Dall-E
DALL-E er en serie tekst-til-bilde-modeller utviklet av OpenAI, som bruker dyp læring for å generere digitale bilder fra tekstbeskrivelser. Lær om historien, br...
2 min lesing
AI
Generative AI
+4
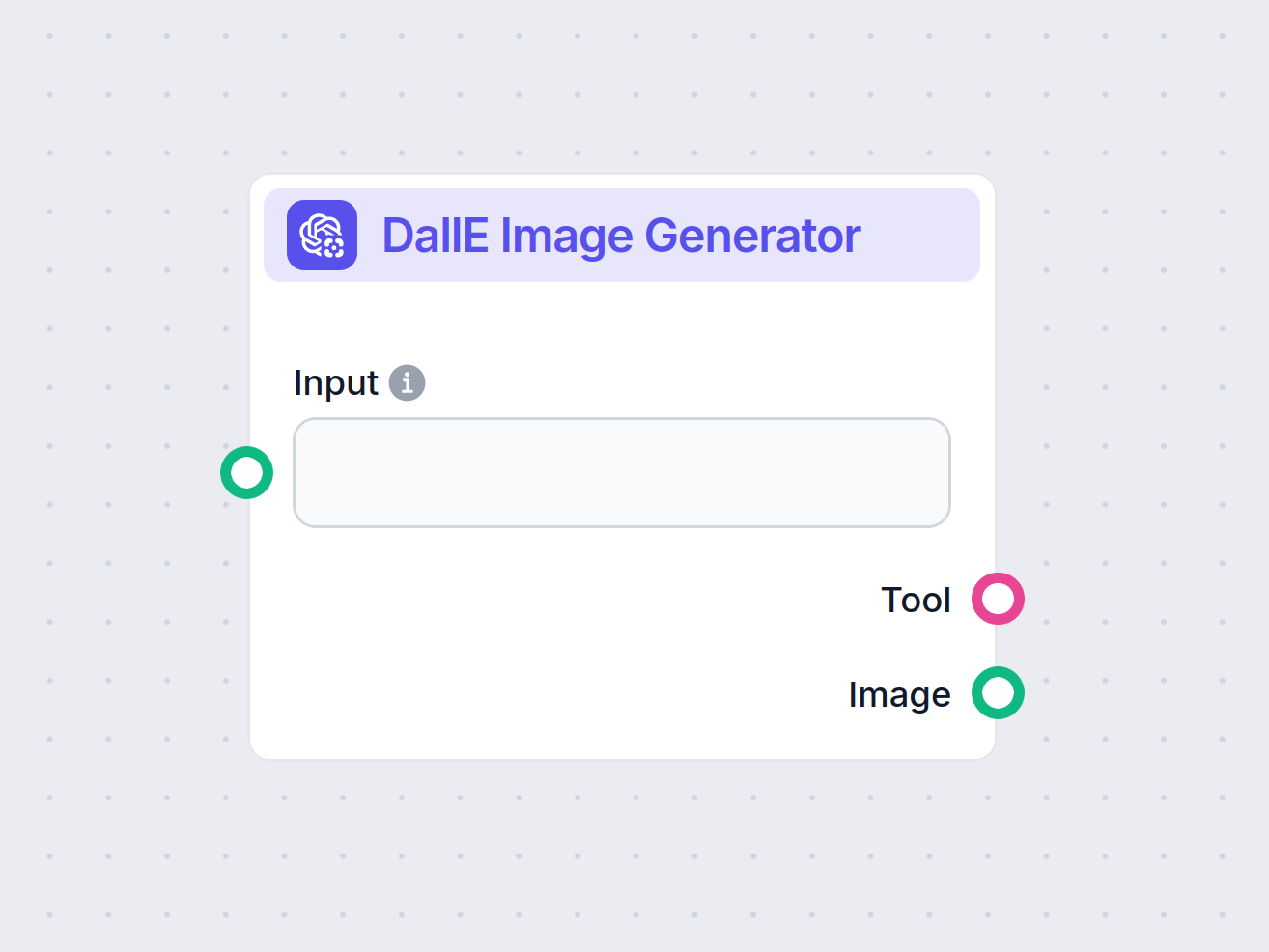
Gjør tekstprompter om til AI-genererte bilder med DallE-bildegeneratoren—tilpass modell, størrelse og kvalitet for unike, arbeidsflytklare visuelle elementer.
Komponentbeskrivelse
DallE-bildegeneratoren er en verktøykomponent utviklet for å generere bilder ved hjelp av OpenAIs DALL·E-modeller. Denne komponenten lar brukere skrive inn en tekstlig prompt og motta et generert bilde som gjenspeiler beskrivelsen, noe som gjør den spesielt nyttig for arbeidsflyter som krever visuell innholdsproduksjon fra tekstbeskrivelser.
Denne komponenten bruker OpenAIs DALL·E-modeller (DALL·E 2 og DALL·E 3) for å gjøre naturlige språkprompter om til bilder. Ved å spesifisere detaljer som bildestørrelse, kvalitet og DALL·E-modellversjon kan brukerne tilpasse resultatet til ulike bruksområder, fra prototyping av visuelle elementer til å lage ressurser til presentasjoner eller andre AI-drevne prosesser.
DallE-bildegeneratoren godtar flere tilpassbare inndata:
| Parameter | Type | Required | Description | Default | Options |
|---|---|---|---|---|---|
| input_value | String | No | The text prompt describing the desired image. | (empty) | - |
| image_size | Dropdown | Yes | Sets the resolution of the generated image. | 1024x1024 | 1024x1024, 1024×1792, 1792×1024, 512×512, 256×256 |
| model | Dropdown | Yes | Selects the DALL·E model version to use. | dall-e-3 | dall-e-2, dall-e-3 |
| quality | Dropdown | Yes | Controls the output image quality. | standard | standard, hd |
| tool_description | String (multiline) | No | Description of the tool, useful for agents integrating the tool in larger processes. | (empty) | - |
| tool_name | String | No | The tool’s reference name when used inside an agent or automated workflow. | (empty) | - |
| verbose | Boolean | No | If enabled, provides more detailed output for debugging or logging purposes. | false | true, false |
Denne komponenten gir to hovedutdata:
Verktøy (image_gen_tool):
Et innkapslet verktøysobjekt som kan integreres i større agentbaserte eller automatiserte arbeidsflyter. Nyttig for å kjede sammen flere verktøy eller for avansert prosesshåndtering.
Bilde (image_output):
Selve bildet som genereres fra prompten, returneres som et meldingsobjekt. Denne utdataen brukes vanligvis videre der det genererte bildet trengs (f.eks. visning, lagring eller videre behandling).
Ved å integrere denne komponenten i AI-arbeidsflytene dine kan du sømløst omgjøre tekstbeskrivelser til bilder av høy kvalitet uten manuell innsats. Fleksibiliteten til å tilpasse størrelse, kvalitet og modellvalg gjør den anvendelig i en rekke domener og for ulike behov. Enten det er til kreative, pedagogiske eller automatiseringsformål, kan dette verktøyet i stor grad forbedre arbeidsflytens evne til å produsere visuelt innhold på forespørsel.
Den genererer bilder fra tekstprompter ved å bruke OpenAIs DALL-E-modeller. Du kan justere parametere som bildestørrelse, kvalitet og modellversjon for å tilpasse til dine behov.
Du kan velge mellom DALL-E 2 og DALL-E 3 modeller for bildegenerering.
Du kan spesifisere bildestørrelse, velge kvalitet (standard eller HD), velge modell og legge inn beskrivende prompter for bildeoppretting.
Komponenten gir ut bilder som kan brukes av andre komponenter i arbeidsflyten din, og muliggjør sømløs integrering av AI-genererte visuelle elementer.
Nei, DallE-bildegeneratoren er designet for kodefrie arbeidsflyter, slik at du kan legge til AI-kunstgenerering med enkel konfigurasjon.
Begynn å integrere AI-drevet bildegenerering i flytene dine og forbedre prosjektene dine med visuelt innhold.
DALL-E er en serie tekst-til-bilde-modeller utviklet av OpenAI, som bruker dyp læring for å generere digitale bilder fra tekstbeskrivelser. Lær om historien, br...
Generer imponerende bilder fra tekstbeskrivelser med Flux Bildgenerator-komponenten i FlowHunt. Tilpass utdata med modellvalg, bildestørrelsesforhold og veiledn...
Utforsk Photomatic AI-bildegenerator-komponenten—gjør tekstbeskrivelser om til AI-genererte bilder av høy kvalitet med avanserte modeller, tilpassbare effekter ...