

Gemini Flash 2.0: KI med fart og presisjon
Gemini Flash 2.0 setter nye standarder innen KI med forbedret ytelse, hastighet og multimodale egenskaper. Utforsk potensialet i virkelige applikasjoner.
3 min lesing
AI
Gemini Flash 2.0
+4

Wan 2.1 er en kraftig åpen AI-modell for videoproduksjon fra Alibaba, som leverer studiokvalitetsvideoer fra tekst eller bilder, gratis for alle å bruke lokalt.
Wan 2.1 (også kalt WanX 2.1) baner ny vei som en fullt åpen AI-modell for videoproduksjon utviklet av Alibabas Tongyi Lab. I motsetning til mange proprietære videomodeller som krever dyre abonnement eller API-tilgang, leverer Wan 2.1 sammenlignbar eller bedre kvalitet – samtidig som den forblir helt gratis og tilgjengelig for utviklere, forskere og kreative fagfolk.
Det som virkelig gjør Wan 2.1 spesiell, er kombinasjonen av tilgjengelighet og ytelse. Den mindre T2V-1.3B-varianten krever kun ~8,2 GB GPU-minne, og er dermed kompatibel med de fleste moderne forbruker-GPU-er. Samtidig leverer den større 14B-variant ytelse i toppklasse som overgår både åpne alternativer og mange kommersielle modeller i standardtester.
Wan 2.1 er ikke begrenset til bare tekst-til-video-generering. Dens allsidige arkitektur støtter:
Denne fleksibiliteten betyr at du kan starte med en tekstprompt, et stillbilde eller til og med en eksisterende video – og forme det etter din kreative visjon.
Som den første videomodellen som kan gjengi lesbar engelsk og kinesisk tekst i genererte videoer, åpner Wan 2.1 nye muligheter for internasjonale innholdsskapere. Funksjonen er spesielt nyttig for å lage undertekster eller scenetekst i flerspråklige videoer.
Kjernen i Wan 2.1s effektivitet er dens 3D kausale Video Variational Autoencoder. Dette teknologiske gjennombruddet komprimerer effektivt rom-tid-informasjon, slik at modellen kan:
Den mindre 1.3B-modellen krever bare 8,19 GB VRAM og kan produsere en 5-sekunders, 480p video på omtrent 4 minutter på en RTX 4090. Til tross for denne effektiviteten, matcher eller overgår kvaliteten den til langt større modeller, noe som gir den den perfekte balansen mellom fart og visuell kvalitet.
I offentlige evalueringer oppnådde Wan 14B høyest totalscore i Wan-Bench-tester, og overgikk konkurrentene på:
I motsetning til lukkede systemer som OpenAIs Sora eller Runways Gen-2, er Wan 2.1 fritt tilgjengelig for lokal kjøring. Den overgår vanligvis tidligere åpne modeller (som CogVideo, MAKE-A-VIDEO og Pika), og til og med mange kommersielle løsninger på kvalitetsbenchmark.
En nylig bransjeundersøkelse bemerket at «blant mange AI-videomodeller utmerker Wan 2.1 og Sora seg» – Wan 2.1 for sin åpenhet og effektivitet, og Sora for sin proprietære innovasjon. I brukertester har mange rapportert at Wan 2.1s bilde-til-video-funksjon overgår konkurrentene på klarhet og filmatisk uttrykk.
Wan 2.1 bygger på en diffusjons-transformer-ryggrad med en ny rom-tids-VAE. Slik fungerer det:
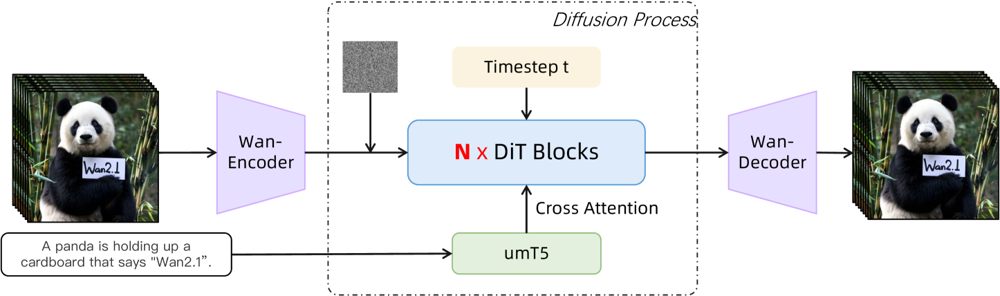
Figur: Wan 2.1s oversiktsarkitektur (tekst-til-video). En video (eller et bilde) kodes først av Wan-VAE-encoder til en latent. Denne latenten sendes deretter gjennom N diffusjonstransformerblokker, som benytter tekstelementene (fra umT5) via cross-attention. Til slutt rekonstruerer Wan-VAE-dekoderen videorammene. Dette designet – med en «3D kausal VAE-encoder/dekoder rundt en diffusjonstransformer» (ar5iv.org) – muliggjør effektiv komprimering av rom-tid-data og støtter video av høy kvalitet.
Denne innovative arkitekturen – med en «3D kausal VAE-encoder/dekoder rundt en diffusjonstransformer» – muliggjør effektiv komprimering av rom-tid-data og støtter video av høy kvalitet.
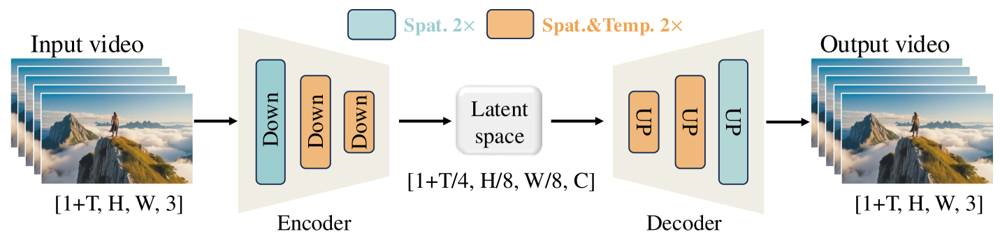
Wan-VAE er spesialdesignet for videoer. Den komprimerer input med imponerende faktorer (temporalt 4× og spatialt 8×) til en kompakt latent før dekoding tilbake til full video. Bruk av 3D-konvolusjoner og kausale (tidsbevarende) lag sikrer sammenhengende bevegelse gjennom hele det genererte innholdet.
Figur: Wan 2.1s Wan-VAE-rammeverk (encoder-dekoder). Wan-VAE-encoderen (venstre) bruker en serie nedskaleringslag («Down») på inputvideoen (form [1+T, H, W, 3] rammer) til den når en kompakt latent ([1+T/4, H/8, W/8, C]). Wan-VAE-dekoderen (høyre) oppskalerer symmetrisk («UP») denne latenten tilbake til de opprinnelige videorammene. Blå blokker indikerer spatial komprimering, og oransje blokker indikerer kombinert spatial+temporal komprimering (ar5iv.org). Ved å komprimere videoen 256× (i rom-tidsvolum), gjør Wan-VAE høyoppløst videogenerering mulig for den følgende diffusjonsmodellen.
Klar for å prøve Wan 2.1 selv? Slik kommer du i gang:
Klon depotet og installer avhengigheter:
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
Last ned modellvekter:
pip install "huggingface_hub[cli]"
huggingface-cli login
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
Lag din første video:
python generate.py --task t2v-14B --size 1280*720 \
--ckpt_dir ./Wan2.1-T2V-14B \
--prompt "A futuristic city skyline at sunset, with flying cars zooming overhead."
--offload_model True --t5_cpu for å legge deler av modellen til CPU--size parameteren (f.eks. 832*480 for 16:9 480p)Til referanse kan en RTX 4090 generere en 5 sekunders 480p-video på ca. 4 minutter. Multi-GPU-oppsett og ulike ytelsesoptimaliseringer (FSDP, kvantisering osv.) støttes for storskala bruk.
Som en åpen kildekode-utfordrer til gigantene innen AI-videogenerering, representerer Wan 2.1 et betydelig skifte i tilgjengelighet. Dens gratis og åpne natur betyr at alle med et brukbart grafikkort kan utforske banebrytende videogenerering uten abonnement eller API-kostnader.
For utviklere gir den åpne lisensen mulighet til å tilpasse og forbedre modellen. Forskere kan utvide dens kapasiteter, mens kreative kan prototype videoinnhold raskt og effektivt.
I en tid hvor proprietære AI-modeller i økende grad er låst bak betalingsmurer, demonstrerer Wan 2.1 at topp ytelse kan demokratiseres og deles med det brede fellesskapet.
Wan 2.1 er en helt åpen AI-modell for videoproduksjon utviklet av Alibabas Tongyi Lab, i stand til å lage videoer av høy kvalitet fra tekstprompter, bilder eller eksisterende videoer. Den er gratis å bruke, støtter flere oppgaver, og kjører effektivt på vanlige GPU-er.
Wan 2.1 støtter multi-task videoproduksjon (tekst-til-video, bilde-til-video, videoredigering, osv.), flerspråklig tekstgjengivelse i videoer, høy effektivitet med sin 3D kausale Video VAE, og overgår mange kommersielle og åpne modeller i tester.
Du trenger Python 3.8+, PyTorch 2.4.0+ med CUDA, og et NVIDIA-grafikkort (8GB+ VRAM for mindre modell, 16–24GB for stor modell). Klon GitHub-repoet, installer avhengigheter, last ned modellvektene, og bruk medfølgende skript for å lage videoer lokalt.
Wan 2.1 demokratiserer tilgang til banebrytende videogenerering ved å være åpen og gratis, slik at utviklere, forskere og kreative kan eksperimentere og innovere uten betalingsmurer eller proprietære begrensninger.
I motsetning til lukkede alternativer som Sora eller Runway Gen-2, er Wan 2.1 helt åpen og kan kjøres lokalt. Den overgår vanligvis tidligere åpne modeller og matcher eller overgår mange kommersielle løsninger på kvalitetsbenchmark.
Arshia er en AI Workflow Engineer hos FlowHunt. Med bakgrunn i informatikk og en lidenskap for kunstig intelligens, spesialiserer han seg på å lage effektive arbeidsflyter som integrerer AI-verktøy i daglige oppgaver, og dermed øker produktivitet og kreativitet.
Begynn å lage dine egne AI-verktøy og video-generasjonsarbeidsflyter med FlowHunt, eller bestill en demo for å se plattformen i aksjon.
Gemini Flash 2.0 setter nye standarder innen KI med forbedret ytelse, hastighet og multimodale egenskaper. Utforsk potensialet i virkelige applikasjoner.
Integrer FlowHunt med Creatify MCP Server for å automatisere AI avatar videoproduksjon, effektivisere videoflyter og forbedre innholdsproduksjon med avanserte M...
Integrer FlowHunt med WavespeedMCP for å automatisere avanserte AI-baserte arbeidsflyter for bilde- og videogenerering. Lås opp tekst-til-bilde, bilde-til-bilde...