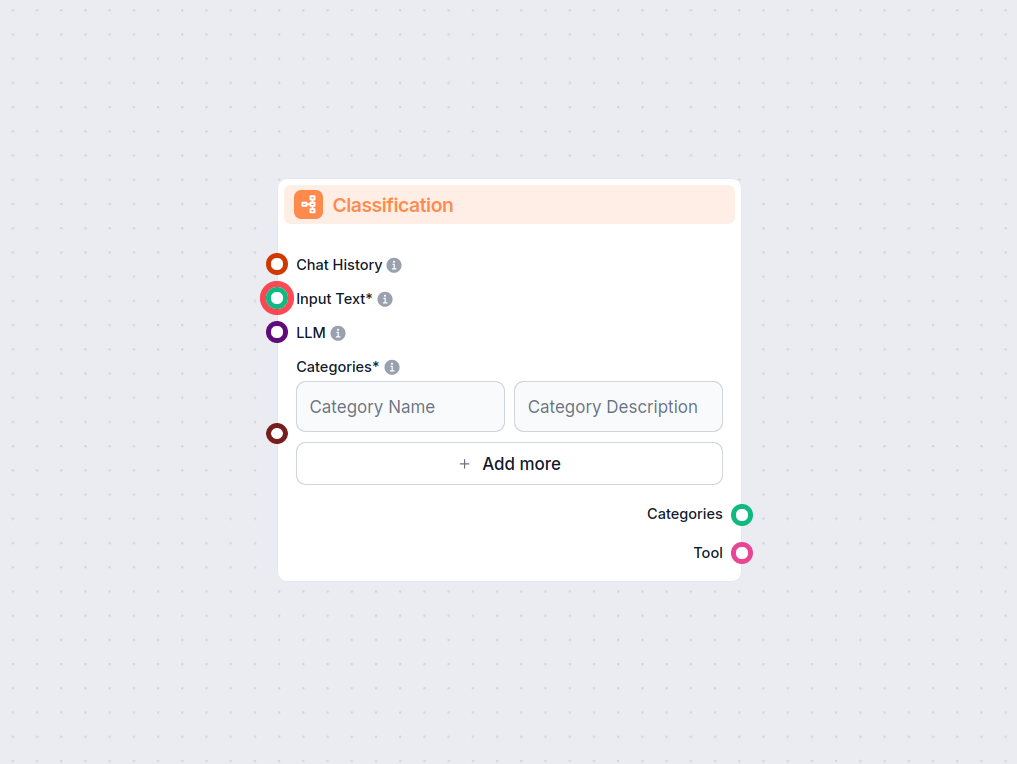
Tekstklassifisering
Lås opp automatisert tekstkategorisering i arbeidsflytene dine med Tekstklassifiseringskomponenten for FlowHunt. Klassifiser enkelt innkommet tekst i brukerdefi...
2 min lesing
AI
Classification
+3
En AI-klassifiserer kategoriserer data i forhåndsdefinerte klasser ved bruk av maskinlæring, og muliggjør automatisert beslutningstaking i applikasjoner som spambekjempelse, medisinsk diagnose og bildedeteksjon.
En AI-klassifiserer er en type maskinlæringsalgoritme som tildeler en klasselapp til inndata. I hovedsak kategoriserer den data i forhåndsdefinerte klasser basert på mønstre lært fra historiske data. AI-klassifiserere er grunnleggende verktøy innen kunstig intelligens og datavitenskap, og gjør det mulig for systemer å ta informerte beslutninger ved å tolke og organisere komplekse datasett.
Klassifisering er en overvåket læringsprosess hvor en algoritme lærer av merket treningsdata for å forutsi klasselappene til ukjente data. Målet er å lage en modell som nøyaktig kan tilordne nye observasjoner til en av de forhåndsdefinerte kategoriene. Denne prosessen er avgjørende i ulike applikasjoner, fra spambekjempelse i e-post til diagnostisering av medisinske tilstander.
Klassifiseringsoppgaver kan kategoriseres basert på antall og natur av klasselappene.
Binær klassifisering innebærer å sortere data inn i én av to klasser. Dette er den enkleste formen for klassifisering, og håndterer ja/nei- eller sann/usann-scenarier.
Eksempler:
Multiklasseklassifisering håndterer scenarier der data kan falle inn i mer enn to kategorier.
Eksempler:
I multietikettklassifisering kan hvert datapunkt tilhøre flere klasser samtidig.
Eksempler:
Ubalansert klassifisering oppstår når klassefordelingen er skjev, og én klasse er betydelig mer tallrik enn de andre.
Eksempler:
Flere algoritmer kan brukes for å bygge AI-klassifiserere, hver med sin unike tilnærming og styrker.
Til tross for navnet brukes logistisk regresjon til klassifiseringsoppgaver, særlig binær klassifisering.
Beslutningstrær bruker en trestruktur av beslutninger, der hver intern node representerer en test på en egenskap, hver gren et utfall, og hvert blad en klasselapp.
SVM-er er kraftige for både lineær og ikke-lineær klassifisering, og effektive i høydimensjonale rom.
Nevrale nettverk er inspirert av den menneskelige hjernen og er dyktige til å fange opp komplekse mønstre i data.
Tilfeldige skoger er ensembler av beslutningstrær, som forbedrer prediksjonsnøyaktighet ved å redusere overtilpasning.
Å trene en AI-klassifiserer involverer flere trinn for å sikre at den kan generalisere godt til nye, ukjente data.
Kvalitetsdata er avgjørende. Dataene må være:
Under treningen lærer klassifisereren mønstre i dataene.
Etter trening vurderes klassifisererens ytelse med metrikker som:
AI-klassifiserere er integrert i ulike bransjer, automatiserer beslutningsprosesser og øker effektiviteten.
Finansinstitusjoner bruker klassifiserere for å identifisere svindeltransaksjoner.
Klassifiserere hjelper bedrifter å målrette markedsføringsstrategier.
I bildedeteksjon identifiserer klassifiserere objekter, personer eller mønstre i bilder.
Klassifiserere prosesserer og analyserer store mengder naturlig språk-data.
Klassifiserere gjør det mulig for chatbots å forstå og svare riktig på brukerhenvendelser.
Klassifisering er et kjerneproblem innen maskinlæring, og danner grunnlaget for mange avanserte algoritmer og systemer.
En AI-klassifiserer er et grunnleggende verktøy innen maskinlæring og kunstig intelligens, og gjør det mulig for systemer å kategorisere og tolke komplekse data. Ved å forstå hvordan klassifiserere fungerer, typene klassifiseringsproblemer og algoritmene som brukes, kan organisasjoner utnytte disse verktøyene til å automatisere prosesser, ta informerte beslutninger og forbedre brukeropplevelser.
Fra å oppdage svindel til å drive intelligente chatbots, er klassifiserere integrert i moderne AI-applikasjoner. Deres evne til å lære av data og forbedre seg over tid gjør dem uvurderlige i en verden som i økende grad styres av informasjon og automatisering.
Forskning på AI-klassifiserere
AI-klassifiserere er en viktig komponent innen kunstig intelligens, ansvarlig for å kategorisere data i forhåndsdefinerte klasser basert på lærte mønstre. Nyere forskning har undersøkt ulike aspekter ved AI-klassifiserere, inkludert deres evner, begrensninger og etiske implikasjoner.
“Weak AI” is Likely to Never Become “Strong AI”, So What is its Greatest Value for us? av Bin Liu (2021).
Denne artikkelen diskuterer forskjellen mellom «svak AI» og «sterk AI», og understreker at selv om AI har utmerket seg i spesifikke oppgaver som bildedeteksjon og spill, er det fortsatt langt fra generell intelligens. Artikkelen utforsker også verdien av svak AI i nåværende form. Les mer
The Switch, the Ladder, and the Matrix: Models for Classifying AI Systems av Jakob Mokander m.fl. (2024).
Forfatterne undersøker ulike modeller for å klassifisere AI-systemer for å bygge bro mellom etiske prinsipper og praksis. Artikkelen kategoriserer AI-systemer ved hjelp av tre modeller: The Switch, The Ladder og The Matrix, hver med sine styrker og svakheter, og gir et rammeverk for bedre AI-styring. Les mer
Cognitive Anthropomorphism of AI: How Humans and Computers Classify Images av Shane T. Mueller (2020).
Denne studien utforsker forskjellene mellom menneskelig og AI-bildedeteksjon, med vekt på kognitiv antropomorfisme hvor mennesker forventer at AI skal etterligne menneskelig intelligens. Artikkelen foreslår strategier som forklarbar AI for å forbedre samspillet mellom mennesker og AI ved å tilpasse AI-ens evner til menneskelige kognitive prosesser. Les mer
An Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers av Hui Xie m.fl. (2019).
Denne forskningen presenterer en hypotese om komprimeringsegenskapene til AI-klassifiserere, og gir teoretiske innblikk i deres sårbarhet for adversariale angrep. Å forstå disse sårbarhetene er avgjørende for å utvikle mer robuste AI-systemer. Les mer
En AI-klassifiserer er en maskinlæringsalgoritme som tildeler klasselapper til inndata, og kategoriserer dem i forhåndsdefinerte klasser basert på mønstre lært fra historiske data.
Klassifiseringsproblemer inkluderer binær klassifisering (to klasser), multiklasseklassifisering (mer enn to klasser), multietikettklassifisering (flere etiketter per datapunkt), og ubalansert klassifisering (ujevn klassefordeling).
Populære klassifiseringsalgoritmer inkluderer logistisk regresjon, beslutningstrær, støttevektormaskiner (SVM), nevrale nettverk og tilfeldige skoger.
AI-klassifiserere brukes til spambekjempelse, medisinsk diagnose, svindeldeteksjon, bildedeteksjon, kundesegmentering, sentimentanalyse, samt i chatbots og AI-assistenter.
AI-klassifiserere evalueres med metrikker som nøyaktighet, presisjon, tilbakekalling, F1-score og forvekslingsmatrise for å vurdere ytelsen på ukjente data.
Smarte Chatbots og AI-verktøy samlet på ett sted. Koble sammen intuitive blokker for å gjøre dine ideer om til automatiserte flyter.
Lås opp automatisert tekstkategorisering i arbeidsflytene dine med Tekstklassifiseringskomponenten for FlowHunt. Klassifiser enkelt innkommet tekst i brukerdefi...
Lær det grunnleggende om AI-intentklassifisering, teknikker, virkelige applikasjoner, utfordringer og fremtidstrender innen forbedring av menneske-maskin-intera...
Oppdag den essensielle rollen AI Intentklassifisering har for å forbedre brukerinteraksjoner med teknologi, styrke kundestøtte og effektivisere forretningsdrift...

