
Opprettholdt passende teknisk språk
Ytelsesmålinger
Fullføringstid: Omtrent 2 sekunder
Antall ord: 99 ord (99 % av målet)
Lesenivå: Gjennomsnitt 19,8 ord per setning med avansert vokabular
Samfunnsmessige virkninger på flere områder (byplanlegging, økonomi, kultur)
Inkluderte plausible teknologiske fremskritt
Opprettholdt indre konsistens gjennom hele teksten
Ytelsesmålinger
Fullføringstid: 8 sekunder
Antall ord: 418 ord (84 % av målet på 500 ord)
Lesenivå: Flesch-Kincaid-nivå 17 (avansert)
Samlet vurdering
GPT-4.1 Nano viser imponerende allsidighet på tvers av ulike oppgavetyper, med særlig styrke innen:
Forskningsmetodikk: Spesielt tydelig i innholdsgenereringsoppgaven, der den brukte en avansert, flerstegs forskningsprosess
Matematisk nøyaktighet: Perfekt gjennomføring av komplekse beregninger
Informasjonssyntese: Sterk evne til å trekke ut nøkkelinformasjon fra komplekse kilder
Responshastighet: Konsistent rask ytelse (2–13 sekunder for enkeltoppgaver)
Tilpasningsevne: Smidig håndtering av utvidede krav
Potensielle forbedringsområder inkluderer:
Å treffe eksakt ordantall i kreative oppgaver
Mer eksplisitt dokumentasjon av informasjonsbearbeidingsprosessen i sammenlignende oppgaver
Modellen presterer spesielt godt på strukturerte oppgaver med tydelige rammer, der beregningsoppgaven viser høyest effektivitet. For kreative og analytiske oppgaver opprettholder GPT-4.1 Nano høy kvalitet med minimal prosesseringstid.
Denne analysen antyder at GPT-4.1 Nano er et kraftig valg for applikasjoner som krever allsidighet på tvers av ulike oppgavetyper, med vekt på effektivitet og nøyaktighet.
Vanlige spørsmål
Hva gjør at GPT-4.1 Nano utmerker seg i AI-ytelse?
GPT-4.1 Nano viser høy allsidighet, hastighet og nøyaktighet på oppgaver som innholdsgenerering, beregninger, oppsummering, sammenlignende analyse og kreativ skriving, noe som gjør den egnet for et bredt spekter av forretningsapplikasjoner.
Hvilke oppgaver ble evaluert i GPT-4.1 Nano-analysen?
Analysen dekket fem oppgaver: innholdsgenerering, forretningsberegninger, teknisk oppsummering, miljøsammenligning og kreativ skriving for å vurdere modellens ytelse og tilpasningsevne.
Hvor utmerker GPT-4.1 Nano seg, og hva kan forbedres?
Den utmerker seg på strukturerte oppgaver med tydelige rammer, forskningsmetodikk og matematisk nøyaktighet. Mulige forbedringer inkluderer å treffe nøyaktige ordantall i kreative oppgaver og mer detaljert dokumentasjon av informasjonsbearbeidingen i sammenlignende oppgaver.
Arshia er en AI Workflow Engineer hos FlowHunt. Med bakgrunn i informatikk og en lidenskap for kunstig intelligens, spesialiserer han seg på å lage effektive arbeidsflyter som integrerer AI-verktøy i daglige oppgaver, og dermed øker produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Prøv FlowHunt for AI-drevet automatisering
Oppdag hvordan du kan bruke FlowHunt til å bygge AI-løsninger med smarte chatboter og automatiseringsverktøy—helt uten koding.
Llama 4 Scout AI: Ytelsesxadanalyse på tvers av flere oppgaver
En grundig analyse av ytelsen til Metas Llama 4 Scout AI-modell på fem ulike oppgavetyper, som viser imponerende evner innen innholdsgenerering, beregning, opps...
Sinne til AI-agenter: Gemini 2.0 Flash Experimental
Utforsk de avanserte egenskapene til Gemini 2.0 Flash Experimental AI-agent. Dette dypdykket viser hvordan den går utover tekstgenerering, og demonstrerer dens ...
Utforsk de avanserte evnene til Gemini 1.5 Flash som en AI-agent. Dette dypdykket viser hvordan den går utover tekstgenerering, og fremhever dens resonneringsev...
9 min lesing
AI Agent
Gemini 1.5 Flash
+4
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.