
Innsiktsmotor
Oppdag hva en innsiktsmotor er—en avansert, AI-drevet plattform som forbedrer datasøk og analyse ved å forstå kontekst og hensikt. Lær hvordan innsiktsmotorer i...
10 min lesing
AI
Insight Engine
+5

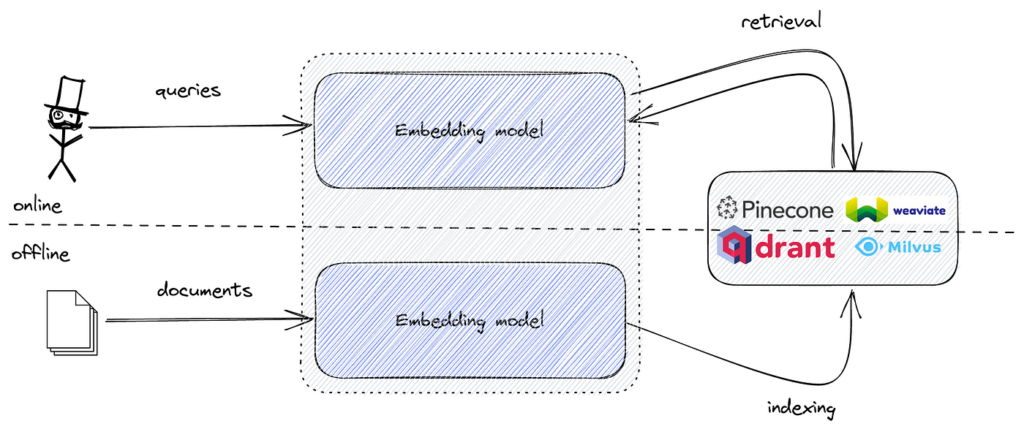
AI-søk utnytter maskinlæring og vektorinnbygginger for å forstå søkehensikt og kontekst, og leverer svært relevante resultater utover eksakte nøkkelord.
AI-søk bruker maskinlæring for å forstå konteksten og hensikten bak søkespørsmål, og omformer dem til numeriske vektorer for mer presise resultater. I motsetning til tradisjonelle nøkkelordssøk tolker AI-søk semantiske relasjoner, noe som gjør det effektivt for ulike datatyper og språk.
AI-søk, ofte omtalt som semantisk eller vektorsøk, er en søkemetodikk som benytter maskinlæringsmodeller for å forstå hensikt og kontekstuell betydning bak søkespørsmål. I motsetning til tradisjonelle nøkkelordbaserte søk omgjør AI-søk data og spørsmål til numeriske representasjoner kjent som vektorer eller innbygginger. Dette gjør at søkemotoren kan forstå semantiske relasjoner mellom ulike datastykker, og gir mer relevante og presise resultater selv når eksakte nøkkelord ikke er til stede.
AI-søk representerer en vesentlig utvikling innen søketeknologier. Tradisjonelle søkemotorer er sterkt avhengige av nøkkelordsmatching, der tilstedeværelse av bestemte termer i både spørsmål og dokumenter avgjør relevansen. AI-søk benytter derimot maskinlæringsmodeller for å få tak i den underliggende konteksten og betydningen av spørsmål og data.
Ved å konvertere tekst, bilder, lyd og andre ustrukturerte data til høydimensjonale vektorer kan AI-søk måle likheten mellom ulike innholdselementer. Denne tilnærmingen gjør det mulig for søkemotoren å levere resultater som er kontekstuelt relevante, selv om de ikke inneholder de eksakte nøkkelordene som brukes i søkespørsmålet.
Nøkkelkomponenter:
Kjernen i AI-søk er konseptet med vektorinnbygginger. Vektorinnbygginger er numeriske representasjoner av data som fanger den semantiske betydningen av tekst, bilder eller andre datatyper. Disse innbyggingene plasserer lignende data nær hverandre i et multidimensjonalt vektorrom.
Slik fungerer det:
Eksempel:
Tradisjonelle nøkkelordbaserte søkemotorer fungerer ved å matche termer i søkespørsmålet med dokumenter som inneholder disse termene. De bruker teknikker som inverterte indekser og termfrekvens for å rangere resultater.
Begrensninger med nøkkelordbasert søk:
Fordeler med AI-søk:
| Aspekt | Nøkkelordbasert søk | AI-søk (Semantisk/Vektor) |
|---|---|---|
| Matching | Eksakte nøkkelordstreff | Semantisk likhet |
| Kontekstbevissthet | Begrenset | Høy |
| Håndtering av synonymer | Krever manuelle synonymlister | Automatisk via innbygginger |
| Feilstavinger | Kan feile uten fuzzy-søk | Mer tolerant grunnet semantisk kontekst |
| Forståelse av hensikt | Minimal | Betydelig |
Semantisk søk er en kjerneapplikasjon av AI-søk som fokuserer på å forstå brukerens hensikt og den kontekstuelle betydningen av spørsmål.
Prosess:
Nøkkelmetoder:
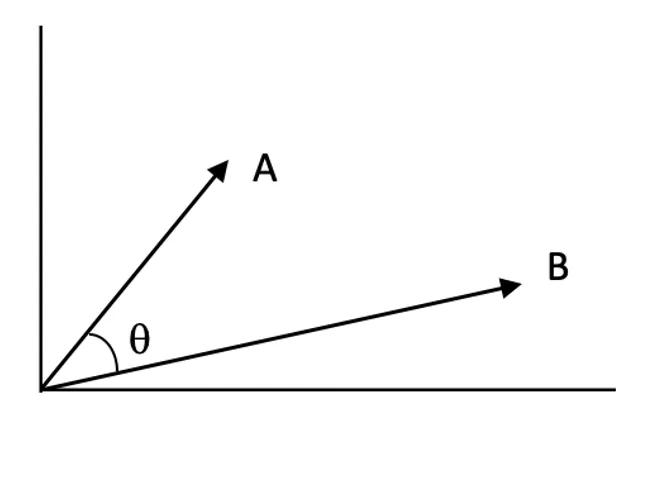
Likhetspoeng:
Likhetspoeng kvantifiserer hvor nært relatert to vektorer er i vektorrommet. Høyere poeng indikerer høyere relevans mellom spørsmål og et dokument.
Approksimativ nærmeste nabo (ANN)-algoritmer:
Å finne eksakte nærmeste naboer i høydimensjonale rom er ressurskrevende. ANN-algoritmer gir effektive tilnærminger.
AI-søk åpner for et bredt spekter av applikasjoner i ulike bransjer, takket være evnen til å forstå og tolke data utover enkel nøkkelordmatching.
Beskrivelse: Semantisk søk forbedrer brukeropplevelsen ved å tolke hensikten bak spørsmål og levere kontekstuelt relevante resultater.
Eksempler:
Beskrivelse: Ved å forstå brukerpreferanser og -adferd kan AI-søk gi personlige innholds- eller produktanbefalinger.
Eksempler:
Beskrivelse: AI-søk gjør det mulig for systemer å forstå og besvare brukerhenvendelser med presis informasjon hentet fra dokumenter.
Eksempler:
Beskrivelse: AI-søk kan indeksere og søke gjennom ustrukturerte datatyper som bilder, lyd og video ved å konvertere dem til innbygginger.
Eksempler:
Å integrere AI-søk i AI-automatisering og chatboter forbedrer deres evner betraktelig.
Fordeler:
Implementeringstrinn:
Bruksområde-eksempel:
Selv om AI-søk gir mange fordeler, er det utfordringer å ta hensyn til:
Tiltaksstrategier:
Semantisk og vektorsøk i AI har kommet frem som kraftige alternativer til tradisjonelle nøkkelordbaserte og fuzzy-søk, og øker relevansen og presisjonen i søkeresultater ved å forstå kontekst og betydning bak spørsmål.
Når man implementerer semantisk søk, blir tekstdata konvertert til vektorinnbygginger som fanger den semantiske betydningen av teksten. Disse innbyggingene er høydimensjonale numeriske representasjoner. For å søke effektivt gjennom disse innbyggingene og finne de mest like til en spørsmålinnbygging, trenger vi et verktøy optimalisert for likhetssøk i høydimensjonale rom.
FAISS tilbyr nødvendige algoritmer og datastrukturer for å utføre denne oppgaven effektivt. Ved å kombinere semantiske innbygginger med FAISS kan vi lage en kraftig semantisk søkemotor som kan håndtere store datasett med lav ventetid.
Å implementere semantisk søk med FAISS i Python innebærer flere trinn:
La oss se nærmere på hvert trinn.
Forbered datasettet ditt (f.eks. artikler, supportsaker, produktbeskrivelser).
Eksempel:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Rens og formater tekstdata etter behov.
Konverter tekstdata til vektorinnbygginger med forhåndstrente Transformer-modeller fra biblioteker som Hugging Face (transformers eller sentence-transformers).
Eksempel:
from sentence_transformers import SentenceTransformer
import numpy as np
# Last inn en forhåndstrent modell
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Generer innbygginger for alle dokumenter
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 som kreves av FAISS.Lag en FAISS-indeks for å lagre innbyggingene og muliggjøre effektivt likhetssøk.
Eksempel:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 utfører brute-force-søk med L2 (euklidisk) avstand.Konverter brukerens spørsmål til en innbygging og finn nærmeste naboer.
Eksempel:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Bruk indeksene for å vise de mest relevante dokumentene.
Eksempel:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Forventet utdata:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS tilbyr flere typer indekser:
Eksempel på Inverted File Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Normalisering og indre produkt-søk:
Å bruke cosinuslikhet kan være mer effektivt for tekstdata
AI-søk er en moderne søkemetodikk som bruker maskinlæring og vektorinnbygginger for å forstå hensikten og den kontekstuelle betydningen av spørsmål, og gir mer presise og relevante resultater enn tradisjonelle nøkkelordbaserte søk.
I motsetning til nøkkelordbasert søk, som er avhengig av eksakte treff, tolker AI-søk de semantiske relasjonene og intensjonen bak spørsmål, noe som gjør det effektivt for naturlig språk og tvetydige innspill.
Vektorinnbygginger er numeriske representasjoner av tekst, bilder eller andre datatyper som fanger deres semantiske betydning, og muliggjør at søkemotoren kan måle likhet og kontekst mellom ulike datastykker.
AI-søk driver semantisk søk i e-handel, personlige anbefalinger i strømmetjenester, spørsmålsbesvarende systemer i kundestøtte, ustrukturert datanavigering og dokumentgjenfinning i forskning og virksomhet.
Populære verktøy inkluderer FAISS for effektiv vektorsimilitetssøk, og vektordatabaser som Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch og Pgvector for skalerbar lagring og gjenfinning av innbygginger.
Ved å integrere AI-søk kan chatboter og automatiseringssystemer forstå brukerhenvendelser dypere, hente kontekstuelt relevante svar og levere dynamiske, personlige svar.
Utfordringer inkluderer høye krav til datakraft, kompleksitet i modellfortolkning, behov for høykvalitetsdata, samt å sikre personvern og sikkerhet ved håndtering av sensitiv informasjon.
FAISS er et åpen kildekode-bibliotek for effektiv søk etter likheter på høydimensjonale vektorinnbygginger, og brukes mye for å bygge semantiske søkemotorer som kan håndtere store datasett.
Oppdag hvordan AI-drevet semantisk søk kan forvandle din informasjonsgjenfinning, chatboter og automatiseringsarbeidsflyter.
Oppdag hva en innsiktsmotor er—en avansert, AI-drevet plattform som forbedrer datasøk og analyse ved å forstå kontekst og hensikt. Lær hvordan innsiktsmotorer i...
Forbedret dokumentsøk med NLP integrerer avanserte teknikker for naturlig språkbehandling i dokumentsøkesystemer, noe som forbedrer nøyaktighet, relevans og eff...
Oppdag hvordan AI forvandler SEO ved å automatisere søkeordanalyse, innholdsoptimalisering og brukerinvolvering. Utforsk nøkkelstrategier, verktøy og fremtidige...
