Ytelsesanalyse av Gemini 2.0 Thinking: En omfattende evaluering
En omfattende evaluering av Gemini 2.0 Thinking, Googles eksperimentelle AI-modell, med fokus på ytelse, resonneringsåpenhet og praktiske anvendelser på tvers av sentrale oppgavetyper.
AI
Gemini 2.0
Model Evaluation
AI Transparency
AI Reasoning
Content Generation
Summarization
Calculation
Comparison
Analytical Writing
Metodikk
Vår evalueringsmetodikk involverte testing av Gemini 2.0 Thinking på fem representative oppgavetyper:
Innholdsgenerering – Lage strukturert informasjonsinnhold
Beregning – Løse flerstegs matematiske problemer
Oppsummering – Kondensere kompleks informasjon effektivt
Sammenligning – Analysere og sammenligne komplekse temaer
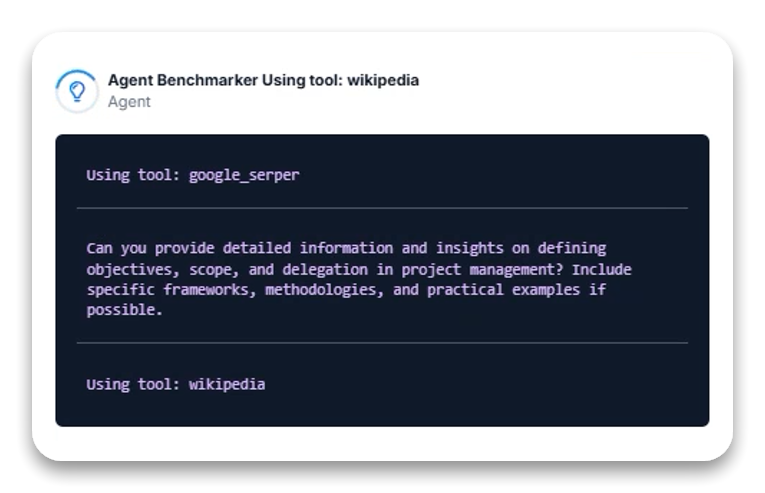
Oppgavebeskrivelse: Generer en omfattende artikkel om prosjektledelsens grunnprinsipper, med fokus på å definere mål, omfang og delegering.
Ytelsesanalyse:
Gemini 2.0 Thinking sin synlige resonneringsprosess er bemerkelsesverdig. Modellen viste en systematisk, flerstegs forsknings- og syntesetilnærming på tvers av to oppgavevarianter:
Starter med Wikipedia for grunnleggende kontekst
Bruker Google-søk for spesifikke detaljer og beste praksis
Foretar videre søk basert på innledende funn
Gjennomgår spesifikke nettadresser for dypere informasjon
Styrker i informasjonsbehandling:
I den andre varianten viste den avansert kildeidentifisering og gjennomgikk flere nettadresser for detaljerte opplysninger
Lagde svært strukturerte utdata med tydelig hierarkisk organisering (13. klassetrinns lesbarhet)
Inkluderte spesifikke rammeverk etter forespørsel (SMART, OKR, WBS, RACI-matrise)
Balanserte effektivt teoretiske konsepter med praktiske anvendelser
Effektivitetsmålinger:
Behandlingstid: 30 sekunder (Variant 1) vs. 56 sekunder (Variant 2)
Lengre behandlingstid i Variant 2 samsvarte med mer omfattende forskning og mer detaljert output (710 vs. ~500 ord)
Ytelsesvurdering:9/10
Ytelsen på innholdsgenerering får høy vurdering grunnet modellens evne til å:
Gjennomføre flerkilde-forskning autonomt
Strukturere informasjon logisk med hensiktsmessige overskrifter/underoverskrifter
Balanserer teori og praktiske rammeverk
Tilpasse forskningsdybde basert på spesifisitet i prompt
Hovedstyrken til Thinking-versjonen er synligheten i forskningsprosessen, hvor de spesifikke verktøyene som brukes i hvert trinn vises, selv om eksplisitte resonneringsutsagn ble vist inkonsekvent.
Oppgave 2: Ytelse på beregning
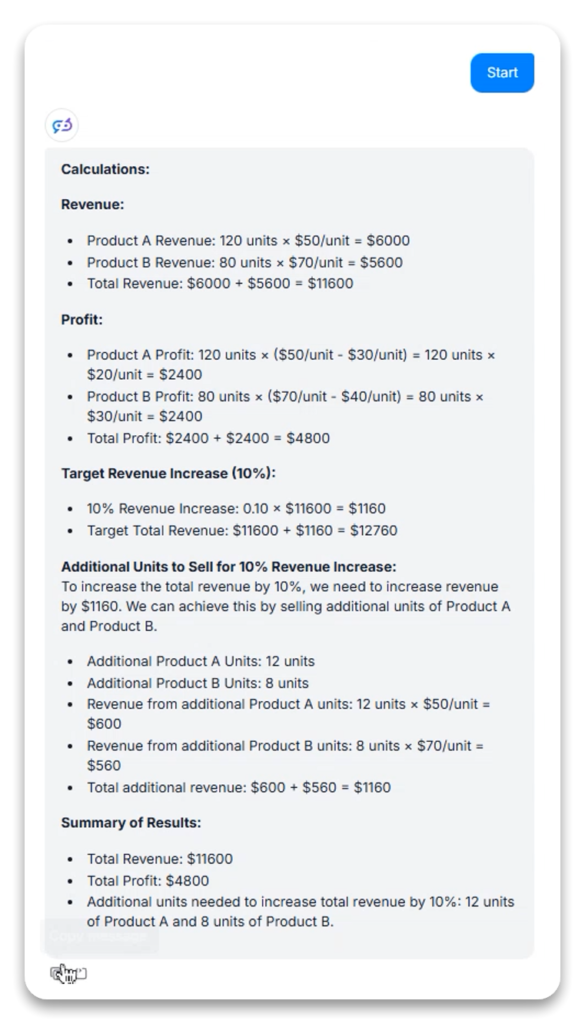
Oppgavebeskrivelse: Løs et flerdelt forretningsberegningsproblem som involverer inntekt, fortjeneste og optimalisering.
Ytelsesanalyse:
På begge oppgavevarianter viste modellen sterke matematiske resonneringsevner:
De-komponering: Brøt ned komplekse problemer i logiske delberegninger (inntekt per produkt → total inntekt → kostnad per produkt → total kostnad → fortjeneste per produkt → total fortjeneste)
Optimalisering: I første variant, da den ble bedt om å finne antall enheter som trengs for 10 % inntektsøkning, uttalte modellen eksplisitt sin optimaliseringstilnærming (prioriterte dyrere produkter for å minimere totalenheter)
Verifisering: I den andre varianten demonstrerte modellen resultatverifisering ved å beregne om foreslått løsning (12 enheter A, 8 enheter B) ville oppnå ønsket tilleggsinntekt
Styrker i matematisk behandling:
Presisjon i beregninger uten matematiske feil
Transparent steg-for-steg-gjennomgang som gjør verifisering enkel
Effektiv bruk av formatering (punktlister, tydelige seksjonsoverskrifter) for å organisere beregningstrinn
Ulike løsningsmetoder mellom varianter viser fleksibilitet
Effektivitetsmålinger:
Behandlingstid: 19 sekunder (Variant 1) vs. 23 sekunder (Variant 2)
Konsistent ytelse på tvers av variantene til tross for ulike løsningsmetoder
Ytelsesvurdering:9,5/10
Beregningsevnen får toppkarakter basert på:
Perfekt nøyaktighet i beregningene
Klar dokumentasjon av stegene
Flere løsningsmetoder som viser fleksibilitet
Effektiv behandlingstid
Tydelig resultatpresentasjon og verifisering
“Thinking”-funksjonen var spesielt verdifull i første variant, hvor modellen eksplisitt beskrev sine antakelser og optimaliseringsstrategi, og ga åpenhet i beslutningsprosessen som ville manglet i standardmodeller.
Oppgave 3: Ytelse på oppsummering
Oppgavebeskrivelse: Oppsummer hovedfunn fra en artikkel om AI-resonnering på 100 ord.
Ytelsesanalyse:
Modellen viste imponerende effektivitet i tekstoppsummering på begge oppgavevarianter:
Behandlingshastighet: Fullførte oppsummeringen på omtrent 3 sekunder i begge varianter
Overholdelse av lengdekrav: Genererte oppsummeringer godt innenfor 100-ordsgrensen (70-71 ord)
Innholdsutvalg: Identifiserte og inkluderte de viktigste aspektene av kildeteksten
Informasjonstetthet: Opprettholdt høy informasjonstetthet mens oppsummeringen forble sammenhengende
Styrker i oppsummering:
Eksepsjonell behandlingshastighet (3 sekunder)
Perfekt overholdelse av lengdekrav
Bevaring av sentrale tekniske konsepter
Opprettholdelse av logisk flyt til tross for stor komprimering
Balansert dekning av kildedokumentets seksjoner
Effektivitetsmålinger:
Behandlingstid: ~3 sekunder i begge varianter
Oppsummeringslengde: 70-71 ord (innenfor 100-ordsgrensen)
Informasjonskomprimeringsrate: Omtrent 85-90 % reduksjon fra kilden
Ytelsesvurdering:10/10
Oppsummeringsytelsen får toppkarakter grunnet:
Ekstremt rask behandlingstid
Perfekt etterlevelse av krav
Utmerket informasjonsprioritering
Sterk sammenheng til tross for høy komprimering
Konsistent ytelse på begge testvarianter
Interessant nok viste ikke “Thinking”-funksjonen eksplisitt resonnering i denne oppgaven, noe som antyder at modellen kan bruke ulike kognitive fremgangsmåter for forskjellige oppgaver, hvor oppsummering trolig er mer intuitivt enn stegvis.
Oppgave 4: Ytelse på sammenligningsoppgave
Oppgavebeskrivelse: Sammenlign miljøpåvirkningen av elbiler med hydrogenbiler på tvers av flere faktorer.
Ytelsesanalyse:
Modellen benyttet ulike fremgangsmåter mellom de to variantene, med merkbare forskjeller i behandlingstid og kildebruk:
Variant 1: Stolte hovedsakelig på Google-søk, ferdig på 20 sekunder
Variant 2: Brukte Google-søk etterfulgt av URL-gjennomgang for dypere informasjon, ferdig på 46 sekunder
Styrker i komparativ analyse:
Godt strukturerte sammenligningsrammeverk med tydelig kategorisering
Balansert perspektiv på begge teknologiers fordeler og begrensninger
Integrasjon av spesifikke datapunkter (effektivitetsprosenter, påfyllingstider)
Variant 2 viste sterkere bevis på spesifikk kildebruk
Begge opprettholdt tilsvarende lesbarhetsnivå (14-15. klassetrinn)
Ytelsesvurdering:8,5/10
Sammenligningsytelsen får en sterk vurdering på grunn av:
Godt strukturerte rammeverk
Balansert analyse av fordeler/ulemper
Teknisk nøyaktighet og passende dybde
Tydelig organisering etter relevante faktorer
Tilpasning av forskningsstrategi etter informasjonsbehov
“Thinking”-funksjonen var tydelig i verktøybruksloggene, og viste modellens sekvensielle tilnærming til informasjonsinnhenting: bredt søk først, deretter målrettet gjennomgang av nettadresser. Denne åpenheten hjelper brukere å forstå hvilke kilder som informerer sammenligningen.
Oppgave 5: Ytelse på kreativ/analytisk skriving
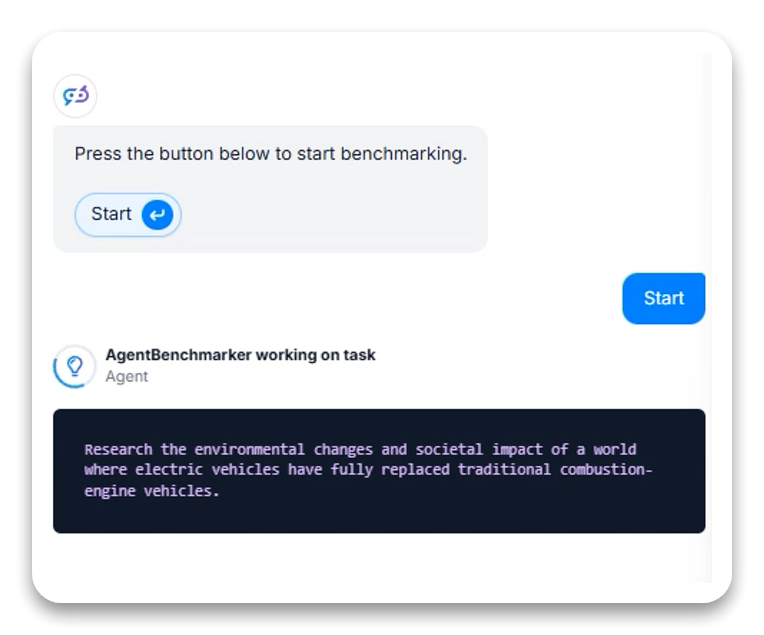
Oppgavebeskrivelse: Analyser miljøendringer og samfunnsmessige konsekvenser i en verden hvor elbiler har erstattet forbrenningsmotorer fullstendig.
Ytelsesanalyse:
På begge varianter viste modellen sterke analytiske evner uten synlig verktøybruk:
Behandlingstid: 43 sekunder (Variant 1) vs. 39 sekunder (Variant 2)
Ordtelling: ~543 ord (Variant 1) vs. 1829 ord (Variant 2)
Ytelsesvurdering:9/10
Den kreative/analytiske skriveytelsen får toppkarakter basert på:
Omfattende dekning av alle forespurte aspekter
Imponerende lengde og detaljnivå
Balanse mellom optimistisk visjon og pragmatiske utfordringer
Sterk tverrfaglig sammenheng
Rask behandling til tross for kompleks analyse
For denne oppgaven var “Thinking”-aspektet mindre synlig i loggene, noe som tyder på at modellen i større grad baserer seg på intern kunnskapssyntese heller enn ekstern verktøybruk for kreative/analytiske oppgaver.
Samlet ytelsesvurdering
Basert på vår helhetlige evaluering, viser Gemini 2.0 Thinking imponerende kapasitet på tvers av ulike oppgavetyper, med dens særegne trekk i synliggjøring av egen problemløsningstilnærming:
Det som skiller Gemini 2.0 Thinking fra standard AI-modeller, er dens eksperimentelle tilnærming til synliggjøring av interne prosesser. Viktige fordeler inkluderer:
Åpenhet om verktøybruk – Brukere kan se når og hvorfor modellen bruker spesifikke verktøy som Wikipedia, Google-søk eller URL-gjennomgang
Glimt av resonnering – I noen oppgaver, spesielt beregninger, deler modellen eksplisitt sin resonneringsprosess og antakelser
Sekvensiell problemløsning – Loggene viser modellens sekvensielle tilnærming til komplekse oppgaver, hvor forståelsen bygges gradvis
Innsikt i forskningsstrategi – Synlig prosess demonstrerer hvordan modellen forbedrer søkene basert på innledende funn
Fordeler med denne åpenheten:
Økt tillit gjennom synlighet i prosessen
Læringsverdi ved å observere ekspertproblemløsning
Feilsøkingspotensial når output ikke møter forventningene
Forskningsinnsikt i AI-resonneringsmønstre
Praktiske anvendelser
Gemini 2.0 Thinking viser særlig potensiale for applikasjoner som krever:
Forskning og syntese – Samler og organiserer informasjon fra flere kilder effektivt
Pedagogiske demonstrasjoner – Synlig resonneringsprosess gjør den verdifull for å lære bort problemløsningsmetoder
Kompleks analyse – Sterk evne til tverrfaglig resonnering med transparent metode
Samarbeidsarbeid – Resonneringsåpenhet gjør det enklere for mennesker å forstå og bygge videre på modellens arbeid
Modellens hastighet, kvalitet og prosessynlighet gjør den særlig egnet for profesjonelle sammenhenger hvor forståelsen av “hvorfor” bak AI-konklusjoner er like viktig som selve konklusjonene.
Konklusjon
Gemini 2.0 Thinking representerer en interessant eksperimentell retning innen AI-utvikling, hvor fokus ligger ikke bare på output-kvalitet, men også på prosessynlighet. Ytelsen i vårt testsett viser sterke evner innen forskning, beregning, oppsummering, sammenligning og kreativ/analytisk skriving, med spesielt fremragende resultater på oppsummering (10/10).
“Thinking”-tilnærmingen gir verdifulle innblikk i hvordan modellen angriper ulike problemer, selv om åpenheten varierer betydelig mellom oppgavetyper. Denne inkonsekvensen er hovedområdet for forbedring—mer enhetlig resonneringsvisning vil øke modellens verdi for læring og samarbeid.
Totalt, med en samlet score på 9,2/10, fremstår Gemini 2.0 Thinking som et svært kapabelt AI-system med den ekstra fordelen av prosessynlighet, noe som gjør modellen spesielt egnet for bruksområder hvor forståelsen av resonneringsveien er like viktig som det endelige resultatet.
Vanlige spørsmål
Hva er Gemini 2.0 Thinking?
Gemini 2.0 Thinking er en eksperimentell AI-modell fra Google som viser sine resonneringsprosesser, og gir åpenhet i hvordan den løser problemer på tvers av ulike oppgaver som innholdsgenerering, beregning, oppsummering og analytisk skriving.
Hva skiller Gemini 2.0 Thinking fra andre AI-modeller?
Dens unike 'tenkende' åpenhet lar brukere se verktøybruk, resonneringstrinn og problemløsningsstrategier, noe som øker tillit og læringsverdi—spesielt i forsknings- og samarbeidskontekster.
Hvordan ble Gemini 2.0 Thinking evaluert i denne analysen?
Modellen ble benchmark-testet på fem sentrale oppgavetyper: innholdsgenerering, beregning, oppsummering, sammenligning og kreativ/analytisk skriving, med måleparametere som behandlingstid, output-kvalitet og synlighet i resonnering.
Hva er hovedstyrkene til Gemini 2.0 Thinking?
Styrkene inkluderer flerkilde-forskning, høy presisjon i beregninger, rask oppsummering, godt strukturerte sammenligninger, omfattende analyser og eksepsjonell prosessynlighet.
Hvilke områder trenger forbedring i Gemini 2.0 Thinking?
Modellen vil ha nytte av mer konsekvent åpenhet i sin resonneringsvisning på tvers av alle oppgavetyper og tydeligere logger for verktøybruk i alle scenarioer.
Arshia er en AI Workflow Engineer hos FlowHunt. Med bakgrunn i informatikk og en lidenskap for kunstig intelligens, spesialiserer han seg på å lage effektive arbeidsflyter som integrerer AI-verktøy i daglige oppgaver, og dermed øker produktivitet og kreativitet.
Arshia Kahani
AI Workflow Engineer
Klar for å oppleve transparent AI-resonnering?
Oppdag hvordan prosessynlighet og avansert resonnering i Gemini 2.0 Thinking kan løfte dine AI-løsninger. Book en demo eller prøv FlowHunt i dag.
Gemini 2.5 Pro Preview: Ytelsesanalyse på Tvers av Viktige Oppgaver
En omfattende gjennomgang av Googles Gemini 2.5 Pro Preview, som vurderer dens ytelse i virkelige scenarioer på fem nøkkelområder, inkludert innholdsgenerering,...
Utforsk tankeprosessen, arkitekturen og beslutningstakingen til Gemini 1.5 Pro, en allsidig KI-agent, gjennom virkelige oppgaver og grundig analyse av dens reso...
10 min lesing
AI Agents
Reasoning
+5
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.