KI kan analysere store mengder data på sekunder, men bare noe av informasjonen vil være relevant eller egnet for utdata. Document to Text-komponenten gir deg kontroll over hvordan data fra retrievere behandles og omformes til tekst.
Document to Text-komponenten er utviklet for å omforme inngående kunnskapsdokumenter til vanlig tekstformat. Dette er spesielt nyttig i KI- og databehandlingsflyter der tekstdata kreves for videre behandling, analyse eller som input til språkmodeller.
Hva komponenten gjør
Denne komponenten tar ett eller flere strukturerte dokumenter (som HTML, Markdown, PDF-er eller andre støttede formater) og trekker ut tekstinnholdet. Du kan spesifisere nøyaktig hvilke deler av dokumentene som skal eksporteres, om metadata skal inkluderes, og hvordan dokumentseksjoner eller overskrifter skal håndteres. Resultatet er et samlet meldingsobjekt med den uttrukne teksten, klart for videre oppgaver som oppsummering, klassifisering eller spørsmål og svar.
Inndata
Komponenten godtar flere konfigurerbare inndata:
| Inndatanavn | Type | Påkrevd | Beskrivelse | Standardverdi |
|---|---|---|---|---|
| Dokumenter | List[Document] | Ja | Kunnskapsdokumentene som skal omformes til tekst. | N/A (bruker leverer) |
| Fra H1 hvis finnes | Boolean | Ja | Start uttrekking fra den første H1-overskriften hvis den finnes. | true |
| Last fra peker | Boolean | Ja | Start uttrekking fra pekeren som best matcher innspørringen, eller last alle hvis ingen treff. | true |
| Maks antall tokens | Integer | Nei | Maksimalt antall tokens i utdata-teksten. | 3000 |
| Hopp over siste header | Boolean | Ja | Hopp over siste overskrift (ofte en footer) for å optimalisere utdata. | false |
| Strategi | String | Ja | Strategi for tekstuttrekking: sett sammen dokumenter eller inkluder lik størrelse fra hver. | “Inkluder lik størrelse fra hvert dokument” |
| Eksporter innhold | Multi-select | Nei | Hvilke innholdstyper skal inkluderes (f.eks. H1, H2, Avsnitt). | Alle typer valgt |
| Inkluder metadata | Multi-select | Nei | Metadatafelter som skal inkluderes i utdata hvis tilgjengelig. | Produkt |
Tilgjengelige innholdstyper: H1, H2, H3, H4, H5, H6, Avsnitt
Metadata-alternativer: Forfatter, Produkt, BreadcrumbList, VideoObject, BlogPosting, FAQPage, WebSite, opengraph
Utdata
Komponenten produserer følgende utdata:
- Melding: Et meldingsobjekt som inneholder den omformede teksten og eventuell inkludert metadata.
Viktige egenskaper og nytte
- Fleksibel innholduttrekking: Presis kontroll over hvilke deler av dokumentene som trekkes ut (f.eks. kun hovedoverskrifter og avsnitt, eller alt innhold).
- Inkludering av metadata: Valgfri inkludering av rik metadata (f.eks. forfatter, produkt eller strukturert data) i utdataene, nyttig for videre kontekstualisering.
- Tokenbegrensning: Begrens utstørrelsen slik at den passer nedstrøms modellkrav ved å sette maks antall tokens.
- Egendefinert uttrekkingsstrategi:
- Sett sammen dokumenter, fyll fra første opp til token-grense: Prioriterer sekvensiell utfylling fra det første dokumentet.
- Inkluder lik størrelse fra hvert dokument: Balanserer innholdet fra flere dokumenter innenfor token-grensen.
- Smart seksjonshåndtering: Mulighet for å hoppe over footere eller starte fra den mest relevante seksjonen for spørringen din, noe som øker relevansen på uttrukket tekst.
Typiske bruksområder
- Forbehandling av kunnskapsbaser for KI-modeller (f.eks. før embedding eller indeksering).
- Oppsummere eller kondensere store dokumenter ved å kun trekke ut relevante seksjoner.
- Gi strukturert innhold til chatboter, søkemotorer eller andre språkbehandlingspipelines.
- Bygge hybride gjenfinningssystemer som kombinerer tekst med metadata for rikere kontekst.
Oppsummeringstabell
| Funksjonalitet | Beskrivelse |
|---|---|
| Inndatatyper | Liste over dokumenter |
| Utdata-type | Melding (Tekst + Metadata) |
| Innholdsgranularitet | Velg overskrifter/avsnitt som skal inkluderes |
| Metadata-alternativer | Velg flere metadatafelter å eksportere |
| Kontroll over utstørrelse | Sett maks antall tokens |
| Uttrekkingsstrategier | Sett sammen eller balanser på tvers av dokumenter |
| Seksjonsvalg | Start fra H1, fra peker, eller hopp over siste header |
Strategi
Bot-en kan gjennomsøke mange dokumenter for å lage tekstutdata. Strategi-innstillingen lar deg styre hvordan den benytter disse dokumentene smart innenfor token-grensen.
For øyeblikket finnes det to mulige strategier:
- Inkluder lik størrelse fra hvert dokument: Benytter alle funnede dokumenter likt.
- Sett sammen dokumenter, fyll fra første opp til token-grense: Kobler dokumentene sammen og prioriterer dem etter relevans til spørringen.
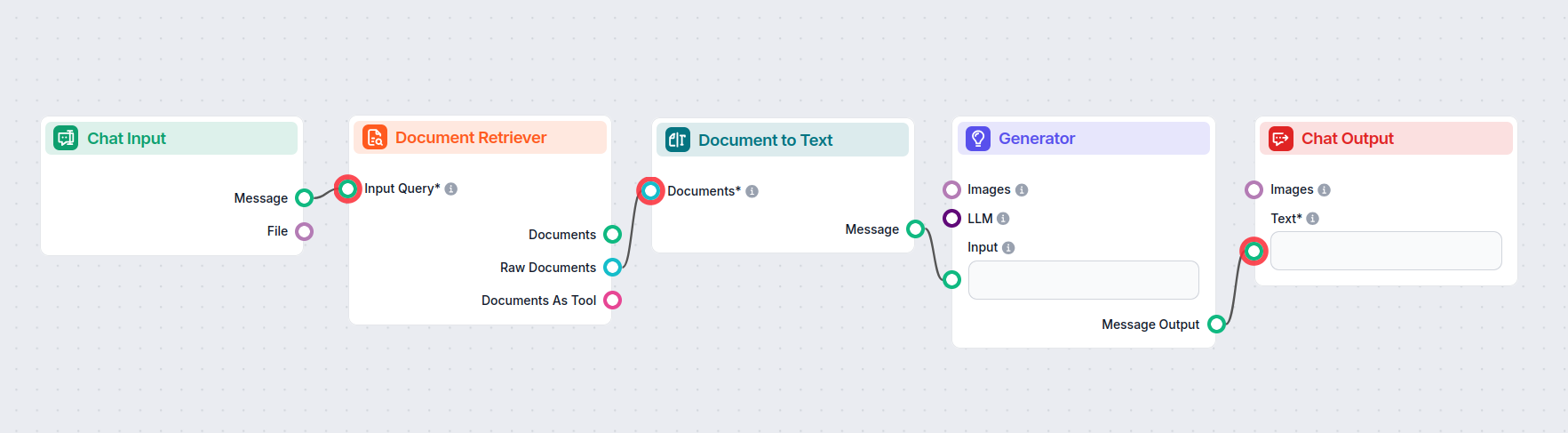
Slik kobler du Document to Text-komponenten til din flyt
Dette er en transformer-komponent, noe som betyr at den bygger bro mellom to utdata. Document to Text tar imot Dokumenter fra Retriever-komponentene:
- Document Retriever – henter kunnskap fra tilkoblede kunnskapskilder (sider, dokumenter osv.).
- URL Retriever – Lar deg spesifisere en URL som boten skal hente kunnskap fra.
- GoogleSearch – Gir boten mulighet til å søke på nettet etter kunnskap.
Kunnskapen konverteres til lesbar Markdown-tekst mens den passerer gjennom transformeren. Denne teksten kan deretter kobles til komponenter som krever tekstinput, som splittere, widgets eller utdata.
Her er et eksempel på en flyt der Document to Text-komponenten brukes til å bygge bro mellom Document Retrievers og AI Generator: