


AI-agenter: Hvordan GPT 4o tenker
Utforsk tankeprosessene til AI-agenter i denne omfattende evalueringen av GPT-4o. Oppdag hvordan den presterer på oppgaver som innholdsgenerering, problemløsnin...
7 min lesing
AI
GPT-4o
+6

En grundig gjennomgang av GPT-4.1s ytelse på tvers av standard AI-oppgaver, med vekt på resonnering, effektivitet, praktiske bruksområder og konsekvent outputkvalitet.
OpenAIs GPT-4.1 representerer et betydelig fremskritt innen AI-egenskaper, med forbedringer i resonnering, verktøybruk og outputkvalitet. Denne analysen undersøker GPT-4.1s ytelse på tvers av fem grunnleggende oppgavetyper for å gi innsikt i dens praktiske evner og begrensninger.
Følgende analyse er basert på dokumentert ytelse av GPT-4.1 på fem standard benchmark-oppgaver:
For hver oppgave vurderer vi GPT-4.1s tilnærming til problemløsning, verktøybruk, prosesseringstid og outputkvalitet.
Da modellen ble bedt om å generere innhold om beste praksis for delegasjon i prosjektledelse, viste GPT-4.1 en strømlinjeformet tilnærming:
Denne ytelsen antyder at GPT-4.1 prioriterer effektivitet i innholdsgenerering, og går raskt fra informasjonsinnhenting til syntese uten å vise mellomliggende resonneringssteg.
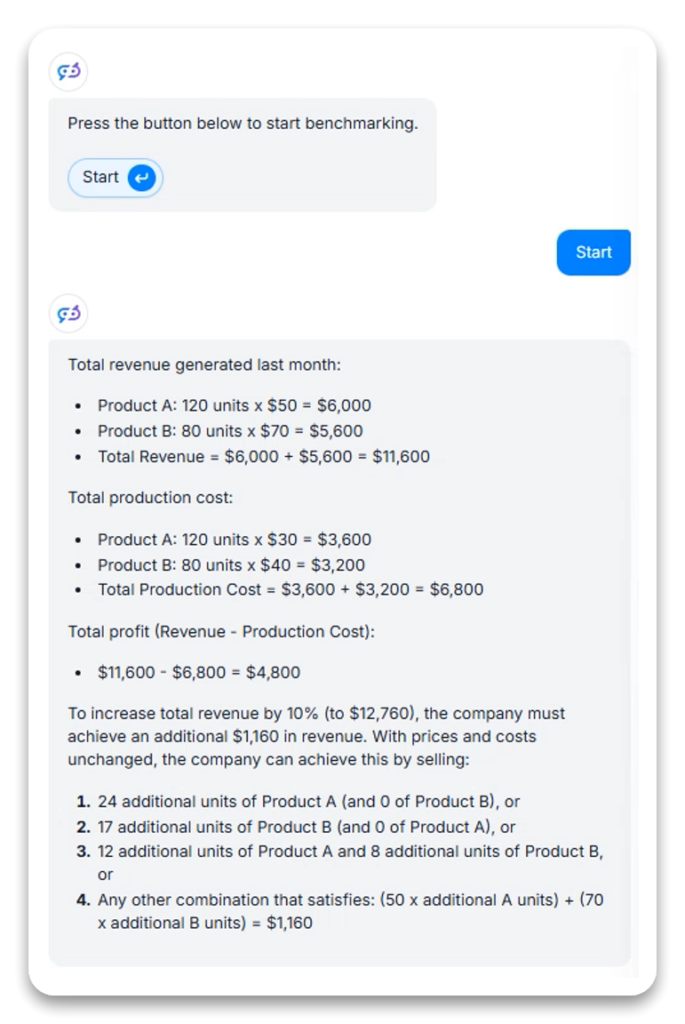
Beregningen testet GPT-4.1s evne til å løse et flertrinns forretningsproblem med inntekt, overskudd og strategisk planlegging.
GPT-4.1s tilnærming til matematisk resonnering ser ut til å fokusere på praktiske forretningsanvendelser fremfor abstrakte matematiske relasjoner, og gir spesifikke løsninger heller enn generaliserte ligninger.
Oppsummeringsoppgaven viste GPT-4.1s effektivitet i informasjonsdestillering:
Denne ytelsen viser GPT-4.1s evne til raskt å trekke ut og konsolidere essensiell informasjon uten å kreve eksplisitte resonneringssteg for enkle tekstprosesseringsoppgaver.
For sammenligningen mellom elektriske og hydrogendrevne biler benyttet GPT-4.1 sin mest omfattende forskningsprosess:
Denne ytelsen antyder at GPT-4.1 bruker betydelig mer prosesseringstid på oppgaver som krever grundig forskning og nyansert sammenligning, og prioriterer omfattende informasjonsinnhenting fremfor fart.
Den kreative skriveoppgaven viste GPT-4.1s tilnærming til fantasifull innholdsproduksjon:
GPT-4.1s tilnærming til kreativ skriving ser ut til å bygge på systematisk forskning og organisering før den kreative prosessen, noe som antyder et analytisk fundament for fantasifulle oppgaver.
Analysen på tvers av disse fem oppgavene avdekker flere konsekvente mønstre i hvordan GPT-4.1 tilnærmer seg ulike problemtyper:
GPT-4.1 viser sjelden sin interne resonneringsprosess, men viser i stedet:
Denne tilnærmingen prioriterer effektivitet, men reduserer transparens rundt hvordan konklusjoner trekkes.
Prosesseringstiden varierer betydelig etter oppgavens kompleksitet:
Dette tyder på intelligent ressursallokering etter oppgavens krav.
Til tross for variasjoner i prosessering, opprettholder GPT-4.1 konsekvent outputkvalitet på tvers av ulike oppgavetyper:
For oppgaver som krever spesialkunnskap:
Disse ytelseskjennetegnene antyder flere optimale bruksområder for GPT-4.1:
Modellens raske prosessering av enkle oppgaver gjør den egnet for:
Villigheten til å bruke mer tid på informasjonsinnhenting tilsier bruk i:
Fokuset på praktiske applikasjoner og flere løsningsveier gir verdi for:
GPT-4.1 viser en balansert tilnærming på tvers av ulike oppgavetyper, med særlige styrker innen effektiv informasjonsprosessering og praktisk anvendelse. Dens evne til å tilpasse prosesseringstiden etter oppgavens kompleksitet, samtidig som den opprettholder konsekvent outputkvalitet, gjør den godt egnet for en rekke forretnings- og profesjonelle bruksområder.
Modellens “black box”-tilnærming til resonnering—å vise handlinger, men ikke mellomliggende tanker—representerer både en begrensning i transparens og en fordel i prosesseringseffektivitet. For de fleste praktiske bruksområder ser det ut til at kvaliteten og relevansen på output veier opp for denne reduserte synligheten i resonneringsprosessen.
Etter hvert som organisasjoner i økende grad integrerer AI-hjelp i arbeidsflyter, posisjonerer GPT-4.1s kombinasjon av effektivitet, tilpasningsevne og outputkvalitet den som et verdifullt verktøy for kunnskapsarbeidere i ulike bransjer—spesielt for de som prioriterer praktiske resultater over innsyn i prosessen.
GPT-4.1 utmerker seg i effektiv informasjonsprosessering, konsekvent outputkvalitet og praktisk anvendelse innen innholdsgenerering, beregninger, oppsummering, komparativ analyse og kreativ skriving. Den tilpasser prosesseringstiden etter oppgavens kompleksitet og tilbyr handlingsrettede, godt strukturerte resultater.
Ja, GPT-4.1 bruker ofte en 'black-box'-tilnærming—viser handlinger og resultater, men avslører ikke sine interne resonneringssteg. Dette øker effektiviteten, men reduserer åpenheten rundt hvordan konklusjonene oppnås.
GPT-4.1 er ideell for oppgaver der effektivitet er avgjørende, som innholdsproduksjon, oppsummering, rutinemessige forretningsberegninger, førstegangs kreativ skriving, samt forskningsintensive oppgaver som komparativ analyse, markedsundersøkelser og støtte til strategiske forretningsbeslutninger.
Ved komplekse forsknings- og sammenligningsoppgaver bruker GPT-4.1 betydelig mer prosesseringstid og benytter sekvensiell bruk av verktøy (som søk og URL-gjennomgang) for å samle inn og syntetisere informasjon, noe som sikrer omfattende og balanserte resultater.
Arshia er en AI Workflow Engineer hos FlowHunt. Med bakgrunn i informatikk og en lidenskap for kunstig intelligens, spesialiserer han seg på å lage effektive arbeidsflyter som integrerer AI-verktøy i daglige oppgaver, og dermed øker produktivitet og kreativitet.
Opplev kraften i AI-modeller som GPT-4.1 i din arbeidsflyt. Bygg chatboter, automatiser oppgaver og akselerer virksomheten din med FlowHunt.
Utforsk tankeprosessene til AI-agenter i denne omfattende evalueringen av GPT-4o. Oppdag hvordan den presterer på oppgaver som innholdsgenerering, problemløsnin...
Utforsk de viktigste funksjonene, tekniske fremskrittene og den virkelige innvirkningen til GPT-5. Denne guiden dekker styrker, begrensninger, prising, etiske b...
Utforsk de avanserte egenskapene til AI-agenten GPT 4 Vision Preview. Dette dypdykket avslører hvordan den går langt utover tekstgenerering, og viser frem dens ...

