



Henting vs Cache-forsterket generering (CAG vs. RAG)
Oppdag de viktigste forskjellene mellom Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) innen AI. Lær hvordan RAG henter sanntidsinform...
5 min lesing
RAG
CAG
+5

Oppdag hvordan du bygger chatboter med Retrieval Interleaved Generation (RIG) for å sikre at AI-svar er nøyaktige, faktasjekket og inkluderer verifiserbare kilder.
Retrieval Interleaved Generation, eller RIG for kort, er en banebrytende AI-metode som sømløst kombinerer det å finne informasjon og lage svar. Tidligere brukte AI-modeller RAG (Retrieval Augmented Generation) eller kun generering, men RIG slår sammen disse prosessene for å forbedre AI-nøyaktighet. Ved å veve sammen innhenting og generering kan AI-systemer trekke på et bredere kunnskapsgrunnlag og tilby mer presise og relevante svar. Hovedmålet med RIG er å redusere feil og øke påliteligheten til AI-resultater, noe som gjør det til et essensielt verktøy for utviklere som vil finjustere AI-nøyaktighet. Dermed kommer Retrieval Interleaved Generation som et alternativ til RAG (Retrieval Augmented Generation) for å generere AI-drevne svar basert på en kontekst.
Slik fungerer RIG. Følgende steg er inspirert av det originale blogginnlegget](https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/ “Utforsk Googles DataGemma-modeller, som kobler AI til virkelige data for faktabaserte, pålitelige svar. Bli med og form en mer troverdig AI!”), som fokuserer mer på generelle brukstilfeller med Data Commons API. I de fleste tilfeller vil du likevel bruke både en generell [kunnskapsbase (f.eks. Wikipedia eller Data Commons) og dine egne data. Slik kan du bruke kraften i flyter i FlowHunt for å lage en RIG-chatbot fra både din kunnskapsbase og en generell kunnskapsbase som Wikipedia.
Et bruker-spørsmål sendes til en generator, som lager et eksempel-svar med henvisning til tilsvarende seksjoner. På dette trinnet kan generatoren til og med lage et godt svar, men med feilaktige eller oppdiktede data og statistikk.
I neste fase bruker vi en AI-agent som mottar dette utdataet og forbedrer dataene i hver seksjon ved å koble til Wikipedia, samt legger til kilder for hver enkelt seksjon.
Som du ser, øker denne metoden chatbotens nøyaktighet betydelig og sikrer at hver generert seksjon har en kilde og er forankret i sannheten.
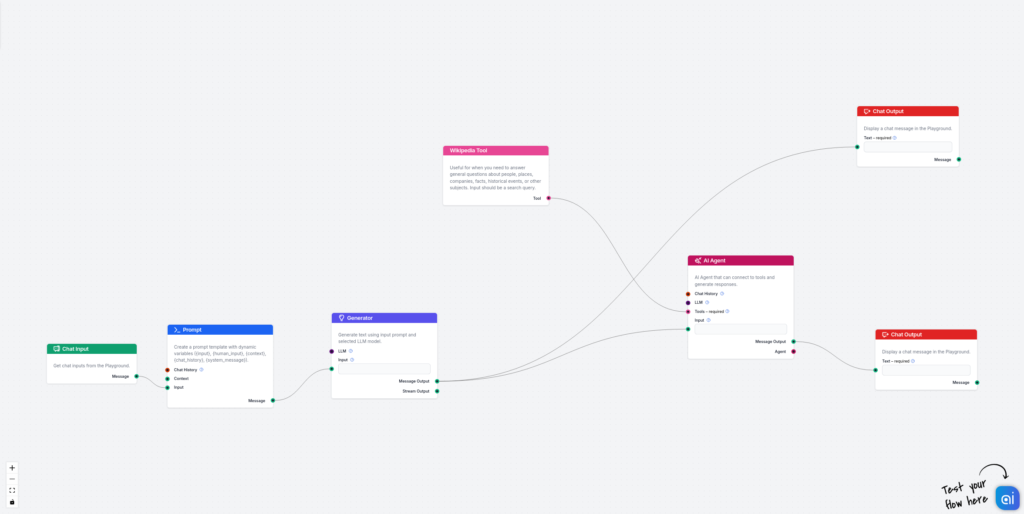
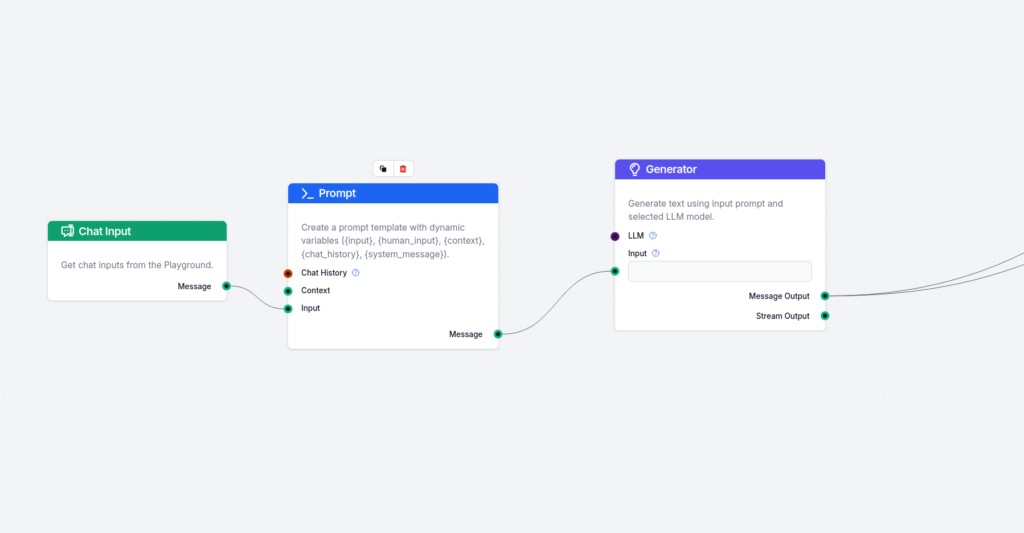
Første del av flyten består av Chat input, en prompt-mal og en generator. Koble dem rett sammen. Det viktigste er prompt-malen. Jeg har brukt følgende:
Gitt er brukerens spørsmål. Basert på brukerens spørsmål, generer best mulig svar med falske data eller prosenter. Etter hver av de ulike seksjonene i svaret ditt, inkluder hvilken datakilde som skal brukes for å hente riktige data og forbedre den seksjonen med korrekte opplysninger. Du kan enten spesifisere å bruke intern kunnskapskilde for å hente data dersom det finnes tilpassede data til brukerens produkt eller tjeneste, eller bruke Wikipedia som generell kunnskapskilde.
Eksempel input: Hvilke land er på topp innen fornybar energi, hva er den beste måten å måle dette på, og hva er det tallet for det beste landet?
Eksempel output: De beste landene innen fornybar energi er Norge, Sverige, Portugal, USA [Søk i Wikipedia med spørring “Top Countries in renewable Energy”], vanlig måleenhet for fornybar energi er Kapasitetsfaktor [Søk i Wikipedia med spørring “metric for renewable energy”], og nummer én land har 20 % kapasitetsfaktor [søk i Wikipedia “biggest capacity factor”]La oss begynne nå!
Brukerinput: {input}
Her bruker vi Few Shot-prompting for å få generatoren til å gi akkurat det formatet vi ønsker.
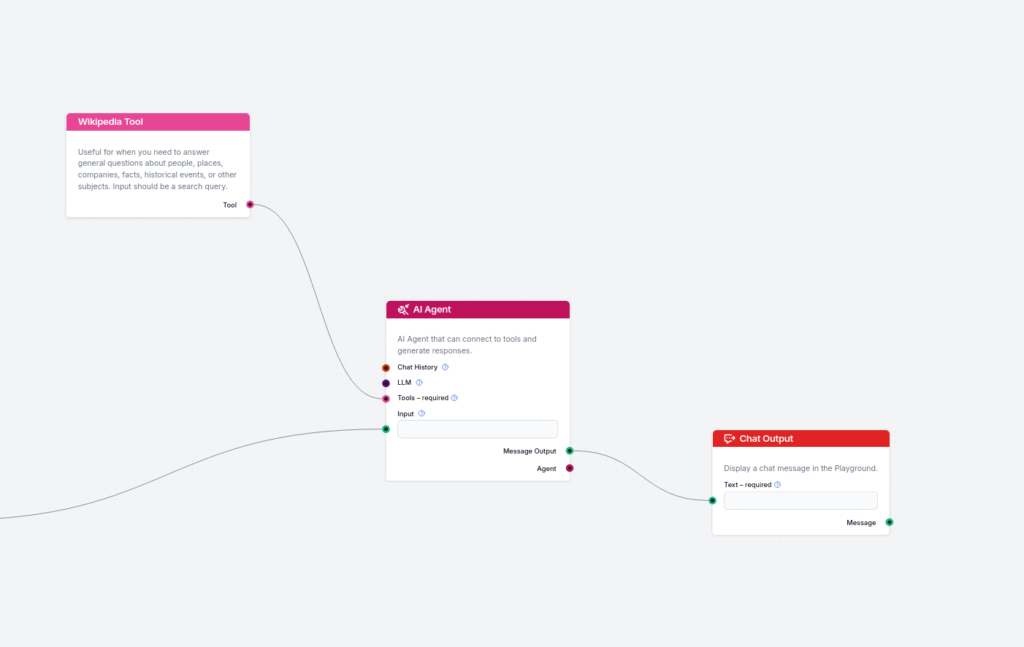
Nå legger du til den andre delen, som faktasjekker utdataet fra eksempel-svaret og forbedrer svaret basert på virkelige kilder. Her bruker vi Wikipedia og AI-agenter, da det er enklere og mer fleksibelt å koble Wikipedia til AI-agenter enn til enkle generatorer. Koble utdataet fra generatoren til AI-agenten, og koble Wikipedia-verktøyet til AI-agenten. Dette er målet jeg bruker for AI-agenten:
Du får et eksempel-svar på brukerens spørsmål. Eksempel-svaret kan inneholde feil data. Bruk Wikipedia-verktøyet i de gitte seksjonene med spesifisert spørring for å bruke Wikipedias informasjon til å forbedre svaret. Inkluder lenken til Wikipedia i hver av de spesifiserte seksjonene. HENT DATA FRA DINE VERKTØY OG FORBEDRE SVARET I DEN SEKSONEN. LEGG TIL LENKEN TIL KILDEN I DEN AKTUELLE SEKSONEN, IKKE I SLUTTEN.
På samme måte kan du legge til dokumenthenter til AI-agenten, som kan kobles til din egen kunnskapsbase for å hente dokumenter.
Du kan prøve akkurat denne flyten her.
For å virkelig forstå RIG, er det nyttig å først se på forgjengeren, Retrieval-Augmented Generation (RAG). RAG kombinerer styrkene til systemer som henter relevant data og modeller som genererer sammenhengende og passende innhold. Overgangen fra RAG til RIG er et stort steg fremover. RIG henter ikke bare og genererer, men blander også disse prosessene for bedre nøyaktighet og effektivitet. Dette gjør at AI-systemer kan forbedre forståelsen og utdataene sine steg for steg, og levere resultater som ikke bare er nøyaktige, men også relevante og innsiktsfulle. Ved å blande innhenting og generering kan AI-systemer dra nytte av enorme mengder informasjon, samtidig som svarene forblir sammenhengende og relevante.
Fremtiden for Retrieval Interleaved Generation ser lovende ut, med mange fremskritt og forskningsretninger på horisonten. Etter hvert som AI vokser, vil RIG spille en nøkkelrolle i å forme verdenen av maskinlæring og AI-applikasjoner. Dens potensielle innvirkning går utover dagens muligheter, og lover å forandre hvordan AI-systemer behandler og genererer informasjon. Med pågående forskning forventes ytterligere innovasjoner som vil forbedre integreringen av RIG i ulike AI-rammeverk, som igjen gir mer effektive, nøyaktige og pålitelige AI-systemer. Etter hvert som disse utviklingene skjer, vil viktigheten av RIG bare øke, og befeste sin rolle som en hjørnestein for AI-nøyaktighet og ytelse.
Avslutningsvis markerer Retrieval Interleaved Generation et stort fremskritt i jakten på AI-nøyaktighet og effektivitet. Ved å på en dyktig måte blande innhentings- og genereringsprosesser forbedrer RIG ytelsen til store språkmodeller, styrker flerstegs resonnering og gir spennende muligheter innen utdanning og faktasjekk. Ser vi fremover, vil utviklingen av RIG utvilsomt drive nye innovasjoner i AI, og befeste dens rolle som et viktig verktøy i jakten på smartere og mer pålitelige kunstig intelligens-systemer.
RIG er en AI-metode som kombinerer informasjonsinnhenting og svar-generering, slik at chatboter kan faktasjekke sine egne svar og gi kildestøttede, nøyaktige resultater.
RIG vever sammen innhentings- og genereringssteg, ved å bruke verktøy som Wikipedia eller dine egne data, slik at hver del av svaret er forankret i pålitelige kilder og verifisert for nøyaktighet.
Med FlowHunt kan du designe en RIG-chatbot ved å koble sammen prompt-maler, generatorer og AI-agenter til både interne og eksterne kunnskapskilder, noe som muliggjør automatisk faktasjekking og kildehenvisning.
Mens RAG (Retrieval Augmented Generation) henter informasjon og deretter genererer svar, flettes disse stegene sammen for hver del i RIG, noe som gir høyere nøyaktighet og mer pålitelige, kildebaserte svar.
Yasha er en dyktig programvareutvikler som spesialiserer seg på Python, Java og maskinlæring. Yasha skriver tekniske artikler om AI, prompt engineering og utvikling av chatboter.
Begynn å bygge smarte chatboter og AI-verktøy med FlowHunt sin intuitive plattform uten koding. Koble blokker sammen og automatiser idéene dine enkelt.
Oppdag de viktigste forskjellene mellom Retrieval-Augmented Generation (RAG) og Cache-Augmented Generation (CAG) innen AI. Lær hvordan RAG henter sanntidsinform...
Retrieval Augmented Generation (RAG) er et avansert AI-rammeverk som kombinerer tradisjonelle informasjonshentingssystemer med generative store språkmodeller (L...
Spørsmål og svar med Retrieval-Augmented Generation (RAG) kombinerer informasjonsinnhenting og naturlig språk-generering for å forbedre store språkmodeller (LLM...

