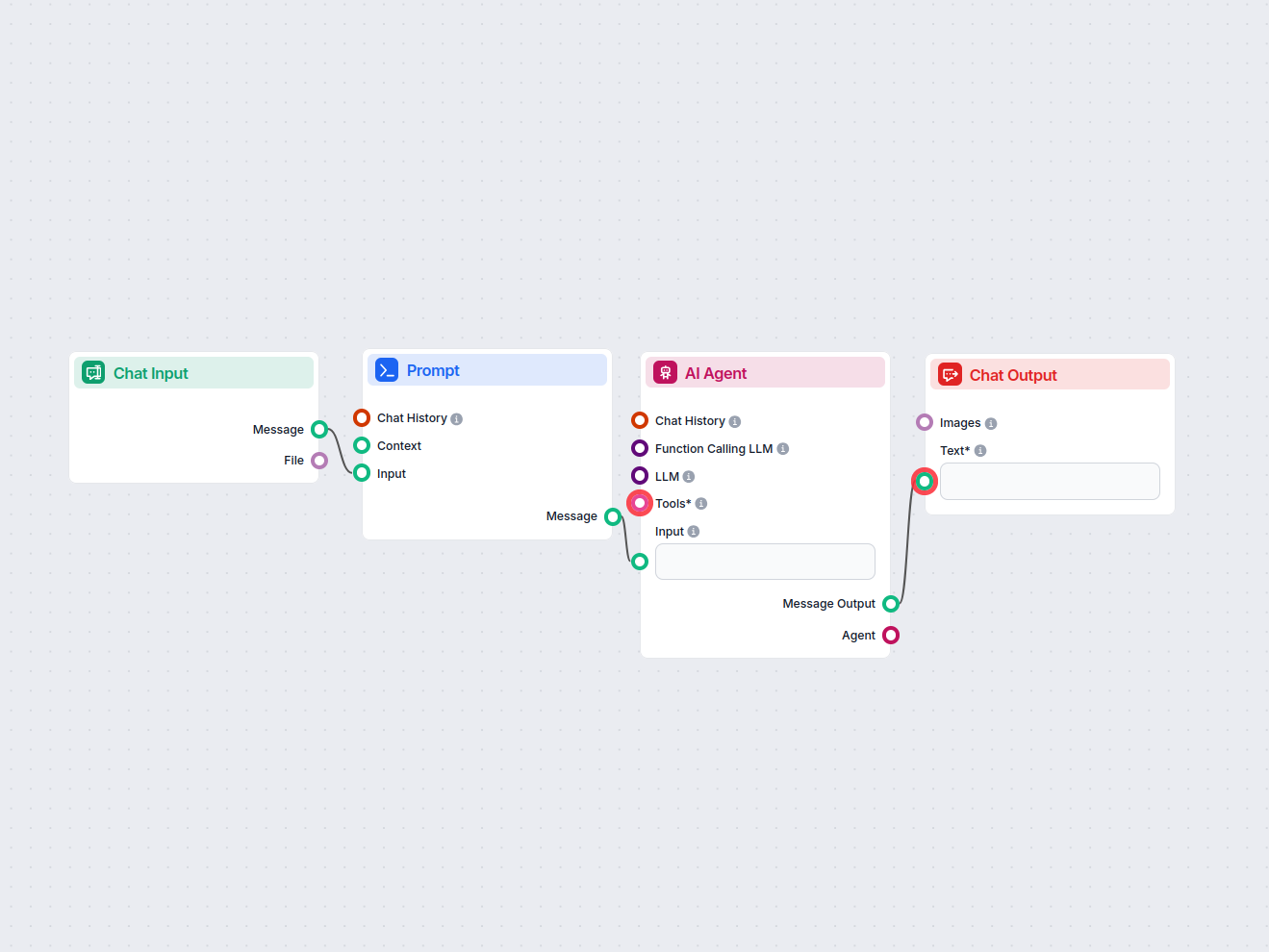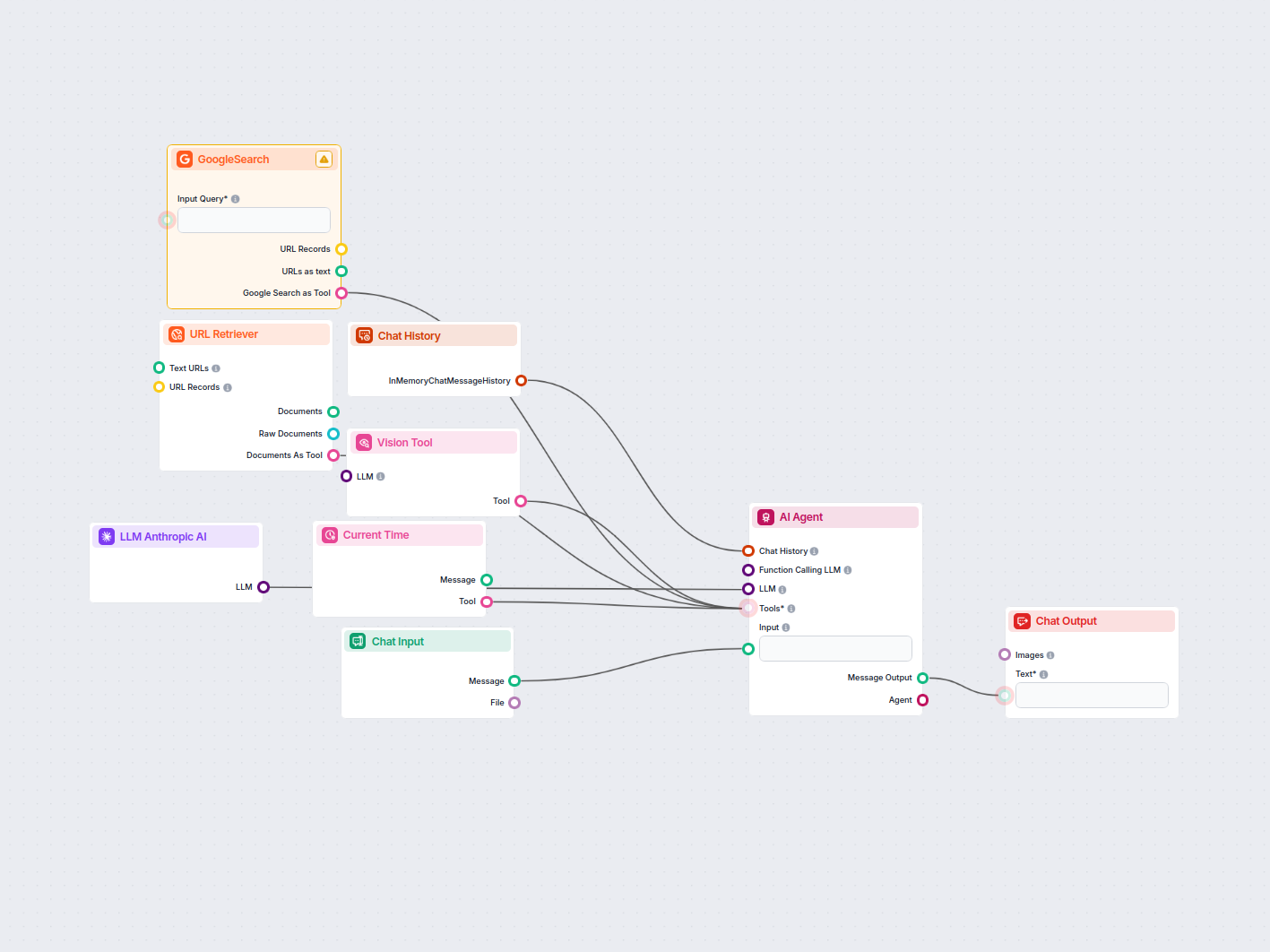
LinkedIn Annonse Konkurrent-Analysator
Denne arbeidsflyten automatiserer LinkedIn annonsemarkedsundersøkelser ved å identifisere toppkonkurrenter for et nøkkelord, analysere annonsetekst og bilder, o...
4 min lesing
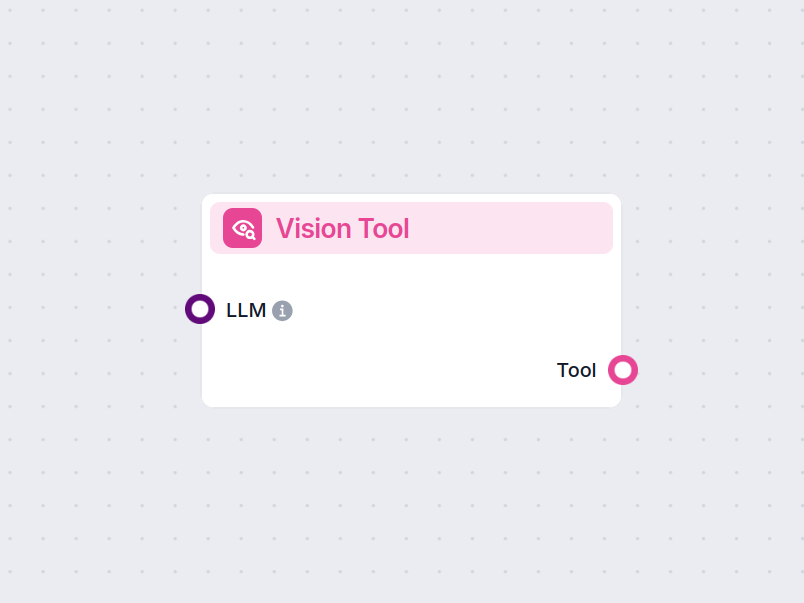
Vision-verktøyet lar AI analysere bilder, trekke ut verdifulle innsikter og svare på spørsmål basert på visuelt innhold i dine arbeidsflyter.
Komponentbeskrivelse
Vision-verktøyet er en komponent utviklet for å gjøre det mulig for AI-arbeidsflyter å behandle og analysere bilder som vedlegg. Det gir AI-agenter mulighet til å “se” bilder, trekke ut meningsfull informasjon og svare på spørsmål om visuelt innhold. Dette gjør det spesielt verdifullt i situasjoner der forståelse eller tolkning av bilder er essensielt, som dokumentbehandling, visuell QA, innholdsmoderering eller multimedieanalyse.
| Inputnavn | Type | Beskrivelse | Påkrevd | Avansert |
|---|---|---|---|---|
| LLM (modell) | BaseChatModel | Språkmodellen som brukes for å generere tekstsvar basert på bildeanalyse. | Nei | Nei |
| Verktøybeskrivelse | String (multi) | Beskrivelse som hjelper agenten å forstå hvordan dette verktøyet brukes. | Nei | Ja |
| Verktøynavn | String | Referansenavn for dette verktøyet i agentens arbeidsflyter. | Nei | Ja |
| Verbose | Boolean | Valg for å aktivere detaljert (verbose) utdata for feilsøking eller åpenhet. | Nei | Ja |
| Utdatanavn | Type | Beskrivelse |
|---|---|---|
| Verktøy | Tool | Den konfigurerte Vision-verktøy-instansen klar for integrasjon |
Vision-verktøyet gir ut en verktøy-instans som kan brukes av AI-agenter for å behandle bilder og produsere relevante svar.
Ved å innlemme Vision-verktøyet i dine AI-prosesser får du mulighet til å arbeide med visuelle data, ikke bare tekst. Det bygger bro mellom språk- og bildeforståelse, og åpner for rikere, mer interaktive og intelligente applikasjoner.
Oppsummering av fordeler:
Ved å bruke Vision-verktøyet kan AI-arbeidsflytene dine bli mer kapable og allsidige, og legge til rette for neste generasjons applikasjoner som utnytter både tekst- og bildeintelligens.
For å hjelpe deg med å komme raskt i gang, har vi forberedt flere eksempel-flow-maler som demonstrerer hvordan du bruker Vision-verktøy-komponenten effektivt. Disse malene viser forskjellige brukstilfeller og beste praksis, noe som gjør det lettere for deg å forstå og implementere komponenten i dine egne prosjekter.
Denne arbeidsflyten automatiserer LinkedIn annonsemarkedsundersøkelser ved å identifisere toppkonkurrenter for et nøkkelord, analysere annonsetekst og bilder, o...
Vision-verktøyet gjør det mulig for din flyt å behandle bilder, trekke ut meningsfull informasjon og svare på spørsmål om bildeinnhold ved hjelp av AI.
Ja, Vision-verktøyet er designet for å tolke bilder i konteksten av arbeidsflyten din, slik at AI-agenter kan kombinere visuell og tekstlig informasjon for mer intelligent automatisering.
Typiske bruksområder inkluderer dokumentbehandling, automatisert visuell inspeksjon, utvinning av data fra bilder og forbedring av chatbot-samtaler med bildeforståelse.
Absolutt. Vision-verktøyet er en plug-and-play-komponent i FlowHunt som enkelt kan kobles til andre arbeidsflytelementer som krever bildeanalyse.
Du kan velge eller konfigurere en AI-modell, men FlowHunt tilbyr fornuftige standardinnstillinger for rask oppstart og eksperimentering.
Forbedre arbeidsflytene dine med AI-drevet bildeforståelse—prøv Vision-verktøyet i FlowHunt i dag.
Finn ut hva bildetolkning er innen AI. Hva brukes det til, hvilke trender finnes, og hvordan skiller det seg fra lignende teknologier.
Denne arbeidsflyten tar imot brukerinnsendte bildetekster og forbedrer dem ved hjelp av AI-best practices, slik at tekstene blir detaljerte, beskrivende og opti...
Utforsk Photomatic AI-bildegenerator-komponenten—gjør tekstbeskrivelser om til AI-genererte bilder av høy kvalitet med avanserte modeller, tilpassbare effekter ...